
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На i-й итерации решается задача ![]() , при этом для первого перехода
, при этом для первого перехода 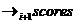 используются те же методы, что и на первой итерации, в таком случае размерность результата будет такой же, как и после первого шага. Для перехода
используются те же методы, что и на первой итерации, в таком случае размерность результата будет такой же, как и после первого шага. Для перехода 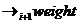 используется опять же указанный ранее способ расчета весов. Таким образом для
используется опять же указанный ранее способ расчета весов. Таким образом для ![]() выход i-го шага и вход i+1-го однородны и совпадают по размерности, следовательно, этот расчет можно замкнуть самого на себя и повторять сколько угодно раз.
выход i-го шага и вход i+1-го однородны и совпадают по размерности, следовательно, этот расчет можно замкнуть самого на себя и повторять сколько угодно раз.
О сходимости и критерии остановки расчета: для анализа сходимости необходимо ввести норму на пространстве решений и определить пороговое значение разности между двумя решениями, полученными на последовательных шагах расчета. В качестве нормы матрицы ![]() можно взять, к примеру, наибольшее значение нормы её столбца, или сумму норм всех столбцов. В качестве нормы столбца – обычную пифагорову длину или максимум модуля его элементов. Тогда ошибка определяется нормой разницы между соседними решениями, если понимать её как поэлементную разность матриц. В число строк матрицы можно включить и вектор весов, если при решении нам важна стабильность расчетных весов методов при переходе к новым итерациям.
можно взять, к примеру, наибольшее значение нормы её столбца, или сумму норм всех столбцов. В качестве нормы столбца – обычную пифагорову длину или максимум модуля его элементов. Тогда ошибка определяется нормой разницы между соседними решениями, если понимать её как поэлементную разность матриц. В число строк матрицы можно включить и вектор весов, если при решении нам важна стабильность расчетных весов методов при переходе к новым итерациям.
Соответственно шаг алгоритма, на котором норма разности результата с предыдущим не будет превосходить некоторого наперед заданного значения, и будет считаться финальным.
Как будет сказано в разделе, посвященном сходимости, существует и другой критерий остановки вычислений, основанный на анализе последовательностей альтернатив, отсортированных по оценке. Этот метод применим, в первую очередь, когда в результате не важны численные значения оценок, а лишь расположение альтернатив среди других (здесь имеется ввиду отношение «лучше-хуже»), а также при большом числе альтернатив, когда этот способ приобретает особую точность.
О целесообразности применения многометодных итерационных алгоритмов: так как в расчетах может участвовать неограниченное число методов, и чем их больше, тем незначительнее влияние каждого отдельно взятого на результат, можно таким образом сравнивать методы между собой по эффективности (например, если требуется доказать или опровергнуть состоятельность новоизобретенного расчетного алгоритма, он может участвовать в расчетах наряду с проверенными, доверительными методами. Оценкой метода в таком случае может быть его вес, назначенный в соответствие с правилом назначения весов на промежуточных итерациях, или просто сравнение результатов, полученных этим методом лицом, принимающим решение или аналогичным расчетным алгоритмом), подготовить набор данных для других расчетных алгоритмов, требующих специфического формата входа. В конце концов, алгоритм, повторяющий вычисления итерационно, да к тому же с применением многих методов, результаты которого в процессе вычислений взаимодействуют друг с другом, претендует на достижение большой точности вычислений за малое число итераций. Таким образом можно «заставить» сходиться алгоритмы, расходящиеся при применении «в одиночку», при этом результат, скорее всего, будет обладать хоть некоторой достоверностью.(В случае расхождения ни о какой достоверности речи не идет).
Алгоритм пересчета весов между итерациями.
1) Вычисляются взаимные индексы критериев ![]() .
.
2) Результаты заносятся в таблицу[2]
Criteria |
|
| … |
|
|
|
|
| |
|
| |||
… | ||||
|
|
|
Ясно, что диагональные элементы равны единице, а все прочие меньше единицы. Таблица вмещает ценную информацию, характеризующую область допустимых значений. Так, если значения каких-то двух столбцов близки для каждой из строк (кроме строк, содержащих единицы в этих столбцах), то два соответствующих критерия сильно зависимы, так как изменения всех иных критериев (кроме этих двух) одинаково влияют на эти два критерия.
Можно выявить также и противоречивые критерии: высокая оценка по одному сопровождается низкой оценкой по другому.
3) По таблице вычисляются индексы (или веса) критериев. Пусть ![]() - среднее значение, взятое по всем элементам i-го столбца, кроме единицы. Тогда
- среднее значение, взятое по всем элементам i-го столбца, кроме единицы. Тогда ![]() - индекс (или вес) i-го критерия – вычисляется по формуле[4]
- индекс (или вес) i-го критерия – вычисляется по формуле[4]
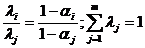
В качестве формулы для вычисления взаимного коэффициента двух критериев можно взять обычное скалярное произведение векторов оценок, полученных соответствующими методами:
![]() .
.
Такая нормировка даст диапазон взаимных индексов как раз [0;1], причем на равных векторах он равен единице, на противоположных – нулю.
Ещё один способ вычислить ![]() - посчитать корреляцию критериев как функций на пространстве альтернатив (Так как критерии после первой итерации соответствуют методам, оценка альтернативы данным методом и будет являться значением функции).
- посчитать корреляцию критериев как функций на пространстве альтернатив (Так как критерии после первой итерации соответствуют методам, оценка альтернативы данным методом и будет являться значением функции).
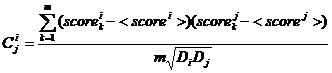 , где
, где ![]() - среднее значение компонент j-го вектора, а
- среднее значение компонент j-го вектора, а ![]() - среднее значение квадрата отклонения компоненты от среднего (попросту, дисперсия).
- среднее значение квадрата отклонения компоненты от среднего (попросту, дисперсия).
Анализ сходимости итерационного процесса
Предлагается рассмотреть сходимость исследуемого итерационного процесса на основе сравнения последовательностей вычисленных результатов (а не на основе «чистых» рейтингов альтернатив, полученных данным методом). Заметим, что такой анализ будет применяться только при исследовании сходимости, но не для составления исходных данных метода.
В примитивном случае мощность множества последовательностей сравнима с ![]() , где n – число участвовавших в процессе альтернатив. Это просто число перестановок n элементов между собой. Но если учесть, что рейтинги могут быть равны (в точности, или при допущении некоторой погрешности/нечеткости в результате), и можно дать несколько первых «мест», то все пространство выходных последовательностей можно представить как n-мерное дискретное, имеющее по каждому измерению ровно n значений, мощность такого множества
, где n – число участвовавших в процессе альтернатив. Это просто число перестановок n элементов между собой. Но если учесть, что рейтинги могут быть равны (в точности, или при допущении некоторой погрешности/нечеткости в результате), и можно дать несколько первых «мест», то все пространство выходных последовательностей можно представить как n-мерное дискретное, имеющее по каждому измерению ровно n значений, мощность такого множества ![]() .Тогда сам результат задается вектором длины n с дискретными значениями от 1 до n. Для таких векторов можно использовать понятия меры (длины) и расстояния, вычисляемых по обычным пифагоровым формулам.
.Тогда сам результат задается вектором длины n с дискретными значениями от 1 до n. Для таких векторов можно использовать понятия меры (длины) и расстояния, вычисляемых по обычным пифагоровым формулам.
Самым, пожалуй, удобным случаем будет случай, в котором начиная с какого-то шага итераций последовательность альтернатив в результате применения метода будет оставаться постоянной (соответствующей конкретной точке пространства). Тогда в сходимости метода сомневаться нет причин, особенно если в результате решения задачи принятия решения нам нужны только соотношения предпочтения между альтернативами (какая «лучше», какая «хуже»), и искомым и единственно существующим решением задачи является эта самая терминальная последовательность.
Чуть более сложной будет ситуация, при которой на соседних шагах с большим номером итераций будут получаться разные последовательности, но «близкие» по норме в пространстве. Некая неустойчивость может быть заложена в самом процессе вычисления, поэтому отвергать метод не стоит. В качестве искомого решения можно выбрать любую из получаемых последовательностей, «близких» к результатам соседних шагов, либо каким-то образом усреднять результат (что тоже не может вывести нас далеко от расчетных решений). Единственная неясность здесь – определение самого понятия «близость», но при большом числе альтернатив можно доверить ЛПР задание разумного порога близости.
Однако, может случиться, что получаемые результаты ни при каких допустимых порогах не будут оставаться в окрестности какой-то точки, могут пробегать совершенно отстоящие друг от друга точки пространства последовательностей с различными частотами на больших номерах шагов. Так как в пространстве векторов, соответствующих последовательностям альтернатив, отсутствуют отношения «больше/меньше», то отдать предпочтение какому-то из получившихся результатов невозможно. К тому же, усреднять в таком случае по пространственной метрике эти решения не имеет всякого смысла.
Для сравнения: пусть на четных шагах процесса первой альтернативе отдается 5-е место, а на нечетных – 1-е. Предположим, что «эффективность» результата решения задачи как функция последовательностей зависит от рейтинга первой альтернативы (от её положения среди других), к примеру, как ![]() , тогда множитель при константе в полученном методом случае равен 4, а при усреднении, если отдать в результате данной альтернативе компромиссное 3-е место, получается (о ужас!) нулевая эффективность. В большей степени это замечание имеет отношение не к обычным задачам выбора лучшей альтернативы, а, например, к расстановке приоритетов при запуске новых проектов компании. В таком случае далекие друг от друга, может быть, даже противоположные последовательности дадут оптимальный результат, в то время как попытка усреднить эти последовательности приводит к провалу.
, тогда множитель при константе в полученном методом случае равен 4, а при усреднении, если отдать в результате данной альтернативе компромиссное 3-е место, получается (о ужас!) нулевая эффективность. В большей степени это замечание имеет отношение не к обычным задачам выбора лучшей альтернативы, а, например, к расстановке приоритетов при запуске новых проектов компании. В таком случае далекие друг от друга, может быть, даже противоположные последовательности дадут оптимальный результат, в то время как попытка усреднить эти последовательности приводит к провалу.
Но никто не запрещает в таком случае объявить о наличии нескольких «неблизких» результатов. Если мы будем фиксировать частоту появления того или иного результата на очередном шаге, отнесенное к номеру текущего шага, то при больших n, ( а в пределе при ![]() ) получим некое подобие вероятностного пространства, где каждому элементарному событию соответствует конкретная последовательность альтернатив, получившаяся в результате применения данного метода, а вероятности этого события – относительная эффективность конкретной последовательности.
) получим некое подобие вероятностного пространства, где каждому элементарному событию соответствует конкретная последовательность альтернатив, получившаяся в результате применения данного метода, а вероятности этого события – относительная эффективность конкретной последовательности.
1) Эту сетку вероятностей можно предоставить ЛПР для выбора оптимального решения (тут сыграть может даже простое большинство, особых усилий от самого ЛПР не требуется),
2) либо объявить какой-то порог сравнимости и выдать несколько последовательностей как неразличимые, «одинаково оптимальные» в решении данной задачи,
3) либо назначить правило отбора эффективных решений,
4) либо сузить число альтернатив, отбросив заведомо неэффективные (или оставив только наиболее эффективные, если это возможно по результату), и начинать решение снова.
В любом случае правило, принятое к применению в случае возникновения такой сложной ситуации с «далекими» эффективными последовательностями, без затрат сужается на первый и второй случай, так что можно изобрести универсальный способ определения условий сходимости (пусть в общем виде очень сложный), который на некоторых наборах данных будет сводиться к чему-то очень простому, даже без участия ЛПР.
Число итераций, которой необходимо выполнить перед окончательным принятием решения, можно рассчитать на основе теории принятия статистических гипотез. Рассматриваемая сетка частот появления в результате той или иной последовательности, если ее рассматривать как вероятностное пространство, позволяет построить подходящую статистическую модель и рассчитать необходимые параметры.
К преимуществам этого способа анализа сходимости стоит отнести следующее:
1) Если в результате применения метода получаются несколько эффективных решений исходной задачи, они все будут продемонстрированы ЛПР вместе с их «приоритетами» (иначе, степенью эффективности). Отбрасывать то или иное решение из-за отклонения от сходимости не приходится.
2) вплоть до последнего шага процесс полностью автоматизирован, от ЛПР не требуется контролировать каждую итерацию, и его участие на решающем этапе сведено к минимуму.
3) В простых (более-менее) задачах, все-таки, сходимость будет ограничиваться первым случаем, когда начиная с какого-то времени последовательности результатов не будут меняться при переходе от одного шага к другому.
4) Относительно просто работать с дискретными последовательностями, для этого потребуется ограниченный объем памяти, несложные вычисления и довольно примитивный математический аппарат
Нельзя закрывать глаза и на недостатки:
1) Если в методе изначально есть предпосылки к неопределенности, и небольшие изменения промежуточных данных будут приводить к серьезным отклонениям в области результатов, решения получатся слишком «размазанными» по всему пространству последовательностей, будет трудно (или даже невозможно) выделить те из них, которые наиболее эффективны.
2) Невозможно избавиться от участия ЛПР.
3) При анализе дискретных последовательностей можно потерять некоторую информацию о решении, которая извлекается из непрерывных результатов работы метода. Непрерывный анализ дает более точные результаты.
Пара слов о непрерывном анализе:
В вещественных пространствах результатов гораздо сложнее пришлось с определением понятия «расстояния», «близости», «окрестности», это потребовало бы априорного знания многих параметров применяемого метода (как то: разброс шкалы значений, минимальные, максимальные отклонения результатов от среднего и т. д.)
К тому же, при использовании непрерывных оценок ещё больше велика вероятность совершить ошибку и усреднить результаты по всем итерациям. Как было показано в примере, это может приводить к катастрофическим результатам.
Промежуточные оценки (сводку, статистику по ним) можно предоставлять ЛПР в качестве вспомогательной информации, если возникнут трудности с принятием решения на основе анализа последовательностей.
Программная реализация
Расчеты в данной работе произведены с использование языка Java и библиотеки классов AbstractMath, предназначенной для решения разнообразных задач. Все вычислительные алгоритмы оформлены в виде отдельных классов, реализующих стандартные интерфейсы, описанные в AbstractMath. Это позволяет использовать реализованные алгоритмы в различных средах. Отличительной особенностью является, то, что для операций над числами используются не стандартные классы из Java API, а специальный интерфейс Number, описанный в AbstractMath, что позволяет, создавая различные реализации этого интерфейса, работать с разными типами чисел, практически не меняя алгоритмы. В данной работе используются две разновидности чисел: ScalarNumber – действительные числа, FuzzyNumbers – нечеткие числа. Причем для нечетких чисел есть различные реализации: GaussianNumber и TriangleNumber, описывающие нечетки числа с разными функциями принадлежности.
Так как целью работы является построение наиболее универсальной автоматической системы, за основу взято J2EE приложение, установленное на Web-сервере Sun Application Server. Исходные данные о задачах, методах и алгоритмах вводятся на формах ввода Web-приложения, или же импортируются в файлах специального формата. Для хранения используется база данных Oracle XE, установленная на том же сервере. В качестве модели данных выбрана объектно-ориентированная метамодель, подобная используемой в NetCracker.
Метамодель выбрана для обеспечения наибольшей универсальности приложения, чтобы на этапе построения и формализации задачи не задумываться о структуре таблиц, типах данных, настройке запросов и формате ввода/вывода. Всё это в самом общем виде реализовано на уровне приложения, и взаимодействие с такой моделью происходит через дружественный интерфейс html-страниц.
Структура данных представлена на следующей схеме:
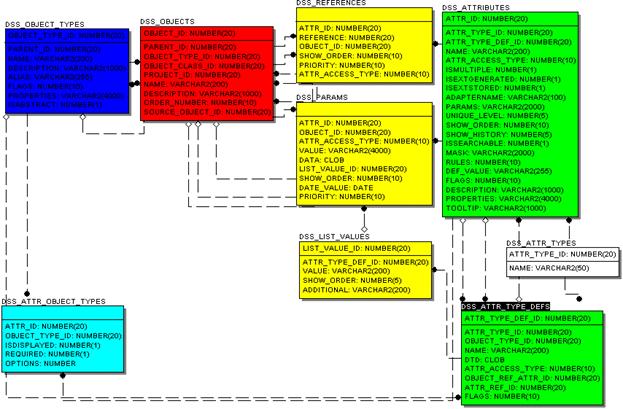
Таблица DSS_OBJECTS используется для хранения абсолютно всех объектов, так или иначе задействованных в процессе расчетов. Здесь находятся имена, описания, информация о связях типа parent-child, и ссылка на объектный тип.
DSS_OBJECT_TYPES перечисляет все объектные типы, которым могут принадлежать объекты. Объектный тип определяется именем, описанием, положением в parent-child-иерархии, косвенно определяет принадлежность тех или иных атрибутов объектам.
DSS_ATTRIBUTES содержит информацию об атрибутах объектов, их типе, способе вычисления (в случае калькулируемых типов), о возможности редактировать значение атрибута, о необходимости отображения соответствующего значения на форме.
DSS_PARAMS, DSS_REFERENCES содержат непосредственно значения параметров объектам по соответствующим атрибутам (PARAMS для простых типов, REFERENCES для ссылочных). Эти таблицы имеют наибольший объем данных среди остальных.
DSS_ATTR_OBJECT_TYPES связывает объектные типы с атрибутами, которые данному объектному типу принадлежат.
Такая модель обладает большой гибкостью по отношению к формату хранящихся данных (так как любые отношения, будь то иерархии, внешние ключи хранятся в виде записей в соответствующих таблицах), к изменению их структуры (если меняется модель внешних данных, нет необходимости изменять структуру таблиц, достаточно лишь внести соответствующие изменения об атрибутах, объектных типах, их связях), к типам данных (ссылки, даты, числа, строки, даже перечислимые значения (LIST_VALUES) равноправны). Несмотря на кажущуюся сложность, модель доказала свою состоятельность. В реализованном J2EE приложении пользователь даже не подозревает о наличии подобной модели, для него данные представляются так, как если бы за этим лежала обычная реляционная структура таблиц.
На основе изложенной структуры создана специфическая для нашей задачи модель данных, описывающая систему принятия решений. Схема модели имеет следующий вид:
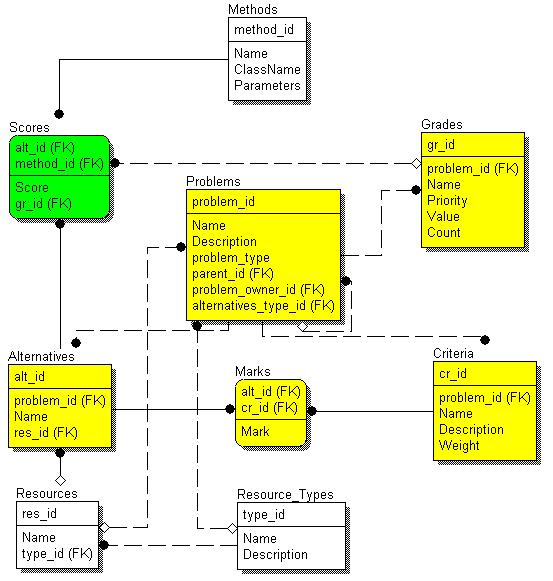
Problems, Marks, Criteria, Scores, Methods – это и есть сущности, используемые в описании алгоритмов в данной работе. Resources, Resource_types, Grades в данный момент не применяются, но были включены в структуру для дальнейшей возможности расширять круг решаемых проблем (например, проблема группового ранжирования – разбиение альтернатив на группы). В том или ином виде эти сущности в данный момент полностью описаны в рамках изложенной метамодели, в таблицах DSS_OBJECT_TYPES, DSS_ATTRIBUTES, DSS_OBJECTS находятся соответствующие записи.
Описание взаимодействия функционала системы принятия решения с базой данных, а так же с Web-браузером на стороне пользователя слишком громоздко, поэтому имеет смысл привести лишь несколько опорных моментов.
Основные классы, используемые в работе можно изобразить на UML диаграмме, что бы показать взаимоотношения между ними:
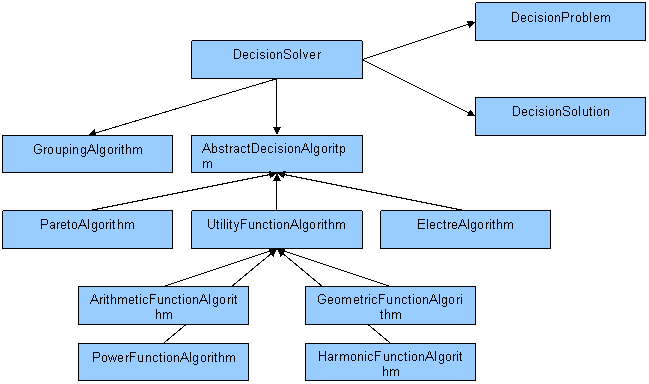

При решении проблемы выбора с помощью Decision алгоритмов структура классов тривиальна: объект решателя с помощью алгоритмов ранжирования (DecisionAlgorithm) и группировки создает объект решения (DecisionSolution), при этом все вычисления делегируются непосредственно алгоритмам.
В случае когда для решения проблемы применяются алгоритмы, основанные на предпочтении (неважно для нечетких чисел или нет), структура классов заметно усложняется:
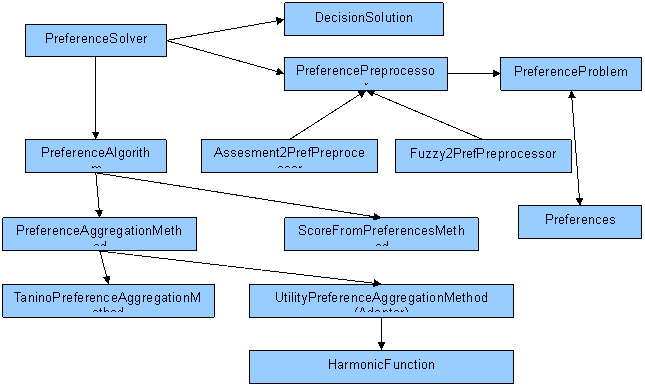

Основным отличием здесь является то, что решение происходит в 3 этапа:
- С помощью какого-либо из Preprocessor исходный объект проблемы DecisionProblem преобразуется в объект класса PreferenceProblem, который содержит в себе набор матриц предпочтений между альтернативами отдельно для каждого критерия (объект Preferences) PreferenceSolver c помощью PreferenceAlgorithm решает эту задачу:
· С помощью одного из PreferenceAggregationMethod производится агрегация предпочтений, т. е создание одной матрицы предпочтений между альтернативами. В этом месте происходит переход от многокритериальной задачи к однокритериальной.
· C помощью одного из методов ScoreFromPreferenceMethod вычисляется конечный рейтинг альтернативы
· PreferenceSolver создает объект DecisionSolution.
Таким образом, алгоритмы, основанные на предпочтениях, представляют собой один обобщенный алгоритм, который можно параметризовать различными методами: подготовки матриц предпочтений (Preprocessor), агрегации предпочтений (PreferenceAggregationMethod) и вычисления рейтингов (ScoreFromPreferenceMethod), получая при этом различные алгоритмы.
Начальная информация о задаче из базы данных заносится в виртуальную машину Java, затем, после того, как пользователь запустит процесс расчета, нажав соответствующую кнопку Calculate, начинается итерационный процесс. Для наглядности ниже приведен фрагмент кода программы:

Как видно из кода, сначала в цикле по методам задача решается каждым из предложенных методов «простым» итерационным алгоритмом (sovleSimple()), причем условие выхода из цикла – достижение необходимой точности либо превышение порога допустимого числа итераций. Затем результат сохраняется в базу (storeResult()), предложенная задача решается один раз многометодным алгоритмом (solve()), и затем вступает цикл уже по итерациям многометодного итерацонного алгоритма (execute()). Все необходимые промежуточные и конечные данные сохраняются в базу внутри перечисленных методов, либо же в завершение всего процесса.
Результаты
Задача выбора оптимальной схемы подключения клиента в операторе связи
Вступление
В задаче ниже предлагается рассмотреть три наиболее популярные в настоящее время технологии доступа last mile:
1. HFC (Hybrid fiber-coaxial) В настоящее время очень динамично развивающаяся технология. Примером оператора, дающего доступ по HFC является бельгийский Telenet.
2. xDSL (его разновидности ADSL, ADSL2+, VDSL, VDSL2, SHDSL, etc) Данная технология является одной из наиболее распространенных и, ввиду дешевизны развертывания, удобной для Service Provider’а.
3. FTTx (его разновидности FTTH, FTTB, etc) FTTH на данный момент получает всё большую и большую популярность из-за высокой пропускной способности (несмотря на высокую стоимость развертывания и обслуживания сетей).
Описание бизнес-кейса и формальных критериев оценки
Пользователь OSS-системы сначала выясняет параметры расположения кастомера, обычно таким параметром является ZIP-код. По этому коду с помощью homing таблиц определяются возможные варианты подключения. Таким образом, на первом же шаге отсекаются принципиально невозможные варианты. Оставшиеся варианты «скармливаются» разрабатываемой нами системе многокритериального ранжирования. Со стороны пользователя системы это выглядит как стандартная для многих провайдеров операция, называемая Feasibility Check.
Формальные критерии
Рейтинг аксеса (от 0 до 3) – это число показывает индивидуальный рейтинг типа подключения, связанный например, с политикой компании, продвигающей ту или иную технологию.
Стоимость деплоймента сети до кастомера - данный критерий достаточно специфический и потребует некоторых исследований для уточнения. Однако среди указанных технологий по убыванию стоимости типы аксеса можно расположить в следующем порядке: FTTH, HFC, xDSL. FTTH лидирует с большим отрывом
Bandwidth – чем больше, тем лучше - случай, когда пропускной способности канала будет недостаточно для сервисов, заказанных кастомером, здесь не рассматривается, поскольку обычно такого рода несостыковки отслеживаются системой заказа сервисов. То есть имеется в виду, что если есть две технологии, одна из которых дает 10 Mbps, а другая 25, то выигрывает вторая. Для указанных выше технологий стандартные теоретические значения пропускной способности выглядят следующим образом:
FTTH: ~52 Mbps
HFC: ~25 Mbps
ADSL: ~8 Mbps
ADSL2: ~12 Mbps
ADSL2+: ~24 Mbps
Данные значения очень сильно коррелируют с критерием ниже. Чем хуже связь, тем хуже bandwidth, количественные оценки часто определяются экспериментальным путем.
Качество и длина кабеля от Network Access Point до дома кастомера - например, в случае xDSL – это расстояние от DSLAM до распределительного щитка в доме. Вообще, данный параметр обычно берется из внешних систем, хранящих подобного рода информацию о кабелях. Поэтому его можно отнести к разряду «трудно добываемых», однако важных, поскольку он влияет на значение bandwidth. Особенно сильно данный параметр влияет в xDSL технологии, так как обычно используется существующая кабельная инфраструктура не всегда хорошего качества.
Анализ критериев
Количественная оценка второго и последнего критериев требует более глубокого исследования, однако в целом картина приоритетов каждого из указанных критериев выглядит следующим образом:
Рейтинг аксеса важен примерно также, как и стоимость деплоймента сети. Перекос в одну или другую сторону зависит от политики каждой конкретной компании. За ними следуют критерии качества и после - Bandtwidth
Расчеты
Начальные данные формализованной задачи подавались на вход разработанной DSS-системе. При этом сначала она решалась каждым программно реализованным методом с помощью первого, «простейшего» расчетного алгоритма, с пересчетом весов исходных критериев между итерациями, затем – «базовым» итерационным процессом, с применением совокупности всех этих методов.
На первом этапе расчетов среди методов были три, основанные на функции полезности (арифметической, степенной, гармонической и геометрической), один метод типа «голосования» (метод Борда) и метод ELECTRE. Ниже приведены две таблицы, соответственно, первая демонстрирует результат решения «одиночными» методами, вторая – итог расчетов «базовым» многометодным алгоритмом.
ALTERNATIVE | Ariithmetic Function Algorithm | Electre Algorithm | Harmonic Function Algorithm | Power Function Algorithm |
1.1 HFC (Hybrid fiber-coaxial) | 0.6104 | 0.5774 | 0.5493 | 0.4976 |
1.2 xDSL | 0.6639 | 0.5774 | 0.5247 | 0.8245 |
1.3 FTTx | 0.432 | 0.5774 | 0.6503 | 0.2696 |
ALTERNATIVE | Borda | Ariith metic | Geo metric | Electre | Harmo nic | Power Function | Summary |
1.3 FTTx | 0.8018 | 0.9933 | 1 | 1 | 1 | 0.9994 | 0. |
1.2 xDSL | 0.5345 | 0.1029 | 0 | 0 | 0 | 0.0344 | 0. |
1.1 HFC (Hybrid fiber-coaxial) | 0.2673 | 0.0519 | 0 | 0 | 0 | 0.0088 | 0. |
Число итераций многометодного алгоритма равно 5, финальная погрешность ~0.005.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
