
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глава 3. Методы построения эффективных алгоритмов.
Существует достаточно большое число методов разработки эффективных алгоритмов решения задач различных классов.
Наиболее часто используются следующие методы:
1) «Разделяй и властвуй» - метод декомпозиции, метод сведения задачи к подзадачам, метод частных целей.
2) Балансировка. Этот метод применим только к алгоритмам, к которым уже применялся 1-ый метод.
3) Динамическое программирование.
4) «Жадный» алгоритм.
5) Метод программирования «с отходом назад» (Back Tracing), программирование с отслеживанием.
6) Метод локального поиска (подъема).
7) Метод эвристики.
8) Метод рекурсии.
9) Моделирование задач.
При выборе правильного метода решения задачи необходимо ответить на вопросы:
1. Насколько хорошо Вы понимаете проблему?
А) Что представляют собой входные данные?
Б) Что должен представлять собой результат?
В) Можно ли решить пример задачи на ограниченном малом объёме входных данных вручную?
Г) Каков реальный типовой размер задачи на практике (N=?).
Д) Какие условия и ограничения накладываются на время решения задачи?
Е) Что приемлемо: прямое решение простым алгоритмом или разработка специального эффективного алгоритма в течение какого-то времени.
Ж) Определение класса к которому можно отнести задачу (комбинаторная, задача принятия решений, на графах и др.).
2. Можно ли построить простой алгоритм или эвристику?
Если ДА, то будет ли такой алгоритм корректным и какова его вычислительная сложность T(N)?
3. Существует ли типовой алгоритм решения задачи данного класса?
4. Существует ли какой-либо упрощенный вариант задачи, который можно решить сразу, если игнорировать некоторые входные параметры и ограничения задачи, допуская упрощенное представление форматов данных? Можно ли обобщить алгоритм решения упрощенного варианта задачи на всю задачу?
5. Какой из стандартных методов разработки эффективных алгоритмов наиболее соответствует задаче?
3.1 Метод «Разделяй и властвуй».
При решении задачи необходимо ответить на следующие вопросы:
1. Известно ли решение для какой-либо части задачи и можно ли решить оставшуюся неизвестной часть.
2. Известны ли частные случаи решения задачи, и можно ли разработать алгоритм решения задачи для ограниченного подмножества исходных операндов.
3. Существует ли в задаче неясные моменты (раскрытие глубины задачи).
4. Существует ил похожая задача того же класса и решение для нее. Можно ли изменить алгоритм решения второй задачи для получения решения первой.
В основе метода «Разделяй и властвуй» лежит разбиение задачи на подзадачи (декомпозиция).
Первый шаг – это разделение задачи на К подзадач со сложностью 1/К.
Властвование – второй шаг алгоритма. Это – использование рекурсионного процесса разбиения подзадач на еще более мелкие подзадачи до тех пор, пока подзадачи n-го уровня разделения будут достаточно малы для их тривиального решения.
 |
… … … …
Третий этап метода – склеивание множества решений отдельных подзадач в общее решение.
Использование этого метода требует, чтобы в процессе разбиения подзадачи не повторялись и не пересекались друг с другом. Если это условие не выполняется, то данный метод решения не применим к таким задачам.
Примерами решаемых этим методом задач являются:
ü сортировка слиянием;
ü нахождение максимального/минимального элемента массива;
ü умножение длинных целочисленных значений;
ü алгоритм быстрого преобразования Фурье;
ü алгоритм «Ханойская башня»;
ü составление графика проведения чемпионата.
Задача 5.1.1 {Listing 3.1}
Отсортировать массив из n чисел в порядке возрастания.
Обменная сортировка:
6 | 3 | 2 | 7 | 5 | 1 | 3 | 7 |
1 | 3 | 2 | 7 | 5 | 6 | 3 | 7 |
1 | 2 | 3 | 7 | 5 | 6 | 3 | 7 |
1 | 2 | 3 | 3 | 5 | 6 | 7 | 7 |
1 итерация
2 итерация
3 итерация
Общая формула временной сложности записывается рекуррентно:
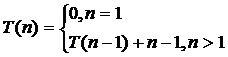
T(n)=n*(n-1)/2=O(n2)
Приведенный алгоритм построен на основе метода «Разделяй и властвуй».
Недостаток: в приведенном алгоритме размеры подзадач на каждой итерации одинаковы, поэтому при больших n этот алгоритм неэффективен.
Для повышения эффективности алгоритмов, разработанных методом «Разделяй и властвуй», используется метод балансировки, который заключается в разбиении задачи на подзадачи равных размеров.
Например:
Алгоритм сортировки слиянием.
| 3 | 2 | 7 | 5 | 1 | 3 | 7 |
 6
63 | 6 | 2 | 7 | 1 | 5 | 3 | 7 |
2 | 3 | 6 | 7 | 1 | 3 | 5 | 7 |
1 | 2 | 3 | 3 | 5 | 6 | 7 | 7 |
Вычислительная сложность этого алгоритма:
T2(n)=O(n*log(n)),
поэтому можно сделать вывод, что данный алгоритм также является рекурсивным.
Пример процедуры, реализующей этот алгоритм:
Procedure JointSort(P, R: integer;
var A, B: TArray);
var q: integer;
begin
if P=R then exit;
q:= (P+R) div2;
JointSort(P, q, A, B);
JointSort(q+1, R, B, A);
JointSort(P, q, R, B, A);
end;
Метод «Разделяй и властвуй» полезен, если задачу можно разбить на подзадачи за приемлемое время, а суммарный размер подзадач будет небольшим.
Если сумма размеров подзадач пропорциональна a*N, где а=const (a>1), то этот метод дает алгоритм с полиномиальной сложностью O(Nm).
Если разбиение задачи размером N приводит к N подзадачам, каждая из которых имеет сложность (N-1), то такой алгоритм будет иметь экспоненциальную сложность O(mN).
Задача 5.1.2 {Listing 3.2}
Составление сетевого графика выполнения работ.
Имеется комплекс взаимосвязанных работ N. Для каждой из работ задана трудоемкость выполнения. Имеется К рабочих. Требуется распределить рабочих по операциям таким образом, чтобы длительность выполнения всего комплекса работ была минимальной.
Примечание: не учитываются субъективные факторы, и невозможно перемещение рабочих с одной операции на другую в процессе выполнения.
Комплекс взаимосвязанных работ представляется в виде сетевого графика, где узлы графа – это события окончания предшествующих работ, дуги – работы.
Трудоемкость Ri, j характеризует затраты ресурсов на выполнение работы.
Пример сетевого графика:
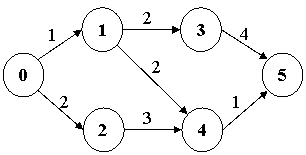 |
L(0, М) – длительность выполнения работы. Эта величина определяется как совокупность возможных путей в графе
{I1, I2, I3}
В данном примере возможны 3 маршрута:
I1={(0, 1); (1, 3); (3, 5)}
I2={(0, 1); (1, 4); (4, 5)}
I3={(0, 2); (2, 4); (4, 5)}
I1=1+2+4=7 – «критический» путь Iкр.
I2=1+2+1=4
I1=2+3+1=6
Необходимо расставить по операциям заданное число рабочих.
Для случая, когда K=N задача является тривиальной.
Для K¹N имеется N(K-N) возможных вариантов расстановки.
Пусть N=7, К=10, тогда имеется 1296 вариантов размещения рабочих.
Решение этой задачи методом полного перебора вариантов неэффективно.
Используя метод «Разделяй и властвуй», разбивают исходную задачу на (К-N) последовательных подзадач. Затем решают вопрос о том, на какую операцию поставить 1-го свободного рабочего (для данного примера – 8-го рабочего). После этого размещают 2-го свободного рабочего, взяв за исходное ранее найденное решение и т. д.
Каждая из этих подзадач может быть сформулирована следующим образом: необходимо принять решение о добавлении одного работника на одну из работ комплекса, чтобы полученная расстановка минимизировала «критический» путь
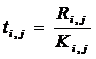
Свободного рабочего размещают на одну из работ, входящих в «критический» путь, желательно, наиболее трудоемкую (здесь – (3, 5)).
Тогда получаем:
I1’=1+2+4/2=5 ® I3=6 ® Iкр
L(0, 5)=6
Поиск решения данным алгоритмом требует анализа не более N*(K-N) вариантов.
3.2 Метод подъема и локальный поиск.
Примеры задач, решаемых этим методом:
1) Задача сетевого планирования.
2) Задача нахождения максимума функции нескольких переменных.
3) Задача поиска минимального остовного дерева в графе.
4) Задача коммивояжера.
5) Алгоритмы численных методов, дающие приближенные решения.
6) Задачи линейного программирования
и др.
Данный метод начинает работу с принятия начального предположения или вычисления начального решения задачи (1 этап).
2 этап – быстрое восхождение вверх от начального решения к более лучшим решениям. Восхождение заключается в преобразовании исходного решения по некоторой заданной ограниченной совокупности решений.
3 этап – перебор всех решений из ограниченного множества до тех пор, пока не будет найдено решение, улучшить которое невозможно. Однако найденное решение может быть неоптимальным (приближенным).
Примечание: если рассматривать улучшение начального решения на множестве всех возможных решений, то получаем метод полного перебора вариантов, дающий оптимальное решение за время, которое может быть неприемлемым. Поэтому метод подъема рассчитан на ограниченное подмножество решений, перебор которых дает вычислительную сложность порядка O(n2) или O(n3).
Метод подъема не гарантирует нахождение оптимального решения за один раз. Если задать несколько начальных приближений и найти соответствующие локальные оптимальные решения, которые могут различаться, и сравнить найденные максимумы с некоторой стоимостной функцией, то можно найти глобальное оптимальное решение.
Определим, как действует метод подъема для задачи сетевого планирования, рассмотренной в предыдущем пункте.
1 шаг – задается начальное решение Z0 (начальная расстановка всех 10 рабочих по семи операциям).
2 шаг – свободное число рабочих размещается по следующей схеме:
1. Ставится один рабочий на работу с максимальной трудоемкостью. Эта работа может не принадлежать «критическому» пути.
2. Если есть свободные рабочие, то они размещаются на работы с максимальной трудоемкостью до тех пор, пока все рабочие не будут расставлены.
Пример:
Пусть К01=1, К02=2, К13=1, К24=2, К34=2, К14=1, К45=1.
T(I1)=t01+ t13+ t35=1/1+2/1+4/2=5= Iкр
T(I2)=t01+ t14+ t45=1/1+2/1+1/1=4
T(I3)=t02+ t24+ t45=2/2+3/2+1/1=3,5
Берут рабочего с работы, не принадлежащей «критическому» пути, и ставят на другую работу, которая принадлежит «критическому» пути. Затем анализируют время выполнения всего комплекса работ. Если найдено улучшение, то процесс повторяют до тех пор, пока окажется, что любые перемещения не приводят к улучшению решения.
Условия перемещения рабочих:
1) 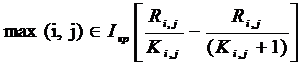
2) Нельзя снимать рабочих с работ, для которых Ki, j=1.
Для заданного примера (0, 2)Ú(2, 4)
(1, 3) ® max[(1/1 - 1/2); (2/1 - 2/2); (4/2 - 4/3)]
Затем проводят перестановку рабочего и пересчитывают длительность выполнения работ на пути.
![]()
Для рассмотренного примера можно показать, что найденное решение является наилучшим.
Пример программы приведён в файле {Listing 3.3}.
3.3 Стратегия «Жадный алгоритм».
«Жадный алгоритм» позволяет получить оптимальный результат в целом. Однако в жизни «жадная» стратегия дает стоимостную выгоду, тогда как общий результат может оказаться неприемлемым.
Примеры «Жадных алгоритмов»:
1) Алгоритм Крускала поиска минимального остовного дерева.
2) Алгоритм Дейкстра поиска кратчайшего пути в неориентированном графе.
3) Модифицированный алгоритм Крускала для задачи коммивояжера.
Задача 3.3.1 Нахождение минимального остовного дерева. {Listing 3.4}
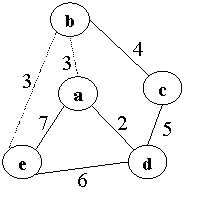 |
S0=7+4+4+5=20
S1=19
S2=16
S3=13
S4=12
Получаем минимальное остовное дерево:
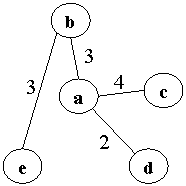 |
«Жадный алгоритм» сначала рассматривает все «свободные» дуги, выбирает дугу с минимальной стоимостью и добавляет ее к остовному графу. При этом получается цикл acd. Затем просматривает все дуги, входящие в цикл, и убирает дугу с максимальной стоимостью.
3.4 Программирование «с отходом назад»
Этот метод (называемый еще методом «поиска с возвратом») позволяет выполнить исчерпывающий поиск требуемого решения задачи без перебора всех возможных вариантов.
Примеры задач, в которых используется данный метод:
1) Поиск кратчайшего пути в графе.
2) Выход из лабиринта.
3) Обход шахматной доски конем.
4) Задача о восьми ферзях.
5) Крестики-нолики.
6) Пятнашки.
7) Задача коммивояжера.
Алгоритмы «поиска с возвратом» наиболее часто представляются в виде рекурсий. Эти алгоритмы ищут решение методом проб и ошибок, перебирая все или почти все варианты, поэтому их называют «лобовыми» алгоритмами. Такие алгоритмы наименее эффективны, чем другие.
Алгоритмы «поиска с возвратом» используются в случаях, когда нельзя применить другие, более эффективные алгоритмы. Поэтому «поиск с возвратом» - это метод на крайний случай. Он всего на один порядок лучше, чем прямой перебор всех вариантов.
Работа алгоритмов «с отходом назад» начинается от искомой цели и движется по направлению к постановке задачи с проверкой условий. При этом возможен обратный возврат от постановки задачи к решению.
Сложность алгоритмов «с возвратом» в худшем случае экспоненциальная, когда для поиска решения приходится просмотреть все варианты.
Общий принцип построения алгоритмов «поиска с возвратом»:
1 шаг: Задается начальное состояние,
2 шаг: Строится дерево решений, возможных для каждого состояния задачи,
3 шаг: Задается целевая функция стоимости решений,
4 шаг: Производится обход дерева с проверкой целевой функции для каждого решения и возвратом назад в корневую вершину с исключением пройденных ветвей дерева.
В результате прохождения графа будет найдено оптимальное решение.
Примечание: Для некоторых задач алгоритм «поиска с возвратом» не требует просмотра всех вариантов, что дает единственно правильное решение.
Задача 3.4.1 Задача обхода шахматной доски конем.
Целевая функция здесь определяет, свободна или занята одна из возможных клеток для последующего хода. Если все возможные решения являются занятыми клетками, то происходит возврат назад и выбор другого варианта решения.
При этом для многих алгоритмов «поиска с возвратом» в дереве всегда выбирают сначала левую ветвь поиска.
Задача 3.4.2 Задача о велосипедном замке.{Listing 3.5}
Замок состоит из N переключателей. Он сработает в том случае, если совпадет кодовая комбинация, в которой не менее N/2 переключателей включены.
Исходя из условия, следует, что множество решений разбиваются на 2 подмножества А и В, где А – правильные решения, В – решения, противоречащие условию.
Количество возможных комбинаций определяется как 2N.
При N £ 10 алгоритм полного перебора дает 210=1024 комбинации.
При N > 10 время поиска растет экспоненциально.
Procedure Code(N: integer);
var i: integer;
j, K: longint;
begin
K:=1;
for j:=1 to N do K:=K*2;
for j:=1 to K do
{проверка совпадения кода}
end;
Если учитывать условие задачи, то из рассмотрения можно исключить большую часть вариантов решения.
Построим дерево решений для алгоритма «поиска с возвратом» при N=4.
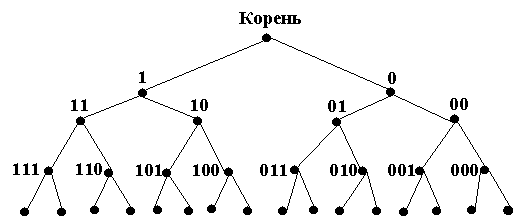 24=16 комбинаций
24=16 комбинаций
16-5=11 возможных решений
Движение вниз по дереву выполняется по левой ветви. На последнем уровне проверяется комбинация. Если замок не открылся – возвращаемся на один уровень вверх и спускаемся по другой, самой левой из нерассмотренных ветвей и т. д.
Примечание: Алгоритмы «поиска с возвратом» в худшем случае перебирают все возможные варианты, хотя существуют модификации этого метода, позволяющие существенно сократить область поиска.
К ним относят:
ü метод ab-отсечений;
ü метод ветвей и границ;
ü использование эвристик, дающих приближенное решение за короткое время, которое принимается за начальное состояние в алгоритме «поиска с возвратом» для поиска точного решения.
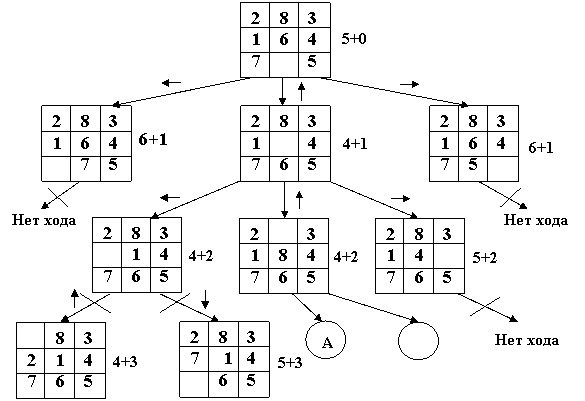
Задача 3.4.3 Игра «Пятнашки».{Listing 3.6}
Зададим сначала приоритет ходов:
1)
2)
3) ®
4) ¯
Дерево решений для алгоритма «с возвратом назад»:
| 3 | |
1 | 8 | 4 |
7 | 6 | 5 |
 2
22 | 3 | |
1 | 8 | 4 |
7 | 6 | 5 |
1 | 2 | 3 |
8 | 4 | |
7 | 6 | 5 |
1 | 2 | 3 |
7 | 8 | 4 |
6 | 5 |
1 | 2 | 3 |
8 | 4 | |
7 | 6 | 5 |
1 | 2 | 3 |
8 | 4 | |
7 | 6 | 5 |
3.5 Эвристики.
Эвристический алгоритм обладает следующими свойствами:
a) Он дает хорошее, хотя и не всегда оптимальное решение.
b) Он работает быстрее и его проще реализовать, чем любой точный алгоритм.
Хотя не существует универсальной структуры, описывающей эвристические алгоритмы, многие из них основаны на других методах:
o «Разделяй и властвуй»;
o подъема;
o обратного отслеживания.
Общий подход к построению эвристических алгоритмов заключается в перечислении всех требований к точному решению и их разделению на два класса:
1. Первый класс включает требования, которые легко удовлетворить.
2. Второй класс включает требования, которые удовлетворить нелегко.
Иными словами, первый класс – это требования, которые обязательно должны быть удовлетворены. Второй класс – требования, по отношению к которым допускается компромисс.
В этом случае цель построения эвристического алгоритма заключается в создании алгоритма, который гарантирует выполнение требований первого класса, и который мог бы выполнить требования второго класса, однако гарантии этому нет.
Часто очень хорошие алгоритмы должны рассматриваться как эвристики. Например, алгоритм, который хорошо работает на всех тестовых задачах, считается эвристикой, пока не будет найдено доказательство его правильности.
Задача 3.5.1 {Listing 3.7}
Рассмотрим использование эвристического алгоритма на примере игры «Пятнашки».
Эвристика определяется по формуле
H=D+L,
где D – число неупорядоченных фигур;
L – уровень дерева.

|
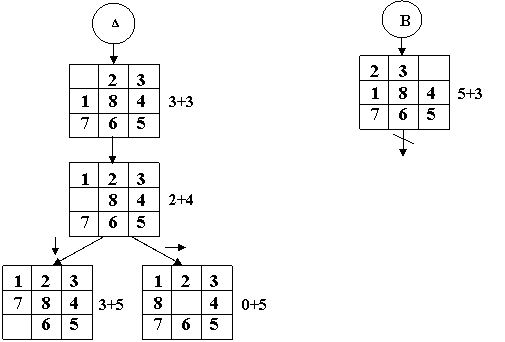 |
Здесь L определяет также число шагов, за которое будет найдено оптимальное решение.
Приведенный алгоритм реализует поиск «в ширину», т. е. рассматриваются альтернативы на одинаковом уровне, а критерий выбора альтернативы – целевая функция, задаваемая эвристикой.
Рассмотренный эвристический алгоритм ведет себя как «Жадный алгоритм». Разница заключается в том, что здесь критерий оптимальности мы задали сами.
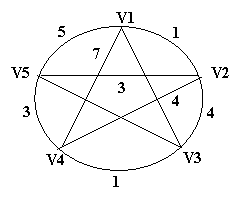
Задача 5.5.2 Задача коммивояжера.{Listing 3.8}
Задан граф связанных городов со стоимостью проезда между городами. Необходимо построить замкнутый путь, связывающий все вершины друг с другом и обладающий минимальной стоимостью.
|

|
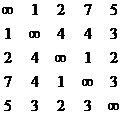
Тур 1: 1 – 5 – 3 – 4 – 2 – 1
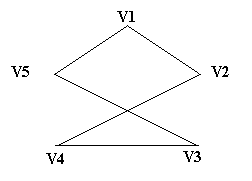 |
S1=13
Рассмотрим «Жадный алгоритм» нахождения минимального пути.
![]() Tour=0
Tour=0
C=0
V=V1
V=
V - текущее время;
V1 – начальное время;
С – стоимость.
1 шаг: Посещение всех городов
for k=1 to N-1 do
2 шаг: Выбираем следующий город W. Далее выбираем ребро, которое при присоединении дает минимальную стоимость.
W, (V, W)=min
Tour=Tour+(V, W)
C=C+CVW
3 шаг: После прохождения цикла
Tour=Tour+(V, U)
получаем следующий путь: 1 – 2 – 5 – 3 – 4 – 1
U=1 C3=1+3+2+1+7=14
Недостаток: на первых итерациях всегда используется ребро с минимальной стоимостью, зато на последних – с максимальной стоимостью.
«Жадный алгоритм» является простым, но не дает оптимального решения. Однако его можно рассматривать как эвристику с учетом следующих положений:
1. Эвристический алгоритм задачи коммивояжера основан на методе подъема с целью нахождения минимального тура.
2. Задача сводится к набору частных целей: найти на каждом шаге самый дешевый город для следующего посещения.
3. Алгоритм не строит плана. Кроме того, в нем нет возврата назад.
4. Оптимальное решение обусловлено двумя основными условиями:
ü множество ребер вместе образует тур без циклов;
ü стоимость тура минимальна по сравнению с другими.
Для эвристического алгоритма свойство 1 является обязательным, а свойство 2 – трудным, что не гарантирует поиск минимума.
Для произвольной задачи с n вершинами требуется сложность алгоритма порядка O(n2), чтобы прочесть матрицу стоимости |S|. Следовательно, можно показать, что для реализации алгоритма требуется не более n2 операций.
Вывод: Эвристический алгоритм решения задачи коммивояжера настолько эффективен, насколько это возможно, и является самым лучшим и широко используемым для больших городов W.
С целью повысить вероятность выполнения условия 2, возможны следующие способы модификации эвристических алгоритмов:
1) Применение алгоритма для любых p£n случайно выбранных городов.
2) Если зададим n=3, то Tour=3 – 4 – 5 – 2 – 1 – 3,
C4=1+3+3+1+2=10, тогда сложность будет кратна O(pn2).
Если зададим n=3, то в качестве ближайшего города n второй наименьший по стоимости изменяющийся W=3.
Кроме того, можно задать ситуацию, когда рассматривается несколько туров и сохраняется минимальный на некотором шаге. Затем рассматривается следующий тур, определяется стоимость асимметричного графа и сравнивается с минимальной стоимостью. Если она больше, то прекращают движение по пути.
3.6 Метод ветвей и границ.
Данный метод является разновидностью поиска с возвратом, поскольку исследует дерево решений и применяется для широкого класса дискретных комбинационных задач. Если алгоритм поиска с возвратом направлен на поиск первого или всех решений для заданного N, то метод ветвей и границ направлен на оптимизацию решения (поиск максимального или минимального решения или в зависимости от критерия оптимальности).
В решаемой задаче задается целевая функция стоимости для любой из вершин дерева поиска с целью найти минимальную конфигурацию стоимости. Для задач коммивояжера такой алгоритм считался самым эффективным до 1970 года, когда были предложены эффективные алгоритмы направления эвристики. При этом эвристический алгоритм решения задачи можно использовать как качественное решение для задачи коммивояжера, решаемой алгоритмом ветвей и границ. Это дает на начальном этапе некоторое приближение к точному решению и сокращает пространство поиска в дереве.
Пример 3.6.1 Задача коммивояжёра {Listing 3.9}
1 этап: В матрице стоимости ищутся сначала минимальные элементы в каждой строке и производится вычитание.
S= 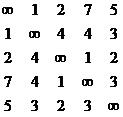
 Получаем:
Получаем: 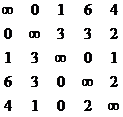
Запоминаем h1= h2= h3= h4=1, h5=2
Затем производится поиск минимальных элементов в каждом столбце и снова производится вычитание:
h6= h7= h8= h9=0, h10=1
 Получаем:
Получаем: 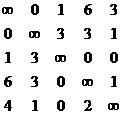 =
= ![]() - приведенная матрица.
- приведенная матрица.
Определим сумму всех hi:
Hi=
Hi является нижней границей стоимости каждого тура для данной вершины графа.
2 этап: В приведенной матрице находим базовый путь в результате поиска строки с номером i, имеющей не менее двух стоимостей, не равных ¥. Среди набора элементов выбираем в качестве базы с наименьшим индексом.
После выбора базы приводим ветвления в графе, т. е. осуществляем построение двух матриц L и R.
Для нашего случая в качестве кандидатов на базовый элемент используются элементы приведенной матрицы R=0:
(S12,, S21, S34,, S35,, S43,, S53 )
среди них выбираем базовый элемент, имеющий максимальную сумму наименьших элементов в той же строке и столбце, что и кандидат.
Пример:
S12=1+1=2
S21=1+1=2
S34=1
S35=1
S43=1
S53=1
В качестве базы берем S12, строим для него L и R.
L получается приравниванием к ¥ всех элементов, стоящих в той же строке и в том же столбце, что и базовый элемент, а также асимметричный ему элемент по индексу.
Т. о. асимметричный базе элемент - S21.
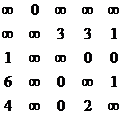 - вершина L первого уровня.
- вершина L первого уровня.
Рассматриваем L1 в качестве исходной, выполняем приведение и поиск базового элемента для получения матриц L2 и R2.
Результат:

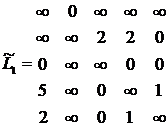
h25=h31=1
H2=1+1=2
H2=H1+H2=7+2=9
H2 – нижняя граница стоимости каждого тура наследия этой вершины.
Получаем матрицы L2 и R2 описанным выше способом и повторяем этот процесс до тех пор, пока не будут достигнуты листья дерева.
Для листа дерева, соответствующего какому-либо туру, в матрице есть только один элемент в каждой строке и в каждом столбце, неравный ¥.
(S25,, S31, S34,, S35,, S43,, S53 )
S25 – база, S52 - ¥; H3=H2+1=9+1=10
Т. о. листок дерева будет иметь вид:
L5=
C12,, C25, C54,,C43,, C31 из первого во второй
2®5 5®4 4®3 3®1 город.
С=1+3+3+1+2=10
Принимаем С за минимум, возвращаемся на 1 шаг назад (в L4) и вычисляем матрицу R5 (2 тур).
Ветви не имеет смысла исследовать, если нижняя граница для всех туров в данной передаче превышает стоимость наилучшего тура (минимума) в данный момент.
Матрицу R получают из исходной заменой базового элемента на ¥, после чего повторяют процедуру поиска так же, как и для левой матрицы L, выбирая новый базовый элемент.
R1:C12=¥; S® ; (C12,, C21, C34,,C35,, C43,,C53, )
C21®2

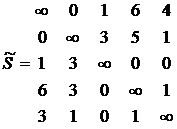
Заменяем на ¥
Заменяем на 0
Вывод: Проверка стоимости туров нижними границами Нi позволяет исключать из рассмотрения большое число ветвей графа, для которых было выявлено, что Нi>min.
Алгоритм ветвей и границ должен оптимизировать точное решение.
3.7 ab-отсечения.
Данный метод используется в игровых задачах, в основном для разработки биматричных игр.
Первый игрок ставит цель максимизировать свой выигрыш на каждом ходе, а второй – минимизировать свой проигрыш. Дерево решений будет строиться на основе двух стратегий: максимума (max) и минимума (min).
Пример 3.7.1: Игра «Крестики-нолики».{Listing 3.10}.
Для нее можно построить полное дерево решений, однако можно не рассматривать множество «плохих» решений и отсекать «плохие» ветви.
Для определения стратегии и значений узлов дерева в этой игре используются следующие варианты:
+1 выигрыш первый игрок.
-1 выигрыш второй игрок.
0 ничья.
Листьями являются полные решения, а узлами – промежуточные состояния.
Зная значение узла, в соответствии с выбранной стратегией либо рассматривают всех потомков этого узла, либо отсекают.
Стратегии max соответствует N-четное, а стратегии min – N-нечетное, где N – порядок узлов дерева.
На первом уровне имеется 9 вариантов возможных комбинаций (поскольку все клетки игрового поля пусты), на втором уровне – 8 возможных комбинаций и т. д. Всего получается 9!=362880 листьев. Из этого числа возможных решений множество листьев дублируют друг друга.
Сложность алгоритма полного перебора O(N!).
Общее правило отсечения узлов связано с понятиями конечных и ориентировочных значений узлов. Конечное значение – это выигрыш в данной ситуации. Ориентировочное значение – это верхний предел значений узлов, находящийся в режиме min (b-значения), или это нижний предел значений узлов в режиме max (a-значения).
b-значения характеризуют стратегию наихудшей обороны, a-значения характеризуют стратегию наихудшей атаки.
Правила определения конечных и ориентировочных значений:
1) Если уже рассмотрены или отсечены все потомки некоторого узла N, то – сделать ориентировочное значение этого узла конечным значением.
2) Если ориентировочное значение узла N в режиме max равно V1, а значение одного из его потомков равно V2, то – установить ориентировочное значение узла N как функцию max(V1, V2). Если узел N в режиме min имеет значение Р1, а его потомок – значение Р2, то – установить ориентировочное значение узла N как функцию min(P1, P2).
3) Если некоторый узел P в режиме min является потомком узла Q в режиме max и ориентировочные значения их равны V1 и V2 соответственно, причем V1>V2, то можно отсечь всех нерассмотренных потомков узла Р.
Можно отсечь нерассмотренных потомков узла Q в режиме max со значением V1, предка узла Р в режиме min, имеющего ориентировочное значение V3, если выполняется условие V3<V1.
Пример 2:
 bN < aN+1
bN < aN+1
Если существует потомок узла N с b-значением в режиме min, расположенный на два уровня ниже, имеющий большее значение, чем значение узла N, то можно отсечь соответствующую ветвь потомков узла N (b-отсечение).
Если существует потомок для узла N с a-значением в режиме max, расположенный на два уровня ниже и aN > bN+1, т. е. его значение может только уменьшить значение предка, то эту ветвь можно отсечь (a-отсечение).
Преимущество данного метода перед методом перебора всех вариантов заключается в отсечении большого числа вариантов. Однако на их число влияет порядок узлов дерева, которое определяет время появления a - и b-отсечений. Чем раньше появляются отсечения в дереве, тем быстрее алгоритм.
3.8 Динамическое программирование.
Метод «Разделяй и властвуй» сводит решение задачи к разделению на несколько простых подзадач и их решению с объединением результатов. Часто не удается разделить задачу на подзадачи, либо в результате разделения получается Nm подзадач с многократным решением одних и тех же подзадач. В результате получается алгоритм с экспоненциальной сложностью.
С точки зрения реализации проще создать таблицу решений всех возможных подзадач. Таблица заполняется лишь однажды, независимо от того, нужна ли какая-либо подзадача для получения общего решения. При повторном обращении к таблице не нужно искать решение подзадач заново.
Метод поиска оптимального решения на основе таблиц, содержащих решения подзадач, называют динамическим программированием (ДП).
Виды алгоритмов ДП могут быть различными. Общей их частью является лишь заполняемая таблица и порядок заполнения ее элементов.
ДП называют процесс пошагового решения задач, где на каждом шаге выбирается единственное решение из множества допустимых, такое, которое оптимизирует заданную целевую функцию.
Здесь процесс решения сводится к пошаговому заполнению таблицы.
Алгоритм ДП вычисляет решения всех подзадач от малых к большим, и ответы запоминаются в таблице. Это не дает сокращения объема задачи, но алгоритм является простым и понятным. Выигрыш по времени достигается лишь за счет исключения повторного решения подзадач.
Алгоритм ДП в худшем случае имеет экспоненциальную сложность для задач со сложностью порядка O(n!).
В теории ДП выделяют 3 аспекта:
1 – теоретический (ДП используется для доказательства теорем существования сходимости и др.);
2 – прикладной (ДП используется для построения модели задач оптимизации);
3 – вычислительный (касается программной реализации).
Основные работы по ДП написаны Беллманом, Венцем и Вагнером.
В основе поиска оптимального решения в алгоритме ДП лежит принцип оптимальности Беллмана:
Оптимальное решение обладает тем свойством, что какими бы ни были начальное состояние и начальное решение, все последующие решения должны быть оптимальной последовательностью решений относительно текущего состояния.
Этот метод дает глобальное оптимальное решение, в отличие от эвристик или «жадного алгоритма». Для ДП решение на каждом шаге должно быть оптимальным с точки зрения процесса в целом.
Класс задач, решаемых алгоритмами ДП, обширен. Задачи различаются как по содержанию, так и по характеру моделей. Наиболее часто ДП используется в экономических задачах оптимизации производства и задачах принятия решений в экспертных системах.
Примеры задач:
1) Задачи оптимального распределения ресурсов.
2) Задачи оптимального управления запасами.
3) Задача реинженеринга (оптимальная стратегия модернизации).
4) Задача оптимального плана производства.
5) Задачи целочисленного линейного программирования.
6) Задачи маршрутизации (сетевые графики, транспортные перевозки).
Пример 3.8.1:Задача коммивояжера.{Listing 3.11}
Исходная задача сводится к набору подзадач. Многошаговый процесс поиска решения (минимизация стоимости тура) сводится к последовательности решений, выбор которых зависит от текущего состояния. Решением каждого шага является город, который нужно посетить следующим.
Целевая функция есть стоимость обхода графа. Применение принципа оптимальности Беллмана к решению этой задачи означает декомпозицию. В начале находится решение всех возможных подзадач, которые используются для отыскания решения более сложных подзадач и т. д. до нахождения решения всей задачи.
Определим параметр T(i; j1, j2, …, jk) как стоимость оптимального маршрута от вершины с индексом i в первую вершину, который проходит каждый город в точности один раз в любом порядке и не проходит через другие города, не принадлежащие подмножеству j.тогда принцип оптимальности приводит к следующей системе рекуррентных соотношений:
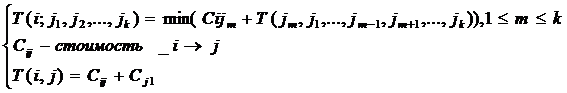
Данная система является рекуррентной, т. к. каждое частное решение рекурсии описывается как покрытие подмножества городов, то возможно 2n подмножеств из n покрытий.
Поэтому верхняя граница сложности 2n ® O(2n), т. е. гораздо лучше, чем алгоритм прямого перебора, сложность которого Oпр(n!).
При n=5 дерево рекурсии выглядит следующим образом:
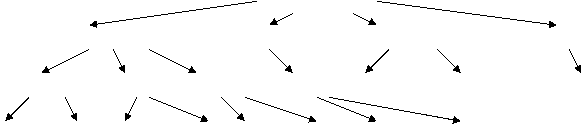 Т(1; 2, 3, 4, 5)
Т(1; 2, 3, 4, 5)
Т(2; 3, 4, 5) Т(3; 2, 4, 5) Т(4; 2, 3, 5) Т(5; 2, 3, 4)
Т(3; 4, 5) Т(4; 3, 5) Т(5; 3, 4) Т(2; 4, 5) Т(2; 3, 5) Т(3; 2, 5) все повторы
Т(4; 5) Т(5; 4) Т(3; 5) Т(5; 3) Т(3; 4) Т(4; 3) Т( 4; 5) Т(5; 4)
Здесь заметно дублирование решений в листьях. Однако дублирование может появляться и в узлах при больших n. Чем раньше они появятся, тем лучше. При этом алгоритм «поиска с возвратом» не позволяет исключать дублирующие ветви и листья, в отличие от ДП.
Пример 3.8.2: Вероятность победы в спортивном турнире.
Две команды (А и В) проводят серию игр до N побед любой из команд. Предполагается, что силы команд равны (Р=0,5). Ничья не допускается.
Пусть Р(i, j) – вероятность того, что для победы команде А нужно провести i матчей, а для победы команды В – j матчей.
Составляется рекуррентное соотношение:
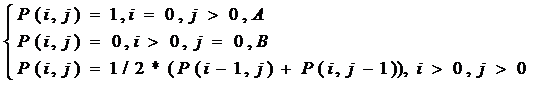
где P(i-1, j) – вероятность выигрыша команды А, если она победит в очередной игре;
P(i, j-1) – вероятность победы А в турнире, если в очередной игре она проиграет.
Для вычисления таблицы вероятностей требуется время £ O(2i+j).
Пусть i+j = n = const.
В этом случае получаем:
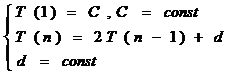
T(n) £ 2n-1*C+(2n-1-1)*d=O(2n) – верхняя граница сложности
i=j ® W(2n/![]() )
)
При этом для вычисления рекурсии нужно находить одно и то же значение P(i, j) несколько раз.
Например, при построении дерева при Р(2, 3) нужно вычислить предварительное значение
Р(2, 3)
Р(1, 3) Р(2, 2)
¯ ¯
Р(1, 2) Р(1, 2)
В методе динамического программирования таблица вероятностей строится, начиная с правого нижнего угла
1/2 | 21/32 | 15/16 | 15/16 | 1 |
11/32 | 1/2 | 11/16 | 7/8 | 1 |
3/16 | 5/16 | 1/2 | 3/4 | 1 |
1/16 | 1/8 | 1/4 | 1/2 | 1 |
0 | 0 | 0 | 0 | - |
Function ODDS (i, j: integer): real;
var S, K: integer;
begin
for S:=1 to i+j do begin
P[0, S]:=1; P[S, 0]:=0;
end;
for K:=1 to S-1 do
P[K, S-K]:=(P[K-1, S-K]+P[K, S-K-1])/2;
Result:=P[i, j];
end;
Сложность всей программы при n=i+j O(n2).
Пример 3.8.3: Произведение матриц.{Listing 3.12}
Пусть требуется вычислить произведение матриц М=М1*М2*М3*…*Мк, где Mi(i-1, j).
Порядок перемножения матриц может существенно влиять на число операций независимо от выбранного метода умножения.
Для перемножения (p; q)*(q; r) потребуется p*q*r операций. В результате получится матрица (p; r).
Рассмотрим конкретный числовой пример:
М=М1(10, 20)*М2(20, 50)*М3(50, 1)*М4(1, 100)
Вычисление произведения этих матриц согласно общим правилам (справа налево) М=М1*(М2*(М3*М4)) потребует 125 тысяч операций.
Умножение другим способом М=(М1*(М2*М3))*М4 потребует 220 тысяч операций.
Однако процесс перебора всех способов перемножения с целью минимизировать число операций имеет экспоненциальную сложность O(2n-1-2), что неприемлемо при больших n.
Алгоритм динамического программирования, дающий метод поиска оптимального произведения матриц, имеет полиномиальную сложность O(n2).
Зададим минимальную стоимость произведения матриц Мi*Мi+1*… *Мj, 1 £ i £ j £ n:
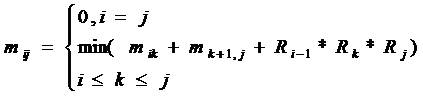
Эта формула дает минимально возможную сложность из набора k значений (i, j-1).
В алгоритме динамического программирования mij вычисляется в порядке возрастания разностей нижних индексов:
mii, " i
mi, i+1 и т. д.
При этом в формуле mik и mk+1, j оказываются ранее вычисленными на момент поиска mij.
Для приведенного примера построим таблицу сложности.
m11=0 | m22=0 | m33=0 | m44=0 |
m12=10000 | m23=1000 | m34=5000 | - |
m13=1200 | m24=3000 | - | - |
m14=2200 | - | - | - |
Алгоритм может быть реализован в виде функции, вычисляющей минимальную стоимость, и выглядящей следующим образом:
Function MinMatrix(N: integer): longint;
begin
for i:=1 to n do m[i, i]:=0;
for l:=1 to n-1 do
for i:=1 to n-1 do
begin
j:=i+l;
m[i, j]:= min(m[i, k]+m[k+1, j]+r[i-1]*r[k]*r[j]);
end;
Result:=m[1, n];
end;
