

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Классификация параллельных КС по структурно-функциональным признакам. 2
2. Классификация параллельных КС по функциональным возможностям КС с точки зрения пользователя. 6
3. Проведите сравнительный анализ классификаций компьютерных систем. 7
4. Мультикомпьютеры, кластеры и симметричные мультипроцессоры - общая характеристика, схемы построения, особенности каждой из систем, области применения. 8
5. Системы с распределенной и разделяемой памятью, массово-параллельные системы - общая характеристика, схема построения, особенности каждой из систем, области применения. 10
6. Структура, достоинства и недостатки UMA-, NUMA - и ccNUMA-систем.. 11
UMA (заход на UMA через SMP) 11
Масштабируемая архитектура. Что понимается под словами «масштабируемость кластера»?. 12
7. Архитектуры S2MP и NUMA-flex как развитие архитектуры ccNUMA.. 13
8. Основные понятия теории моделирования параллельных КС. Методы моделирования параллельных КС 14
9. Задачи моделирования параллельных КС.. 15
10. Приведите основные принципы моделирования. 16
11. Моделирование параллельных процессов. Применение аппарата сетей Петри. Подклассы и расширение сетей Петри. 17
12. Применение сетей Петри для синтеза дискретных управляющих устройств. 19
13. Оценочные или Е-сети как расширение сетей Петри. 20
14. Моделирование конвейерной обработки информации. 21
15. Задачи сохранения и активности сети Петри. 22
16. Задачи достижимости и покрываемости сети Петри. 25
17. Задача безопасности и ограниченности сети Петри. 26
19. Моделирование сетями Петри задач синхронизации при взаимодействии процессов в КС.. 27
20. Задача активности сетей Петри. 29
21. Анализ сетей Петри матричным методом.. 31
22. Матричный метод анализа сетей Петри - достоинства и недостатки метода. 33
23. Задача достижимости сетей Петри. 34
18. Использование сетей Петри для количественных оценок функционирования параллельных КС. 35
24. Границы возможностей моделирования с помощью сетей Петри. 35
27. Границы возможностей моделирования с помощью сетей Петри. 35
По словам Можарова здесь нужно рассказать поверхностно о сетях Петри, где используются, зачем вообще применяются, какие существуют подклассы и расширения, чем они лучше исходных сетей Петри, рассмотреть методы анализа. 35
25. Подклассы сетей Петри. 36
26. Маркированные графы – подкласс сетей Петри. 37
Этот подкласс позволяет моделировать алгоритмы функционирования вычислительных систем, взаимосвязи между подсистемами и ряд других факторов без учета конкуренции между процессами. 28. Покажите, используя матричный метод анализа сетей Петри, что маркировка (0, 7, 0, 1) недостижима из маркировки (1, 0, 1, 0) для сети Петри, изображенной на рисунке. 37
28. Покажите, используя матричный метод анализа сетей Петри, что маркировка (0, 7, 0, 1) недостижима из маркировки (1, 0, 1, 0) для сети Петри, изображенной на рисунке. 38
29. Дана последовательность запусков переходов s = t3 t2 t3 t2 t1 сети Петри, изображенной на рисунке. Определите вектор запуска и маркировку m’ сети Петри. 39
30. Определите является ли маркировка (1, 8, 0, 1) достижимой из маркировки (1, 0, 1, 0) для сети Петри, изображенной на рисунке. Найдите последовательность запусков переходов s. 40
31. Понятие о топологическом синтезе и анализе структур КС.. 41
32. Разбиения чисел. Основные понятия и определения. Принцип Дирихле. 42
33. Вложимость разбиений. 43
34. Ранговое условие вложимости; пример использования. 44
35. Принцип полного размещения; пример использования. 45
36. Вложимость с ограничениями; пример использования. 46
37. Комбинаторные модели для исследования процесса распредления памяти КС.. 47
38. Особенность распредления памяти в КС с сегментной организацией программ и данных (Модель 2). Приведите пример. 51
39. Комбинаторная модель для оценки необходимого размера памяти КС (модель 3). 52
40. Комбинаторные модели, позволяющие произвести расчет оценки сверху необходимого размера оперативной памяти КС.. 54
41. Диаграммы Ферре и инверсии в бинарных последовательностях. 56
42. Влияние топологии на технические характеристики сетей. 58
43. Классы характеристик КС.. 59
44. Абсолютно однородная сеть (определение, примеры) 60
45. Какую [n, m]-сеть можно назвать уницентральной?. 60
46. Построить коммутатор по схеме сети косвенного двоичного куба. 61
47. Построить двухкаскадный коммутатор компьютерной сети. 61
48. Понятие о сложности сети КС.. 63
49. Задача отображения множества программных модулей на множество процессоров. 64
50. Проблемы адаптации структуры КС к алгоритмам решаемых задач в терминах теории графов. 65
51. Диаметр и средний диаметр [n, m]-сети. 66
52. Надежность сети КС.. 67
53. Надежность кольцевой структуры КС.. 67
54. Отказоустойчивость (живучесть) топологической структуры КС.. 68
55. Связь стоимостных характеристик и топологии КС.. 69
56. Приведите общее выражение для переключающей матрицы.. 70
57. Определите ![]() в узле КС и в КС.. 71
в узле КС и в КС.. 71
58. Дайте определение реберного графа и постройте граф L(G), если граф G имеет вид: 71
59. Приведите определение и поясните особенности параллельных КС с магистральными связями. 72
60. Приведите математическое описание магистрально-модульной КС. 73
61. Структура магистрально-модульных КС; особенности построения структур магистральных КС и их отличие от других типов структур компьютерных сетей?. 74
62. Приведите определение реберного графа и постройте граф L(G) неориентированного графа C4. 74
1. Классификация параллельных КС по структурно-функциональным признакам.
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока.
Классификация Флинна
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD:
| SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка |
| SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Обработка элементов вектора может производиться либо процессорной матрицей, либо с помощью конвейера. |
| MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. |
| MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Большинство ВС попадают именно в этот класс. |
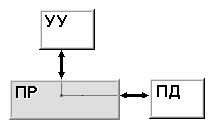
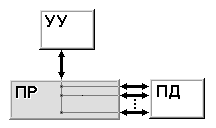
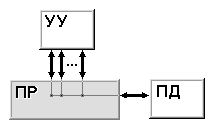
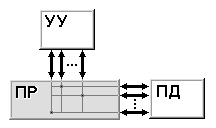
Классификация Хокни
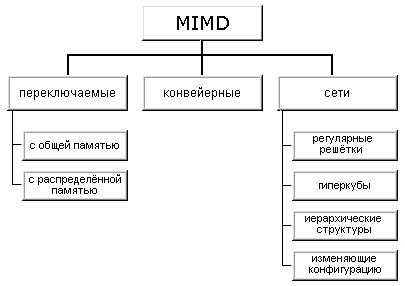
Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными. Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса:
- MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя;
- MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.
Далее, среди MIMD машин с переключателем выделяются те, в которых вся память распределена среди процессоров как их локальная память. В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью. В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина.
При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети
Классификация Шнайдера
В 1988 году Шнайдер предложил новый подход к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных. Именно разделение потоков на адреса и их содержимое позволяет описать такие ранее "неудобные" для классификации архитектуры, как компьютеры с длинным командным словом, систолические массивы и целый ряд других. Данная классификация основывается на выделении пары (I;D)=(команды;данные) и называет эту пару вычислительным шаблоном. Все компьютеры разбиваются на классы в зависимости от того, какой шаблон они могут использовать.
Компьютер может исполнить шаблон (I;D), если он может выдать:
- адреса команд для одновременной выборки из памяти;
- декодировать и проинтерпретировать множество команд;
- выдать одновременно множество адресов операндов;
- выполнить одновременно операции над различными данными;
По классификации можно выделить следующие классы компьютеров:
- классические фон-неймановские;
- фон-неймановские, в которых заложена возможность выбирать данные, расположенные с разным смещением относительно одного и того же адреса, над которыми будет выполнена одна и та же операция;
- SIMD без возможности получения уникального адреса для данных в каждом процессорном элементе;
- SIMD, имеющих возможность независимой модификации адресов операндов в каждом процессорном элементе;
- компьютеры типа MIMD;
- КС, выбирающие и исполняющие одновременно несколько команд, причем для доступа к которым используеся один адрес.
Классификация Скилликорна
В 1989 году была сделана очередная попытка расширить классификацию Флинна для преодоления ее недостатков. Скилликорн разработал подход, пригодный для описания свойств многопроцессорных систем и некоторых нетрадиционных архитектур.
 Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент:
Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент:
- процессор команд (IP - Instruction Processor) - функциональное устройство, работающее, как интерпретатор команд; в системе, вообще говоря, может отсутствовать;
- процессор данных (DP - Data Processor) - функциональное устройство, работающее как преобразователь данных, в соответствии с арифметическими операциями;
- иерархия памяти (IM - Instruction Memory, DM - Data Memory) - запоминающее устройство, в котором хранятся данные и команды, пересылаемые между процессорами;
- переключатель - абстрактное устройство, обеспечивающее связь между процессорами и памятью.
Переключатели бывают четырёх типов: «1 - 1» (связывают пару устройств), «n - n» (связывает каждое устройство из одного множества устройств с соответствующим ему устройством из другого множества, то есть фиксирует попарную связь), «1 - n» (соединяет одно выделенное устройство со всеми функциональными устройствами из некоторого набора), «n x n» (связь любого устройства одного множества с любым устройством другого множества).
Классификация Скилликорна основывается на следующих восьми характеристиках:
- Количество процессоров команд IP
- Число ЗУ команд IM
- Тип переключателя между IP и IM
- Количество процессоров данных DP
- Число ЗУ данных DM
- Тип переключателя между DP и DM
- Тип переключателя между IP и DP
- Тип переключателя между DP и DP
Классификация Фенга
В 1972 году Фенг предложил классифицировать вычислительные систем на основе двух простых характеристик. Первая — число n бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной ВС. Немного изменив терминологию, функционирование ВС можно представить как параллельную обработку m битовых слоёв, на каждом из которых независимо преобразуются n бит. Каждую вычислительную систему можно описать парой чисел (n, m). Произведение P = n x m определяет интегральную характеристику потенциала параллельности архитектуры, которую Фенг назвал максимальной степенью параллелизма ВС.
Таким образом все КС MIMD можно разделить на 4 класса:
- Разрядно-последовательные, пословно-последовательные n=m=1 (в каждый момент времени такая система обрабатывает только 1 двоичный разряд);
- Разрядно-параллельные последовательно-последовательные n>1, m=1 (большинство классических последовательных компьютеров и многие вычислительные системы принадлежит к данному классу);
- Разрядно-последовательные, пословно-параллельные n=1, m>1 (обычно КС этого класса состоят из большого числа одноразрядных процессоров, причем каждый процессор может независимо от остальных обрабатывать свои данные);
- Разрядно-параллельные, пословно параллельные n>1, m>1 (большая часть существующих параллельных вычислительных систем, обрабатывая одновременно mn двоичных разрядов, принадлежит именно к этому классу);
Классификация Хендлера
В основу классификации Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. При этом он намеренно не рассматривает различные способы связи между процессорами и блоками памяти и считает, что коммуникационная сеть может быть нужным образом сконфигурирована и будет способна выдержать предполагаемую нагрузку.
Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
- уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы;
- уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления;
- уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
Таким образом, подобная схема выделения уровней предполагает, что вычислительная система включает какое-то число процессоров каждый со своим устройством управления. Каждое устройство управления связано с несколькими арифметико-логическими устройствами, исполняющими одну и ту же операцию в каждый конкретный момент времени. Наконец, каждое АЛУ объединяет несколько элементарных логических схем, ассоциированных с обработкой одного двоичного разряда (число ЭЛС есть не что иное, как длина машинного слова).
Если на какое-то время не рассматривать возможность конвейеризации, то число устройств управления k, число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данной вычислительной системы C: t(C)= (k, d, w).
2. Классификация параллельных КС по функциональным возможностям КС с точки зрения пользователя.
· Мультикомпьютер - совокупность объединенных сетью отдельных вычислительных модулей, каждый из которых управляется своей операционной системой (ОС). Пример серия SP фирмы IBM.
· кластеры - набор компьютеров, рассматриваемый ОС, системным программным обеспечением, программными приложениями и пользователями как единая система.
· Симметричные мультипроцессорные системы SMP - состоят из нескольких десятков процессоров, разделяющих общую основную (оперативную) память и объединенных коммуникационной системой
· массово-параллельные системы - В этих КС узлы обычно состоят из одного или нескольких процессоров, локальной памяти и нескольких устройств ввода/вывода. Чаще всего в МРР-системах реализуется архитектура без разделения ресурсов. В каждом узле работает своя копия ОС, а узлы объединяются специализированной коммуникационной средой.
· системы с распределенной разделяемой памятью - Общим является наличие, помимо кэша, локальной памяти в каждом процессорном узле. Узел может состоять из нескольких процессоров и иметь архитектуру SMP. Поддерживается общее адресное пространство памяти. Однако при этом память является распределенной по узлам, и время доступа зависит от места расположения данных. Поэтому некоторые DSM-системы получили название NUMA (Non-Uniform Memory Access), что означает неоднородный доступ к памяти.
Характеристика | Тип системы | |||
Мультикомпьютер | Кластер | SMP, DSM | MPP | |
Порядок числа узлов N | 1 | До 100 | 10 | |
Сложность узла | В широком диапазоне от ПК и выше | ПК | Один или несколько ЦП | От процессорного элемента до ПК |
Взаимодействие узлов | Разделяемые файлы | Обмен сообщениями | Общая разделяемая (SMP) или распределенная (DSM) память | Обмен сообщениями или разделение переменных распределенной памяти |
Планирование вычислительных работ | Независимые очереди процессов | Множество скоординированных очередей | Одна очередь | Одна очередь на хост-узле при поддержке единой системы |
Поддержка образа единой системы | Частично | Да | Да (SMP), Нет (NUMA) | Частично |
Тип и наличие ОС | N копий распределенных ОС | N копий, N разных ОС или микроядер | Одна монолитная (SMP), от одной до N (DSM) | N микроядер, монолитные ОС, N копий распределенных ОС |
Адресное пространство | Множественное | Множественное или единое | Единое | Множественное или единое |
3. Проведите сравнительный анализ классификаций компьютерных систем.
В качестве основных признаков классификаций, характеризующих структуру и функционирование ВС с точки зрения параллельности работы системы, чаще всего используют следующие характеристики:
- тип потока команд
- тип потока данных
- способ обработки данных
- тип коммуникационной среды
- степень однородности компонент системы
- степень согласованности режима работы устройств
По способу обработки данных ВС делятся на системы с пословной и поразрядной обработкой. В системах с пословной обработкой все разряды каждого слова обрабатываются процессором последовательно (слово за словом). В системах с поразрядной обработкой одноименные разряды большого числа слов обрабатываются одним процессором, но параллельно (ассоциативные системы).
Классификация Флинна
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Классификация Хокни
Осуществляет систематизацию компьютеров, попадающих в класс MIMD по систематике Флинна.
Классификация Шнайдера
Можно отметить два положительных момента в данной классификации: более избирательная систематизация SIMD компьютеров и возможность описания нетрадиционных архитектур типа систолических массивов или компьютеров с длинным командным словом. Однако почти все вычислительные системы типа MIMD опять попали в один и тот же класс. Это и не удивительно, так как критерий классификации, основанный лишь на потоках команд и данных без учета распределенности памяти и топологии межпроцессорной связи, слишком слаб для подобных систем.
Классификация Скилликорна
- облегчает понимание того, что достигнуто на сегодняшний день в области архитектур вычислительных систем, и какие архитектуры имеют лучшие перспективы в будущем;
- подсказывает новые пути организации архитектур (речь идет о тех классах, которые в настоящее время по разным причинам пусты);
- показывает, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем (с этой точки зрения, классификация может служить моделью для анализа производительности).
Классификация Фенга
Достоинством является введение единой числовой метрики для всех типов компьютеров, которая вместе с описанием потенциала вычислительных возможностей конкретной архитектуры позволяет сравнить любые два компьютера между собой.
Классификация Хендлера
Первая операция (x) в каком-то смысле отражает конвейерный принцип обработки и предполагает последовательное прохождение данных сначала через первый ее аргумент-подсистему, а затем через второй. Чтобы внести большую ясность, аналогично операции конвейерного исполнения, Хендлер вводит операцию параллельного исполнения (+), фиксирующую возможность независимого использования процессоров разными задачами. И наконец третья операция - операция альтернативы (V), показывает возможные альтернативные режимы функционирования вычислительной системы. Чем больше для системы таких режимов, тем более гибкой архитектурой, по мнению Хендлера, она обладает.
4. Мультикомпьютеры, кластеры и симметричные мультипроцессоры - общая характеристика, схемы построения, особенности каждой из систем, области применения.
Мультикомпьютеры.
Мультикомпьютеры – совокупность объединенных сетью отдельных вычислительных модулей, каждый из которых управляется своей ОС (например, серии SP1I6M). Узлы мультикомпьютеров обычно не имеют общих структур и связаны лишь сетью. Узлы обладают высокой степенью автономности и могут состоять из отдельных компонентов, в том числе и кластеров, SMP-, SPM-, DSM-, MPP–систем.
Для распределенной ОС мультикомпьютер выглядит как виртуальный однопроцессорный ресурс. Взаимодействие процессоров реализуется с помощью явно заданных операций связи между вычислителями. Обычно в мультикомпьютере реализуется согласованный сетевой протокол, и не существует единой очереди выполняющихся процессов, хотя известны и другие примеры.
Кластеры.
Кластер – набор компонентов, рассматриваемый операционной системой, системным ПО, приложениями и пользователями как единая система.
Кластеры получили широкое распространение из-за высокого уровня производительности при относительно низких затратах. Высокая производительность объясняется отсутствием совместно используемой оперативной памяти и наличием в каждом узле копии общей ОС или собственной ОС для неоднородных кластеров. Специализированное ПО производит контроль правильности работы узлов кластера. При отказе узла кластера его ресурсы (дисковое пространство, задание и т. д.) переназначаются другим узлам.
По сути, кластер образуется из отдельных полноценных узлов, включающих процессоры, память, подсистему ввода-вывода, ОС и т. д. При объединении компьютеров в кластер чаще всего поддерживается прямая связь между узлами посредством коммуникационной сети. Технология такой сети может варьироваться от простейшей (Ethernet) до сложных специализированных вариантов, обеспечивающих высокую скорость обмена. Возможно параллельное использование нескольких независимых сетей в рамках одного кластера.
 На рисунке изображены 2 типичные структуры кластеров: архитектура с разделяемыми дисками (слева) и архитектура без разделения дисков.
На рисунке изображены 2 типичные структуры кластеров: архитектура с разделяемыми дисками (слева) и архитектура без разделения дисков.
В архитектуре с разделением дисков все узлы кластера имеют доступ ко всем дискам. В архитектуре без разделения дисков, несмотря на то, что поддерживается целостный образ ресурса, каждый узел имеет собственную оперативную память и диски; в таких системах общей является только коммуникационная сеть.
С точки зрения повышения производительности кластер является хорошо масштабируемой ВС. Однако отсутствие общей разделяемой памяти (а иногда и единого адресного пространства) обуславливает большие накладные расходы, связанные с обменом сообщениями между узлами.
Наибольший эффект кластеры дают при вычислениях в рамках хорошо структурированных научных приложениях. С точки зрения удобства масштабирования кластерные архитектуры допускают практически неограниченное наращивание числа узлов. Для управления кластером используются специальные инструменты для поддержания единого образа ресурса, в частности, система пакетной обработки.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
