

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Симметричные мультипроцессоры.
Симметричный мультипроцессор (относится к классу SMP-систем) состоит из нескольких десятков процессоров, причем все процессоры разделяют общую память и объединены коммуникационной системой.
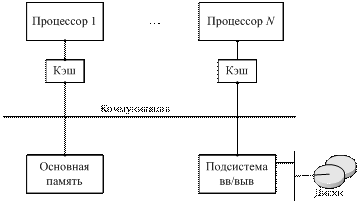 Существуют варианты SMP-архитектур с одной или несколькими системными шинами (например, Cray 6400 имел 4 системные шины). Также существуют SMP-архитектуры со специальными коммутаторами для связи процессоров, памяти и подсистемы ввода-вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеются свои уровни кеш-памяти. Достаточный объем кеша и сравнительно небольшое количество процессоров позволяет удовлетворять обращения к основной памяти. Это легло в основу названия таких архитектур - UMA-архитектуры.
Существуют варианты SMP-архитектур с одной или несколькими системными шинами (например, Cray 6400 имел 4 системные шины). Также существуют SMP-архитектуры со специальными коммутаторами для связи процессоров, памяти и подсистемы ввода-вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеются свои уровни кеш-памяти. Достаточный объем кеша и сравнительно небольшое количество процессоров позволяет удовлетворять обращения к основной памяти. Это легло в основу названия таких архитектур - UMA-архитектуры.
UMA (Uniform Memory Access, однородный доступ к памяти).
В UMA-архитектурах имеется единственная ОС, а ПО работает с единым адресным пространством. При этом возникает сложная проблема сохранения когерентности данных (согласованного извлечения содержимого кешей и основной памяти). Если модифицируется одна из копий данных, остальные копии должны либо также модифицироваться, било объявляться недостоверными. Отсюда – 2 альтернативных подхода к поддержанию когерентности разделяемых данных:
1) запись с обновлением данных
2) запись с аннулированием данных
В SMP-системах обычно реализуется шинный протокол наблюдения. Происходит прослушивание шины всеми процессорами с целью обнаружения операций записи в те ячейки памяти, копии содержимого которых содержатся в кеше данного процессора. Производительность систем с общей памятью, в т. ч. SMP, зависит от принятой модели согласованности памяти, определяющей, в каком порядке процессоры наблюдают последовательность операций записи-чтения.
Передача данных между кешами различных процессоров в SMP-системах выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера. Поэтому SMP-система хорошо масштабируется с ростом производительности при обработке большого числа коротких транзакций (например, банковские операции).
Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Однако, если следовать строгой модели согласованности, когда каждая операция записи возвращает последнее записанное значение, то происходит неизбежное падение производительности. Главная сложность построения SMP-систем - сильная связанность процессоров и наличие единой ОС, разделяемой всеми процессорами.
5. Системы с распределенной и разделяемой памятью, массово-параллельные системы - общая характеристика, схема построения, особенности каждой из систем, области применения.
DSM-системы (Distributed Shared Memory) – системы с распределенной и разделяемой памятью; память таких узлов разделена физически, но адресуется в рамках единого адресного пространства. DSM-системы могут быть реализованы различными способами. Общим для разных реализаций является тот факт, что узел может состоять из нескольких процессоров и иметь SMP-архитектуру. Также в DSM-системах поддерживается общее адресное пространство, но при этом память является распределенной по узлам и время доступа к памяти зависит от месторасположения данных, поэтому некоторые DSM-системы получили название NUMA.
NUMA – Non-Uniform memory Acess (Architecture) – Неоднородный доступ (архитектура) к памяти.
Частный случай NUMA–архитектуры - cc-NUMA.
cc-NUMA – Cache Coherent NUMA, архитектура NUMA с кеш-когерентным доступом.
Архитектура cc-NUMA:

Механизм работы кеша каждого узла увязан с доступом к локальной памяти каждого удаленного узла.
Существует справочная память, в которой содержится информация о том, в каких именно кешах находится нужный блок данных; например, узел 1 обращается к ячейке памяти с адресом А основной памяти, не являющейся локальным адресом узла 1. Тогда справочник узла 1 анализирует информацию (адрес А) и определяет, что данные по адресу А находятся в узле N. В этом случае этот справочник отправляет адрес А в справочник узла N. Узел N выбирает информацию оп адресу А.
В отличие от шинного протокола наблюдения, где при записи нового значения в кеш сообщение о модификации передается во все узлы, справочник распознает адрес и обращается только к тому узлу, где содержится данный адрес.
Преимущество арх-ры: простота.
Недостаток арх-ры: объем аппаратной реализации (пропорционален основной памяти системы).
Иерархичность доступа к памяти в NUMA-архитектурах сдерживает рост количества процессоров. Как правило, в современных NUMA-системах количество процессорных узлов не превышает 64, а число процессоров – 128.
Массово-параллельные системы (МПС).
Отличительной особенностью массово-параллельных систем является большое число процессорных узлов. Узлы обычно состоят из 1 или нескольких процессоров, локальной памяти и нескольких устройство ввода-вывода.
В массово-параллельных системах реализуется архитектура без разделения ресурсов. В каждом узле работает своя копия ОС, а узлы объединяются коммуникационной системой.
Если узел управляется своей собственной ОС и имеет уникальное адресное пространство памяти, то не потребуется никаких аппаратных средств для обеспечения когерентности (согласованности).
Когерентность в случае МПС обеспечивается программными средствами на основе техники обмена сообщениями. Также МПС можно отнести к мультикомпьютерам.
В МПС с разделяемой распределенной памятью возможна как аппаратная, так и программная поддержка (???). Такую разновидность МПС можно отнести к классу NUMA.
6. Структура, достоинства и недостатки UMA-, NUMA - и ccNUMA-систем
UMA (заход на UMA через SMP)
Симметричный мультипроцессор (SMP-система) состоит из нескольких десятков процессоров, причем все процессоры разделяют общую память и объединены коммуникационной системой.
Существуют варианты SMP-архитектур с одной или несколькими системными шинами (например, Cray 6400 имел 4 системные шины). Также существуют SMP-архитектуры со специальными коммутаторами для связи процессоров, памяти и подсистемы ввода-вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеются свои уровни кеш-памяти. Достаточный объем кеша и сравнительно небольшое количество процессоров позволяет удовлетворять обращения к основной памяти. Это легло в основу названия таких архитектура: UMA-архитектуры.
UMA (Uniform Memory Access, однородный доступ к памяти).
В UMA-архитектурах имеется единственная ОС, а ПО работает с единым адресным пространством. При этом возникает сложная проблема сохранения когерентности данных (согласованного извлечения содержимого кешей и основной памяти). Если модифицируется одна из копий данных, остальные копии должны либо также модифицироваться, било объявляться недостоверными. Отсюда – 2 альтернативных подхода к поддержанию когерентности разделяемых данных:
1) запись с обновлением данных
2) запись с аннулированием данных
В SMP-системах обычно реализуется шинный протокол наблюдения. Происходит прослушивание шины всеми процессорами с целью обнаружения операций записи в те ячейки памяти, копии содержимого которых содержатся в кеше данного процессора. Производительность систем с общей памятью, в т. ч. SMP, зависит от принятой модели согласованности памяти, определяющей, в каком порядке процессоры наблюдают последовательность операций записи-чтения.
Передача данных между кешами различных процессоров в SMP-системах выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера. Поэтому SMP-система хорошо масштабируется с ростом производительности при обработке большого числа коротких транзакций (например, банковские операции).
Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Однако, если следовать строгой модели согласованности, когда каждая операция записи возвращает последнее записанное значение, то происходит неизбежное падение производительности. Главная сложность построения SMP-систем - сильная связанность процессоров и наличие единой ОС, разделяемой всеми процессорами.
NUMA (заход через DSM-системы)
DSM-системы (Distributed Shared Memory) – системы с распределенной и разделяемой памятью; память таких узлов разделена физически, но адресуется в рамках единого адресного пространства. DSM-системы могут быть реализованы различными способами. Общим для разных реализаций является тот факт, что узел может состоять из нескольких процессоров и иметь SMP-архитектуру. Также в DSM-системах поддерживается общее адресное пространство, но при этом память является распределенной по узлам и время доступа к памяти зависит от месторасположения данных, поэтому некоторые DSM-системы получили название NUMA.
NUMA – Non-Uniform memory Acess (Architecture) – Неоднородный доступ (архитектура) к памяти.
cc-NUMA
Частным случаем NUMA–архитектуры является cc-NUMA
cc-NUMA – Cache Coherent NUMA, архитектура NUMA с кеш-когерентным доступом.
Архитектура cc-NUMA:
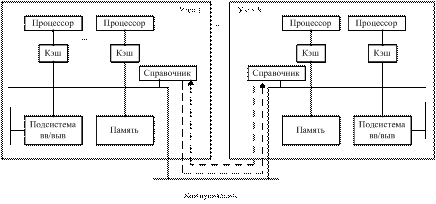
Механизм работы кеша каждого узла увязан с доступом к локальной памяти каждого удаленного узла.
Существует справочная память, в которой содержится информация о том, в каких именно кешах находится нужный блок данных; например, узел 1 обращается к ячейке памяти с адресом А основной памяти, не являющейся локальным адресом узла 1. Тогда справочник узла 1 анализирует информацию (адрес А) и определяет, что данные по адресу А находятся в узле N. В этом случае этот справочник отправляет адрес А в справочник узла N. Узел N выбирает информацию оп адресу А.
В отличие от шинного протокола наблюдения, где при записи нового значения в кеш сообщение о модификации передается во все узлы, справочник распознает адрес и обращается только к тому узлу, где содержится данный адрес.
Преимущество архитектуры: простота.
Недостаток архитектуры: объем аппаратной реализации (пропорционален основной памяти системы).
Иерархичность доступа к памяти в NUMA-архитектурах сдерживает рост количества процессоров. Как правило, в современных NUMA-системах количество процессорных узлов не превышает 64, а число процессоров – 128.
Масштабируемая архитектура. Что понимается под словами «масштабируемость кластера»?
Масштабируемая архитектура вычислительной сети – архитектура, позволяющая наращивать количество вычислителей без коренной перестройки топологии или замены имеющегося оборудования. При этом производительность сети должна расти с увеличением количества вычислителей.
Все существующие многопроцессорные архитектуры являются в некотором смысле масштабируемыми. При этом чем выше степень связности модулей многопроцессорной ВС, тем сложнее выполняется масштабирование, но тем быстрее осуществляется обмен данными между узлами.
Широчайшее распространение кластерных многопроцессорных систем в первую очередь объясняется слабой связностью его вычислительных узлов и унифицированной технологией коммутационной сети, эту связь обеспечивающей (Ethernet и т. д.). Кластер является наиболее масштабируемой многопроцессорной системой на сегодняшний день (если не считать вычислений, распределенных по территориальной или глобальной сети), обеспечивая при этом высочайшую производительность для задач, допускающих крупноблочное распараллеливание (научные вычислительные задачу, задачи трехмерной визуализации и др.). При этом кластер показывает сравнительно слабую производительность при мелкоблочном распараллеливании задач.
7. Архитектуры S2MP и NUMA-flex как развитие архитектуры ccNUMA
S2MP - системы.
Дальнейшее развитие архитектуры cc-NUMA, преодолевающее ограничение на масштабируемость, получило название S2MP.
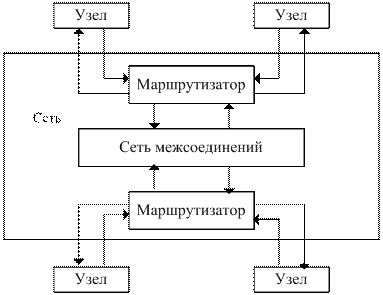
Одним из узких мест, сдерживающих число процессорных узлов, является пропускная способность шин оперативной памяти.
В архитектуре S2MP процессорные узлы объединены сетью, образуемой средой межсоединений и маршрутизаторами.
Для поддержания когерентности кешей в S2MP-архитектуре используется протокол справочника (как в cc-NUMA).
Использование в этих системах программируемых маршрутизаторов позволяет реализовывать системы с различной топологией (и, естественно, различным числом процессорных узлов).
В S2MP Origin 2000, например, топологией является гиперкуб с числом процессорных элементов, равным 512.
Архитектура NUMA-flex.
Архитектура NUMA-flex во многом является наследницей S2MP.

Более высокая степень готовности обеспечивается технологией так называемого разделения, которая позаимствована у кластеров.
Каждый узел архитектуры NUMA-flex представляет собой независимый сервер и для связи с другими узлами использует инфраструктуру архитектуры S2MP.
В каждом узле может работать своя версия ОС (например, в Origin 2000 это Irix).
Специальные аппаратные средства осуществляют контроль и изолирование ошибок, возникающих в одном из узлов, и не дают ошибке распространиться на другие узлы.
8. Основные понятия теории моделирования параллельных КС. Методы моделирования параллельных КС
Моделирование - это замещение исследуемого объекта (оригинала) его условным образом или другим объектом (моделью) и изучение свойств оригинала путем исследования свойств модели.
Условия для существования пользы от моделирования:
- модель обеспечивает корректное (или, как говорят, адекватное) отображение свойств оригинала, существенных с точки зрения исследуемой операции;
- модель позволяет устранить проблемы, присущие проведению измерений на реальных объектах.
В зависимости от способа реализации, все модели можно разделить на два больших класса; физические и математические.
Физические модели предполагают, как правило, реальное воплощение физических свойств оригинала. Например, при проектировании нового самолета создается его макет, обладающий теми же аэродинамическими свойствами.
Математическая модель представляет собой формализованное описание системы (или операции) на некотором абстрактном языке, например в виде совокупности математических соотношений или схемы алгоритма. По большому счету, любое математическое выражение, в котором фигурируют физические величины, можно рассматривать как математическую модель того или иного процесса или явления.
Этапы компьютерного моделирования - мат. моделирования с использованием средств ВТ:
Определение цели моделирования. Разработка концептуальной модели. Формализация модели. Программная реализация Планирование проведения эксперимента Реализация плана эксперимента Анализ результатов моделирования9. Задачи моделирования параллельных КС
При разработке конкретной модели цель моделирования должна уточняться с учетом используемого критерия эффективности. Для критерия пригодности модель, как правило, должна обеспечивать расчет значений показателя эффективности (ПЭ) для всего множества допустимых стратегий (показатель эффективности позволяет оценить и сравнить (по тем или иным правилам) результат операции, полученный при использовании каждой конкретной стратегии). При использовании критерия оптимальности модель должна позволять непосредственно определять параметры исследуемого объекта, дающие экстремальное значение ПЭ.
Таким образом, цель моделирования определяется как целью исследуемой операции, так и планируемым способом использования результатов исследования.
Например, проблемная ситуация, требующая принятия решения, формулируется следующим образом: найти вариант построения КС, который обладал бы минимальной стоимостью при соблюдении требований по производительности и по отказоустойчивости. В этом случае целью моделирования является отыскание параметров КС, обеспечивающих минимальное значение ПЭ, в роли которого выступает стоимость.
Задача может быть сформулирована иначе: из нескольких вариантов конфигурации КС выбрать наиболее отказоустойчивый. Здесь в качестве ПЭ выбирается один из показателей отказоустойчивости, а целью моделирования является сравнительная оценка вариантов КС по этому показателю.
10. Приведите основные принципы моделирования.
1. принцип информационной достаточности. При полном отсутствии инфы об исследуемой системе, постоение системы невозможно. Существует некий критический уровень сведений о системе, при достижении которого возможно построение системы.
2. принцип осуществимости. Созданная модель должна обеспечивать достижение поставленной цели за конечное время. Обычно задают некоторое пороговое значение P0 – вероятность достижения цели моделирования и приемлемое значение времени t0 модель считается осуществимой если P0(t0) ≥ P(t).
3. принцип множественности модели. Является главным. Создаваемая модель должна отражать в 1ю очередь те свойства системы, которые влияют на выбранный показатель эффективности. Соответственно при использовании любой конкретной модели познаются лишь некоторые стороны реальности. Для более полного ее исследования необходим ряд моделей, позволяющих с разных сторон и с разной степенью детальности отражать рассматриваемый процесс.
4. принцип агрегирования. В большинстве случаев сложную систему можно представить состоящей из агрегатов (подсистем), для адекватного математического описания которых оказываются пригодными некоторые стандартные математические схемы. Принцип агрегирования позволяет, кроме того, достаточно гибко перестраивать модель в зависимости от задач исследования.
5. принцип параметризации. В ряде случаев система имеет подсистемы, характеризующие отдельным параметром. Такие подсистемы можно заменять в модели соответствующими числовыми величинами. Они описывают процесс их функционирования в схеме. При необходимости зависимость значений этих величин от ситуации может задаваться в виде таблиц, графиков или аналитических формул. Этот принцип позволяет сократить объем и продолжительность моделирования, но снижает адекватность модели.
11. Моделирование параллельных процессов. Применение аппарата сетей Петри. Подклассы и расширение сетей Петри.
Почти любая КС имеет в своём составе параллельно работающие элементы, такие элементы могут взаимодействовать, либо работать независимо. Способы взаимодействия подсистем определяет вид параллельных процессов в системе. Вид процесса влияет на способ моделирования.
Асинхронный процесс – его состояние не зависит от состояния других процессов. Синхронный процесс – его состояние зависит от состояния взаимодействующих процессов. Один и тот же процесс может быть синхронен к одному процессу и асинхронен к другому. Подчиненный процесс – создается и управляется другим процессом более высокого уровня. Независимый процесс – процесс, который не является подчиненным.Реализация параллельных процессов в КС
Процессы могут быть истинно параллельны только в многопроцессорных ВС Многие процессы используют одни и те же ресурсы В КС существует 2 вида процессов – родительский и дочерний. 3 подхода:- На основе взаимного исключения (монопольный захват ресурса одним процессом ) На основе синхронизации по сигналам (обмен сигналами между процессами обозначающими события ) На основе синхронизации по сообщениям (обмен информацией между процессами )
Средство моделирования изначально ориетировано на параллельную работу процессов.
Сети Петри – инструмент исследования систем, в том числе параллельных. Теория сетей Петри делает возможным моделирование системы математическим представлением ее в виде сети Петри. Анализ сетей Петри помогает получить важную информацию о структуре, динамическом поведении моделируемой системы. Применяются сети Петри исключительно в моделировании. Сети Петри разрабатываются специально для моделирования тех систем, которые содержат взаимодействующие параллельные компоненты, программы, устройства.
Для иллюстрации понятий теории сетей Петри гораздо более удобно графическое представление сетей Петри. Теоретико-графовым представлением сети Петри является двудольный ориентированный граф.
Структура сети Петри представляет из себя совокупность позиций и переходов. В соответствии с этим граф сети Петри обладает двумя типами узлов:
1. Кружок является позицией
2. Планка обозначает переходы.
Граф G сети Петри есть двудольный ориентированный мультиграф G = (V, A), где V = (u1, u2, .., un) – множество вершин, А = (а1, а2, .., аr) – комплект направленных дуг.
ai = {vj, vk}, где vj, vk ![]() V. V может быть разбито на два непересекающихся подмножества P и Т(позиции и переходы), таких что V = Р
V. V может быть разбито на два непересекающихся подмножества P и Т(позиции и переходы), таких что V = Р![]() Т, P∩T=0.
Т, P∩T=0.
Выполнением сети Петри управляет количество и распределение фишек в сети. Фишки находятся в позициях (кружочках) и управляют выполнением перехода сети. Сеть Петри выполняется посредством запусков перехода, который в свою очередь запускается удалением фишек из его входных позиций и образованием новых фишек, помещаемых в его выходные позиции. Переход может запускаться только в том случае, когда он разрешен. Переход называется разрешенным, если каждая из его входных позиций имеет число фишек, по крайней мере, равное числу дуг из позиции в переход. Кратные фишки необходимы для кратных дуг. Фишки о входной позиции, которые разрешают переход, называются разрешающими фишками.
Подклассы сетей Петри:
- Простой сетью Петри называется набор
1. ![]() - множество мест;
- множество мест;
2. ![]() - множество переходов таких, что
- множество переходов таких, что ![]() .
.
3. ![]() - отношение инцидентности такое, что:
- отношение инцидентности такое, что:
a. 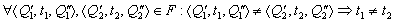
b. 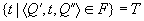
- Регулярные сети (вводится алгебра регулярных сетей, строятся операции над сетями и классы элементарных сетей). Чистые сети (переход не может иметь позицию Pi в качестве входной и выходной). Сети свободного выбора (этот подкласс допускает и конфликты автоматных сетей Петри, и параллельность маркированных графов, но в более ограниченном виде, чем в обычных сетях Петри. Сеть Петри со свободным выбором есть сеть Петри С = (Р, Т, I, О) — такая, что для всех
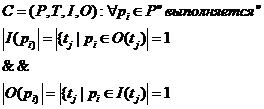
Расширение сетей Петри.
· Обощенные сети – граф сети – мультиграф.
· Раскрашенные сети – раскрашиваются метки в позициях.
· Приоритетные сети – позволяют учитывать в модели приоритеты. Вводится доп. множество I прямых инцендентных дуг запрета. Для срабатывания некого перехода t с проверкой на приоритет требуется отсутствие меток во всех входных позициях запрета.
· Е-сети
· Сети Мерлина
· Временные сети
· Сети с проверкой на ноль
12. Применение сетей Петри для синтеза дискретных управляющих устройств.
Простое представление системы сетью Петри основано на двух основополагающих понятиях: событиях и условиях. События - это действия, имеющие место в системе. Возникновением событий управляет состояние системы Состояние системы может быть описано множеством условий Условие — есть предикат или логическое описание состояния системы. Условие может принимать либо значение «истина», либо значение «ложь». Так как события являются действиями, то они могут происходить. Для того чтобы событие произошло, необходимо выполнение соответствующих условий. Эти условия называются предусловиями события. Возникновение события может вызвать нарушение предусловий и может привести к выполнению других условий, постусловий.
В качестве примера рассмотрим задачу моделирования простого автомата-продавца. Автомат-продавец находится в состоянии ожидания до тех пор, пока не появится заказ, который он выполняет и посылает на доставку. Условиями для такой системы являются:
а) автомат-продавец ждет;
б) заказ прибыл и ждет;
в) автомат-продавец выполняет заказ;
г) заказ выполнен.
Событиями будут:
1. Заказ поступил.
2. Автомат-продавец начинает выполнение заказа.
3. Автомат-продавец заканчивает выполнение заказа.
4. Заказ посылается на доставку.
Предусловия события 2 (автомат-продавец начинает выполнение заказа) очевидны:
(а) автомат-продавец ждет; (б) заказ прибыл и ждет.
Постусловие для события 2:
(в) автомат-продавец выполняет заказ.
Аналогично мы можем определить предусловия и постусловия для других событий и составить следующую таблицу событий и их пред - и постусловий:
Событие | Предусловие | Постусловие |
1 | нет | б |
2 | а, б | в |
3 | в | г, а |
4 | г | нет |
Такое представление системы легко моделировать сетью Петри.
В сети Петри условия моделируются позициями, события - переходами. При этом входы перехода являются предусловиями соответствующего события; выходы - постусловиями. Возникновение события равносильно запуску соответствующего перехода. Выполнение условия представляется фишкой в позиции, соответствующей этому условию. Запуск перехода удаляет разрешающие фишки, представляющие выполнение предусловий и образует новые фишки, которые представляют выполнение постусловий. Сеть Петри на рис. 3.1 иллюстрирует модель приведенного выше автомата-продавца. Мы указали каждому переходу и позиции соответствующие событие и условие.
13. Оценочные или Е-сети как расширение сетей Петри
Е-сети (![]()
P – множество позиций,
Pp множество периеритных позиций
PR множество решающих позиций
T – множество переходов причем ti = ( ρS, t(ti) )
S – тип перехода (, t(ti) время перехода, ρ(ti) – функция перехода, функция преобразования атрибута меток.
В Е-сетях метки интерпретируются, как транзакты, распространяющиеся по сети, а вершины и переходы трактуются как устройства обработки транзактов. Требование – ни одна вершина не может иметь более 1 метки (т. е. сеть изначально безопасна).
Типы переходов:
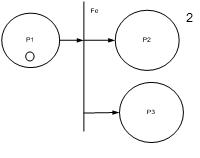
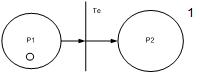 1. простой переход, срабатывает при наличии фишки в P1 и отсутсвии в P2, моделирование некоторого устройства обработки инф. Te-переход позволяет отразить модели в течение некоторого времени τ(tj). Срабатывание перехода происходит при наличии во входной позиции p1 фишки и отсутствии фишки в выходной позиции p2 (1,0) ˫t(0,1)
1. простой переход, срабатывает при наличии фишки в P1 и отсутсвии в P2, моделирование некоторого устройства обработки инф. Te-переход позволяет отразить модели в течение некоторого времени τ(tj). Срабатывание перехода происходит при наличии во входной позиции p1 фишки и отсутствии фишки в выходной позиции p2 (1,0) ˫t(0,1)
2. разветвление потока транзактов в ВС.
Переход Fe срабатывает при тех же условиях, что и переход Te (1,0,0) ˫f(0,1,1). С содержательной точки зрения Fe отражает разветвление потока информации в моделируемой системе (транзактор информации)
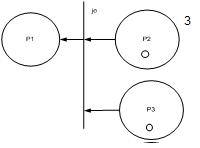 3. объединение наличие фишек P2, P3 и отстутсвие в P1. Переход Je срабатывает при наличии меток в обеих входных позициях и отсутствия метки в выходной позиции (1,1,0) ˫J(0,0,1). Переход Je моделирует объединение потоков информации или наличие нексольких условий, определяющих методы разложения.
3. объединение наличие фишек P2, P3 и отстутсвие в P1. Переход Je срабатывает при наличии меток в обеих входных позициях и отсутствия метки в выходной позиции (1,1,0) ˫J(0,0,1). Переход Je моделирует объединение потоков информации или наличие нексольких условий, определяющих методы разложения.
 4. управляющие разветвление изменяет направление потока транзактов. Переход Xe используется при необходимости изменения потока. (0,1,0,0) ˫X(0,0,1,0) (0,1,0,1) ˫X(0,0,1,1) (1,1,0,0) ˫X(0,0,0,1) (1,1,1,0) ˫X(0,0,1,1)
4. управляющие разветвление изменяет направление потока транзактов. Переход Xe используется при необходимости изменения потока. (0,1,0,0) ˫X(0,0,1,0) (0,1,0,1) ˫X(0,0,1,1) (1,1,0,0) ˫X(0,0,0,1) (1,1,1,0) ˫X(0,0,1,1)
5. 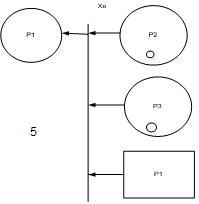 Приоритетность одних потоков информации к другим. Переход Ye – приоритетный переход. При этом разрешающая процедура может быть определена различными способами: как операция сравнения приоритетов меток, как функция атрибутов меток. Переход Ye отражает приоритетность установленную для одних потоков информации по отношению к другим.
Приоритетность одних потоков информации к другим. Переход Ye – приоритетный переход. При этом разрешающая процедура может быть определена различными способами: как операция сравнения приоритетов меток, как функция атрибутов меток. Переход Ye отражает приоритетность установленную для одних потоков информации по отношению к другим.
(0,1,1,0) ˫Y(0,0,1,1) (0,1,0,0) ˫Y(0,0,0,1) (0,0,1,0) ˫Y(0,0,0,1) (1,1,1,0) ˫Y(0,1,0,1) (1,1,0,0) ˫Y(0,0,0,1) (1,0,1,0) ˫Y(0,0,0,1)
14. Моделирование конвейерной обработки информации
На протяжении последних лет было предпринято множество шагов направленных на увеличение производительности ВС. Результатом одного из таких шагов было появление ВС с конвейерной обработкой информации. Конвейер состоит из набора операций которые могут выполняться параллельно. Когда операция k завершена, она передает свой результат (k+1)-й операции и ждет данных от (k-1)-й.
В качестве примера рассмотрим сложение 2 чисел с плавающей точкой. Основные шаги этой операции предполагают:
Выделить экспоненты этих 2 чисел Сравнить эти экспоненты, и если необходимо изменить их должным образом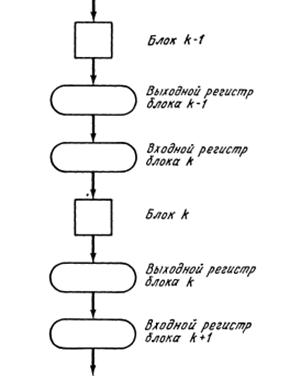 Сдвинуть точку в числе с меньшей экспонентой для их уравнения Сложить дроби Нормализовать результат Проверить экспоненту на переполнение и сформировать экспоненту и дробь результата
Сдвинуть точку в числе с меньшей экспонентой для их уравнения Сложить дроби Нормализовать результат Проверить экспоненту на переполнение и сформировать экспоненту и дробь результата Конвейеры (по способу управления) можно разделить на 2 группы: синхронные и асинхронные. Синхронные конвейеры каждый такт передают данные на следующий шаг обработки. Но это не эффективно, т. к. действие, выполняемое на данном шаге, может занимать времени больше/меньше чем 1 такт. Рассмотрим k-й блок конвейера. Для управления им нужно знать когда выполняются следующие условия:
- Входной регистр заполнен Входной регистр пуст Выходной регистр заполнен Выходной регистр пуст Блок занят Блок свободен Пересылка осуществлена
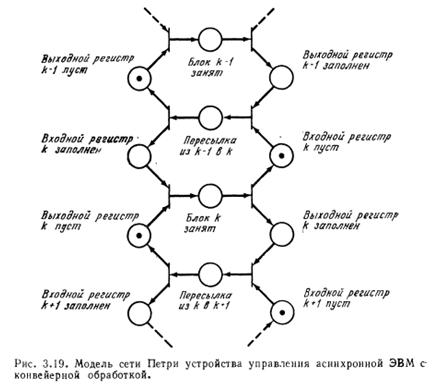
15. Задачи сохранения и активности сети Петри
Сети Петри наиболее сильны там где есть параллельность.
Сохранение

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
