
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral

 450
450
451
Использование основных объектов конфигурации
Анализ и прогнозирование данных
• 

 среднее значение - среднее арифметическое значений
среднее значение - среднее арифметическое значений
выборки,
• размах - разность между максимальным и минимальным
значением выборки,
• стандартное отклонение - среднее квадратичное отклонение
равное корню квадратному из дисперсии выборки,
• медиана - значение, лежащее в середине выборки
упорядоченной по возрастанию или убыванию. Другими
словами медиана делит выборку пополам; одна половина
выборки имеет значения меньше медианы, другая - больше. В
случае четного числа значений выборки, медиана
рассчитывается как среднее арифметическое двух значений
ближайших к центру выборки.
Для дискретных данных рассчитывается:
• количество значений - общее количество значений,
присутствующих в исходной выборке,
• количество уникальных значений - количество уникальных
значений, присутствующих в исходной выборке,
• мода - значение, наиболее часто встречающееся в исходной
выборке. В выборке могут быть два или более значения, с
максимальной частотой (би - или мультимодальная выборка).
В этом случае в качестве моды будет взято первое найденное
значение с максимальной частотой.
Кроме того, для дискретных значений рассчитывается таблица частот, содержащая следующие показатели:
• частота - количество вхождений уникального значения в
выборку,
• относительная частота - частота, выраженная в процентах
от общего количества значений выборки,
• накопленная частота - сумма частоты значения и частот всех
предыдущих значений выборки,
• накопленная относительная частота - сумма относительной
частоты и относительных частот всех предыдущих значении
выборки.
При выводе отчета при помощи построителя отчета анализа данных, будет создана круговая диаграмма по относительной частоте значений в выборке.
Типы колонок источника данных:
• Не используется - колонка не участвует в анализе,
• Входная - содержит исходные данные для анализа.
Параметры анализа данных при общестатистическом анализе не задаются.
Пример
В |
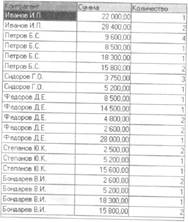
качестве примера общестатистического анализа рассмотрим анализ данных, содержащихся в регистре накопления «Продажи». Для анализа выберем все записи регистра, в которых нас будут интересовать значение ресурсов «Сумма», «Количество» и значение измерения «Контрагент».
Допустим, мы будем иметь следующие исходные данные для
анализа:

 452
452
453
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
|
|
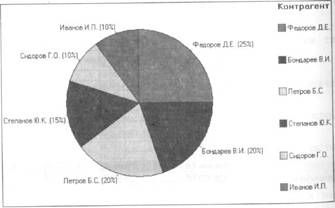
Результат анализа будет выглядеть следующим образом:
Общая статистика
Информация о данных
Количествообьектов: 20
Непрерывные поля
Дискретные поля Контрагент
Количество значений: 20
Количествоуникальных значений; 6
Мода:
|
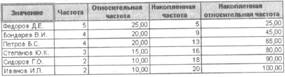
Диаграмма частот |
Таблица частот
Поиск ассоциаций
Т |
ип анализа АнализДанныхПоискАссоциаций предназначен для поиска часто встречаемых вместе групп объектов или значений характеристик, а также выполняет поиск правил ассоциаций. Этот тип анализа может использоваться для определения часто приобретаемых вместе товаров или услуг.
Типы колонок источника данных:
• Не используется - колонка не используется в анализе.
• Объект - колонка содержит объект, например документ
«Оказание услуги».
• Элемент - колонка содержит элемент, например
номенклатуру из документа «Оказание услуги».
Параметры:
• МинимальныйПроцентСлучаев - (Число) - минимальный
процент случаев, в которых наблюдается группа элементов.
Найденные группы, у которых процент случаев меньше, в
отчет включены не будут.
• МинимальнаяДостоверностъ - (Число) - минимальная
достоверность правила. Найденные правила, у которых
достоверность меньше, в отчет включены не будут.
• МинималънаяЗначимостъ - (Число) - минимальная
значимость правила. Найденные правила, значимость которых
меньше, в отчет включены не будут. Значимость правила -
величина, характеризующая насколько правило важно. Чем
выше значимость, тем интересней правило.
• ПоискПоИерархии - (Булево) - необходимость поиска по
иерархии. При помощи этого параметра можно указать
анализу, что необходимо искать ассоциации не только среди
элементов, но и среди групп.
• ТипОтсеченияПравил - (избыточные, покрытые) - тип
отсечения найденных правил. Избыточные - отсекать
избыточные правила, покрытые - отсекать правила, покрытые
другими правилами.
• ТипИсточникаДанных - (объектный, событийный) - тип
источника данных. Анализ работает с двумя типами
источника. Объектный - каждая строка источника содержит

 454
454
455
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
В |
объект с его характеристиками. Событийный - источник данных содержит список событий. Например, состав документа «Оказание услуги».
ИспользованиеЧисловыхЗначений ~ (как булево, как число) как интерпретировать числовые значения. Можно интерпретировать числовые значения как числа или как логические значения, т. е. рассматривать ноль как Ложь, а все остальные ненулевые значения как Истина. ИгнорироватьНезаполненныеЗначения ~ (Булево) - Как использовать незаполненные значения. Т. е. игнорировать их
или нет.
Порядок - (по достоверности, по значимости, по количеству случаев) - определяет порядок отображения данных в результате анализа.
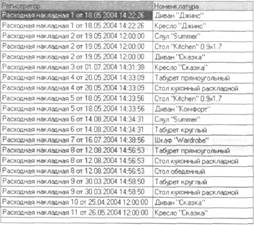
Пример
качестве примера возьмем данные регистра «Продажи»: поле «Регистратор» и измерение «Номенклатура»:

 456
456
457
Использование основных объектов конфигурации
Анализ и прогнозирование
данных
 |
|

Результат анализа будет выглядеть следующим образом:
Поиск ассоциативных правил
Параметры анализа
Минимальный процент случаев:
Минимальнаядостоверность: 60
Минимальная значимость: 0
Отсечениеправил: Избыточные
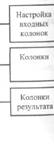
Колонки источника данных Входные колонки
![]()
Информация о данньк
Количество элементов: 12
Количество обьектов: 11
Средиее количество элементов в объекте: 1,82
Результат анализа
Найдено часто встречаемых групп: 4
Найдено ассоциативных правил: 5
|

Часто встречаемые группы
Поиск последовательностей
Т |
ип анализа АнализДанныхПоискПоследовательностей предназначен для выявления в источнике данных последовательных цепочек событий. Например, это может быть цепочка услуг, которые часто последовательно заказывают клиенты.
Поддерживается поиск по иерархии, что позволяет отслеживать не только последовательности конкретных событий, но и последовательности родительских групп.
Набор параметров анализа позволяет ограничивать временные расстояния между элементами искомых последовательностей, а также регулировать точность получаемых результатов.
Типы колонок источника данных:
• Не используется - колонка не используется в анализе.
• Элемент - колонка содержит исследуемый элемент.
Например, в случае исследования продаж, это может быть
колонка, содержащая товар.
• Последовательность - колонка содержащая
последовательности. Например, это может быть контрагент.
• Время - время события.
Параметры:
• МинимальныйПроцентСлучаев - (Число) - минимальное
число последовательностей, в которых должен наблюдаться
шаблон последовательности.
• ПоискПоИерархии - (Булево) - необходимо ли осуществлять
поиск по иерархии.
• МинимальныйИнтервал - (Булево) - признак того, что
установлен минимальный интервал между наблюдаемыми
событиями. Установка минимального интервала означает, что
для того, чтобы элементы попали в искомую
последовательность необходимо, чтобы временной интервал
между элементами был не менее установленного.
• ЕдиницаМинимальногоИнтервала - единица минимального
интервала

 458
458
459
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
В |
КратностъМинималъногоИнтервала - (Число) - кратность минимального интервала
МаксималъныйИнтервал - (Булево) - признак того, что установлен максимальный интервал между наблюдаемыми событиями. Установка максимального интервала означает, что для того, чтобы элементы попали в искомую последовательность необходимо, чтобы временной интервал между элементами был не более установленного. ЕдиницаМаксималъногоИнтервала - единица максимального интервала
КратностъМаксималъногоИнтервала - (Число) - кратность максимального интервала
ИнтервапЭквивалентностиВремени - (Булево) - признак того, что установлен интервал эквивалентности времени между наблюдаемыми событиями. Если установлен интервал эквивалентности времени, то события, временной интервал
между которыми меньше интервала эквивалентности времени
считаются произошедшими в одно время.
ЕдиницаИнтервалаЭквталентностиВремени — единица
интервала эквивалентности времени
КратностьИнтервалаЭквталентностиВремени - (Число) -
кратность интервала эквивалентности времени
Минимальная длина - (Число) - минимальная длина
последовательности.
Порядок - (по длине, по количеству случаев) - определяет
порядок отображения данных в результате анализа.
Пример
качестве примера снова возьмем данные регистра «Продажи»: измерения «Номенклатура», «Контрагент» и поле «Период»:
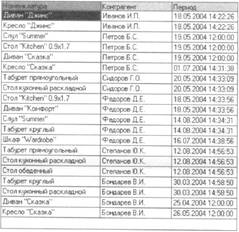
 460
460
461
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 Результат анализа будет выглядеть следующим образом:
Результат анализа будет выглядеть следующим образом:
Поиск последовательностей
Параметры анализа
Минимальный процент случаев: 10
Минимальный интервал:
Максимальный интервал:
Интервал эквивалентности времени:
Минимальная длина последовательности: 2
Информация о данных
Количество элементов: 12
Количество последовательностей: 6
Результат анализа
Найдено последовательностей: 2
Последовательности

Дерево решений
Т |
ип анализа АнализДанныхДеревоРешении дерево решений позволяет построить иерархическую структуру классифицирующих правил, представленную в виде дерева.
Для построения дерева решений необходимо выбрать целевой атрибут, по которому будет строиться классификатор и ряд входных атрибутов, которые будут использоваться для создания правил. Целевой атрибут может содержать, например информацию о том, перешел ли клиент к другому поставщику услуг, удачна ли была сделка, качественно ли была выполнена работа и т. д. Входными атрибутами, для примера, могут выступать возраст сотрудника, стаж его работы, материальное состояние клиента, количество сотрудников в компании и т. п.
Результат работы анализа представляется в виде дерева, каждый узел которого содержит некоторое условие. Для принятия решения к
какому классу следует отнести некий новый объект, необходимо отвечая на вопросы в узлах пройти цепочку от корня до листа дерева, переходя к дочерним узлам в случае утвердительного ответа и к соседнему узлу в случае отрицательного.
Набор параметров анализа позволяет регулировать точность полученного дерева.
Типы колонок источника данных:
• Неиспользуемая - колонка не используется в анализе,
• Входная - колонка будет использоваться как атрибут для
создания узлов дерева, содержит характеристику
исследуемого объекта.
• Прогнозируемая - колонка, содержащая классификацию.
Например - признак того, что контрагент перешел к другому
поставщику.
Параметры:
• МинимальноеКоличествоСлучаев - (Число) - минимальное
количество случаев в узле.
• МаксимальнаяГлубина - (Число) - максимальная глубина
дерева.
• ТипУпрощения - (не упрощать, упрощать) - тип упрощения
дерева решений. Упрощать или не упрощать построенное
дерево решений.
 462
462
463
Использование основных объектов конфигурации
Анализ и прогнозирование данных


 Пример
Пример
Н |
а этот раз мы проанализируем данные справочника
«Контрагенты». В качестве входных колонок мы используем
поля реквизитов справочника
«КоличествоРозничныхТочек», «КоличествоАвтомобилей»
«ВремяРаботыОрганизации» и «ВремяЗаключенияДоговора»' Прогнозируемой колонкой будет поле реквизита справочника «Контрагенты» - «ПрекращениеОтношений».

Результат анализа будет иметь следующий вид:
Дерево решений
Параметры анализа
Минимальноеколичествоэлементов вузле: 0
Максимальная глубина дерева: 1 000
Тип упрощения дерева решений: Упрошать
Колонки источника данных Входные колонки
Имя колонки | Тип данных |
Количест в оРозничныхТочек | Непреры в ный |
Количест во А в томобилей | Непрерывный |
ВремяРаботыОрганизации | Дискретный |
ВремяЗаключенияДоговора | Дискретный |
Прогнозируемые колонки
Имя колонки | Тип данных |
ПрекрашениеОтношений | Дискретный |
Информация о данных
Количество объектов Количество классов:
Результат анализа
Глубина дерева решений: Количество внутренних узлов: Количество листьев' Ошибка, %:
ч 3
3 2
3
11,11
Дерево решений
|


 464
464
465
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
|
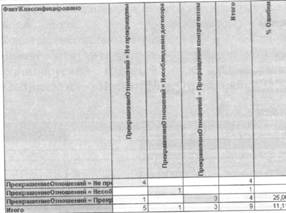
Ошибки кпассиФикзции |
Кластерный анализ
Т |
ип анализа АнализДанныхКластеризация позволяет разделить исходный набор исследуемых объектов на группы объектов, таким образом, чтобы каждый объект был более схож с объектами из своей группы, чем с объектами других групп. Анализируя в дальнейшем полученные группы, называемые кластерами, можно определить, чем характеризуется та или иная группа, принять решение о методах работы с объектами различных групп.
Например, при помощи кластерного анализа можно разделить клиентов, с которыми работает компания на группы, для того, чтобы применять различные стратегии при работе с ними.
При помощи параметров кластерного анализа аналитик может настроить алгоритм, по которому будет производиться разбиение, а также может динамически изменять состав характеристик, учитываемых при анализе, настраивать для них весовые коэффициенты.
Результат кластеризации может быть выведен в дендрограмму специальный объект, предназначенный для отображения последовательных связей между объектами.
Типы колонок источника данных:
• Не используется - колонка не используется при анализе.
• Входная - колонка используется для группирования объектов.
• Прогнозируемая - будет создан прогноз для значения колонки
для каждого кластера.
• ВходнаяИПрогнозируемая - колонка используется как
входная и как прогнозируемая.
• Ключ - ключевая колонка, предназначенная для
идентификации объекта.
Параметры:
• КоличествоКластеров - (Число) - количество искомых
кластеров.
• ТипЗаполненияТаблицы - (все поля, используемые поля,
ключевые поля, не заполнять) - какие поля выводить в таблицу
кластеризации.
• Стандартизация - (не стандартизировать, стандартизировать) -
необходимость стандартизации данных. Если необходимо
стандартизировать данные, то анализатор предварительно
приведет все характеристики объектов к одной весовой
категории.
• МераРасстояния - (ЕвклидоваМетрика,
ЕвклидоваМетрикаВКвадрате, МетрикаГорода,
МетрикаДоминирования) - каким образом вычислять
расстояние между объектами.
• МетодКластеризации - (БлижняяСвязь, ДальняяСвязь,
КСредних, ЦентрТяжести) - каким методом выполнять
кластеризацию.
Пример
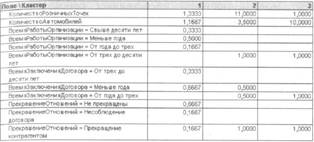
д |
ля анализа мы возьмем те же поля справочника «Контрагенты», что и в предыдущем примере: «КоличествоРозничныхТочек», «КоличествоАвтомобилей»,

 466
466
467
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
|
|

«ВремяРаботыОрганизации» «ПрекращениеОтношений». значение поля «Ссылка»:
«ВремяЗаключенияДоговора» и В качестве ключа мы используем
Центры кластеров
|
Результат анализа будет выглядеть следующим образом:
Расстояния между кластерами
Кластерный анализ
Денрограмма связей
|
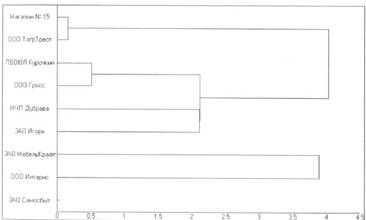
Параметры анализа
Количество искомых кластеров: 3
Стандартизация: Стандартизировать
Мера расстояния: Евклидова метрика в квадрате
Метод кластеризации: Метод центра тяжести
Колонки источника данных Входные колонки

Информация о данных
Количествообъектов: 9
Результат анализа
Найденокластеров: 3

|

 468
468
469
Использование основных объектов конфигурации
Анализ и прогнозирование данных


 Модель прогноза
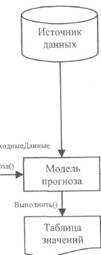
Модель прогноза
О |
бъект модель прогноза представляет собой специальный объект, который создается из результата анализа данных, и позволяет в дальнейшем строить прогнозы для новых данных.
Например, модель прогноза поиска ассоциаций, созданная при анализе покупок клиентов, может быть использована при работе с осуществляющим покупку клиентом, для того, чтобы предложить ему товары, которые он с определенной степенью вероятности приобретет вместе с теми товарами, которые он уже выбрал.
Объект Модель прогноза можно получить из соответствующих объектов результат анализа путем выполнения метода СоздатьМодельПрогноза().
|
|
|

В дальнейшем для модели прогноза можно задать некоторый набор исходных данных и получить результат прогноза в виде таблицы значений.
Источник данных для модели прогноза задается при помощи свойства ИсходныеДанные, а для получения результата прогноза необходимо выполнить метод Выполнить().
Используя соответствующие свойства модели прогноза можно настраивать для нее входные колонки, колонки самой модели и колонки результата.
Кроме этого каждая из моделей прогноза содержит дополнительные свойства, определяемые типом анализа, к которому относится модель прогноза.
Пример
В |
качестве примера мы рассмотрим использование модели прогноза данных при оформлении покупки, выполняемой контрагентом.
Предположим, что периодически проводится анализ данных базы типа поиск ассоциаций, и сохраняется актуальная модель прогноза.
Тогда, при формировании расходной накладной контрагента, мы можем использовать эту модель прогноза для того, чтобы исходя из состава расходной накладной, предложить контрагенту дополнительные товары, которые он, с большой долей вероятности, может приобрести.
Предположим, контрагент оформляет следующую покупку:
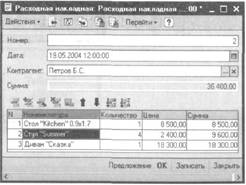
 470
470
471
Использование основных объектов конфигурации
Анализ и прогнозирование данных
 |
 |
|
|
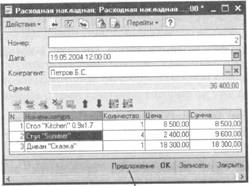
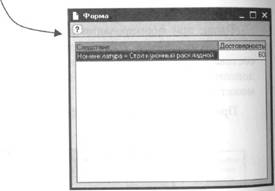
Тогда менеджер, нажав на кнопку «Предложение», может откры список товаров, которые, с большой долей вероятности, также имеет смысл предложить этому клиенту:
Построитель отчета анализа данных
О |
бъект ПостроительОтчетаАнализаДанных позволяет представить данные анализа в виде табличного документа. Структура такого табличного документа определяется типом анализа, для каждого из типов анализа документ будет содержать определенный набор областей.
Объект ПостроительОтчетаАнализаДанных может

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
