


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Существуют разные методы:
1. использование сгенерированного адреса в качестве начальной точки для последовательного просмотра. С этого адреса начинается поиск свободного места в памяти
2. сгенерированный адрес считается при этом адресм хранения не одной конкретной записи, а области памяти, в пределах которой размещаются все записи, получившие этот адрес. В пределах страницы записи могут размещаться в последовательном порядке поступления. Если со временем структура окажется заполненной, в памяти выделяется новая страница, связываемая с предыдущей указателем. Хэш-функция может генерировать абсолютный адрес страницы и ее номер.
36. Плотный, неплотный индекс
Индексные файлы можно представить как файлы, состоящие из двух частей. Индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. В зависимости от организации индексной и основной областей различают 2 типа файлов – с плотным индексом и неплотным.
Файлы с плотным индексом
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура записи в ней имеет следующий вид:
![]()
Значение ключа – значение первичного ключа
Номер записи – порядковый номер записи в основной области.
В этих файлах для каждой записи в основной области существует запись одна запись из индексной области. Все записи в индексной области упорядочены по значениям ключа.
Схематично это можно представить следующим образом:
Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны 2 решения:
1. перестроить заново индексную область
2. организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи
Первый способ требует дополнительного времени на переработку индексной области.
Второй способ увеличивает время на доступ к произвольной записи и требует организации дополнительных ссылок на область переполнения.
Файлы с неплотным индексом
Неплотный индекс строится для упорядочения файлов. Структура записей индекса для таких файлов имеет следующий вид
 |
В индексной области ищется блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет определить, в какой области находится искомая запись, а остальные действия происходят в основной области. В случае плотного индекса после определения местонахождения искомой записи, доступ к ней осуществляется прямым способом, поэтому этот способ организации индекса называется индексно-прямым.
В случае неплотного индекса после нахождении блока, где расположен запись, поиск внутри блока требуемой записи происходит последовательным просмотром. Поэтому этот способ называется индексно-последовательным.
37. Инвертированные списки
Часто приходится проводить операции доступа по вторичным ключам. Для обеспечения ускорения доступа по вторичным ключам, используются структуры, называемые инвертированными списками.
Инвертированный список (в общем случае) – двухуровневая индексная структура. На первом уровне находится файл или часть файла, где упорядочено расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значению вторичного ключа. На третьем уровне находится основной файл. Для одного основного файла может быть создано несколько инвертированных списков по разным значениям вторичного ключа.
Инвертированный список по номеру группы для списка студентов
1-ый уровень 2-ой уровень
Ключ | № блока |
100 |
|
200 |
|
300 | 5 |
 3
3Блок 1 |
|
4 |
21 |
25 |
Блок 2 |
31 |
34 |
40 |
|
5 |
|
 1
1№ записи | ФИО | № группы |
1 | Иванов | 100 |
2 | Петров | 300 |
3 | Сидоров | 300 |
4 | Андреев | 100 |
5 | Михайлов | 200 |
6 | Николаев | 300 |
7 | Борисов | 200 |
38. Модель «клиент-сервер» в технологии БД.
Вот теперь пришло время разобраться, что же такое модель КЛИЕНТ-СЕРВЕР? И понять, как вообще работают серверы баз данных основанных на этой модели.
Технология клиент-сервер означает такой способ взаимодействия программных компонентов, при котором они образуют единую систему. Как видно из самого названия, существует некий клиентский процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет. Совсем необязательно, чтобы они находились на одном компьютере. Обычно принято размещать сервер на одном узле локальной сети, а клиентов – на других узлах.
В контексте базы данных клиент управляет пользовательским интерфейсом и логикой приложения, действуя как рабочая станция, на которой выполняются приложения баз данных. Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных на языке SQL или другом языке базы данных, соответствующем логике приложения. Затем передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю. Сервер принимает и обрабатывает запросы к базе данных, после чего отправляет полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, а также выполнение запроса и обновление данных. Помимо этого поддерживается управление параллельностью и восстановлением.
Архитектура клиент-сервер обладает рядом преимуществ:
- обеспечивается более широкий доступ к существующим базам данных; повышается общая производительность системы: поскольку клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно. Настройка производительности компьютера с сервером упрощается, если на нем выполняется только работа с базой данных; снижается стоимость аппаратного обеспечения; достаточно мощный компьютер с большим устройством хранения нужен только серверу – для хранения и управления базой данных; сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к базам данных, что позволяет значительно сократить объем пересылаемых по сети данных; повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку лишь на нем определяются и проверяются все ограничения. При этом каждому приложению не придется выполнять собственную проверку; архитектура клиент-сервер естественно отображается на архитектуру открытых систем.
Дальнейшее расширение двухуровневой архитектуры клиент-сервер предполагает разделение функциональной части прежнего, "толстого" (интеллектуального) клиента на две части. В трехуровневой архитектуре клиент-сервер "тонкий" (неинтеллектуальный) клиент на рабочей станции управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третий уровень – сервер базы данных. Эта трехуровневая архитектура оказалась более подходящей для некоторых сред – например, для сетей Internet и intranet, где в качестве клиента может выступать обычный Web-браузер.
39. Модель файлового сервера
или модель DDM
File Server – FS
Здесь presentation logic и business-logic располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами находятся на клиенте. В этой модели файлы базы данных хранятся на сервере. Клиент обращается к серверу с файловыми командами, а механизм управляет всеми информационными ресурсами, база мета данных на клиенте.
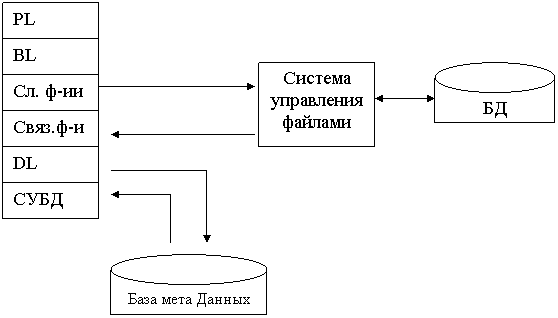 |
Файловые команды
Блоки данных
Достоинства: имеет разделение монопольного приложения на 2 взаимодействующих процесса. Сервер может обслуживать множество клиентов.
Недостатки: высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов. Небольшое количество операций манипуляций с данными, которые определяются только файловыми командами. Отсутствие средств безопасности доступа к данным. Защита только на уровне файлов
40. Модель удаленного доступа к данным (достоинства и недостатки).
(Remote Data Access)
База данных хранится на сервере. Там же находится ядро СУБД. На клиенте располагается Presentation Logic и Business Logic.
 |
SQL запрос
Результат запроса
Стандарт – язык SQL
Достоинства: унификация интерфейса клиент-сервер. Резко уменьшается загруженность сети. Сервер базы данных загружается целиком операциями обработки данных запросов и транзакций.
Недостатки: так как в этой модели на клиенте располагается презентационная и бизнес логика, то при повторении аналогичных функций в разных приложениях код бизнес логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование информации. Сервер в этой модели пассивен.
Функции управления информационными ресурсами выполняются на клиенте, что усложняет клиентское приложение.
Запросы на SQL могут существенно загрузить сеть при интенсивной работе.
41. Модель сервера БД (достоинства и недостатки).
Чтобы избавиться от недостатков RDA модели должны соблюдаться следующие условия:
1. Необходимо, чтобы БД отражала текущее состояние, которое определяется не только данными, но и связями между объектами или данными. То есть данные, хранящиеся в бд в каждый момент времени должны быть непротиворечивыми.
2. Постоянный контроль за состоянием БД
3. Контроль за типами данных.
Данную модель поддерживает большинство современных СУБД.
Основа данной модели – механизм хранимых процедур, как следствие программирования СКЛ сервера. Механизм триггеров, как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки данной структуры.
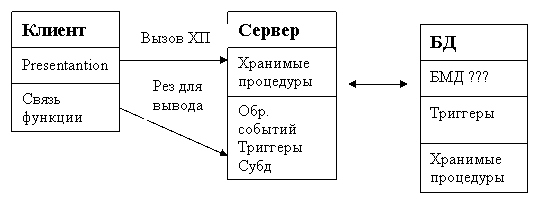

В этой модели Business logic разделены м/у клиентом и сервером. На сервере – хранимые процедуры. Клиентское приложение обращается к серверу с командой запуска ХП. Механизм использования триггера предполагает, что если сработает один триггер, то можно вызвать срабатывание других триггеров.
В данной модели сервер является активным, так как не только клиент, но и сам сервер исп механизм триггеров – может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся с БД и могут быть использованы несколькими клиентами, что уменьшает дублирование обработанных данных.
Достоинства: трафик обмена информацией между клиентами сервера резко уменьшается.
Недостатки
Очень большая загрузка сервера. Сервер обслуживает множество клиентов и выполняет следующие функции:
1. Обеспечивает срабатывание триггера, если появилось связанное с ним событие
2. Обеспечивает мониторинг событий, связанных с триггерами.
3. Запускает хранимые процедуры по запросу.
4. Запускает ХП из триггеров.
5. Возвращает требуемые данные клиенту
6. Обеспечивает все функции СУБД(доступность данных, контроль, поддержка целостности)
Для разгрузки – предложена 3 уровневая модель.
42. Модель сервера приложений (достоинства и недостатки).
Application Server
AS – расширение двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот уровень содержит один или несколько серверов-приложений. В этой модели компоненты – приложения делятся между тремя исполнителями.
Клиент – обеспечение логики представления (графический, пользовательский интерфейс). Клиент исполняет коммуникационную функцию, которая обеспечивает доступ клиенту в локальную или глобальную сеть. Когда клиент также является клиентом менеджера распределенных транзакций, он включает в себя управление распределенными транзакциями. Сервер приложений и использует наиболее общие правила BL, поддерживает каталог с данными. Обеспечивает обмен сообщениями и поддержку запросов (в распределенных транзакциях) – новый промежуточный уровень архитектуры. Сервер базы данных выполняет только функции СУБД. Поддерживает целостность реляционной базы данных, обеспечивает функции хранилищ базы данных, функции создания и ведения баз данных, создает резервные копии баз данных, управляет выполнением транзакций.
Эта модель обладает большей гибкостью, чем двухуровневая модель
Достоинства: разделение функций приложения на 3 независимые составляющие
Недостатки: более высокие затраты ресурсов компьютеров на обмен информацией между компонентами приложения по сравнению с двухуровневой.
Более сложные схемы взаимодействия:
Например, схемы, в которых элемент, являющийся сервером для некоторого клиента, в свою очередь выступает в качестве клиента по отношению к другому серверу.
 |
Возможен также вариант, когда 1 объект по отношению к одним является клиентом, а по отношению к другим – сервером.
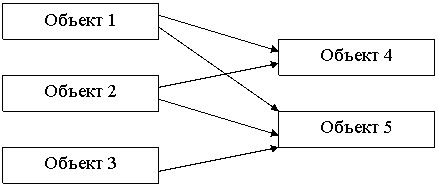 |
В процессе работы роли объектов могут меняться.
Наиболее гибкая и универсальная AS модель.
43. Транзакции (свойства, способы завершения, журнал).
Транзакция – последовательность операций, производимых над базой данных и переводящих базу данных из одного непротиворечивого состояния в другое.
Типы транзакций:
Плоские (классические) Цепочечные ВложенныеПлоские:
Характеризуются четырьмя классическими свойствами.
Атомарность (Atomicity) Согласованность (Consistency) Изолированность (Isolation) Долговечность (Durability)Атомарность (Atomacity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
Согласованность (Consistency) гарантирует, что по мере выполнения транзакций, данные переходят из одного согласованного состояния в другое. Транзакции не разрушает взаимной согласованности данных.
Изолированность (Isolation) гарантирует, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно изолированно друг от друга, но для пользователя выглядят так, как будто выполняются параллельно.
Долговечность (Durability): если транзакция завершена успешно, то те изменения в данных, которые были произведены, не могут быть потеряны ни при каких обстоятельствах, даже в случае последующих ошибок.
Возможны 2 варианта завершения транзакции:
Фиксация – действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. Это значит, что результаты выполнения транзакции станут видимы другим пользователям. Откат – действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.Модель транзакции(рисунок):
Транзакция начинается с первого SQL оператора. Последующие составляют тело транзакции. Commit выполняется в случае успешного завершения обработки информации, объединенной в транзакцию. Его выполнение фиксирует изменения, внесенные в базу данных текущей транзакции. Roilback прерывает выполнение транзакции и осуществляет отмену изменений, проведенных в ходе выполнения транзакции.
Вопросы реализации в СУБД подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается журнал транзакций. Он предназначен для надежного хранения данных в базе данных. Это требование предполагает возможность восстановления согласованного состояния базы данных после любого рода программных или аппаратных сбоев.
Общие принципы восстановления
Результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных. Результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
Восстановление возможно при:
индивидуальный откат транзакции. Он должен быть применен в определенных ситуациях· аварийное завершение работы
· стандартная ситуация отката транзакции
· принудительный откат транзакции
· в случае взаимной блокировки при параллельном выполнении транзакции
мягкий сбойВосстановление после внезапной потери содержания оперативной памяти. В случае:
- аварийное отключение электропитания возникновения неустранимого сбоя процессора
Основа восстановления – архивная копия и журнал изменений базы данных.
В основе избыточное хранение данных.
2 вида ведения журнала:
1. для каждой транзакции поддерживается отдельный журнал изменений – локальный журнал
2. общий журнал изменений. Это приводит к дублированию информации в локальном и общем журнале. Поэтому используют только поддержку общего журнала изменений
Общая структура журнала может быть представлена в виде последовательного файла. Каждая запись помечается номером транзакции, к которой она относится и значением атрибутов, которые она меняет. Фиксируется команда начала и завершения транзакции. Журнал транзакций дублируется системными средствами СУБД.
Используют 2 варианта ведения журнала
протокол с отмеченными изменениями протокол с немедленными изменениямиПравила, которым должна удовлетворять процедура согласованного выполнения параллельных транзакций.
1. пользователь видит только согласованные данные
2. СУБД гарантировано поддерживает принцип независимого выполнения транзакций – сериализация транзакций.
Способ выполнения транзакций – сериальный, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Это осуществляется механизмом блокировок. Самый простой вариант – блокировка объекта на все время действия транзакции. После окончания транзакции объекты становятся доступны другим транзакциям.
В ряде СУБД организована блокировка на уровне страниц.
Блокировки, называемые синхронизационными захватами объектов, могут быть применимы к разным типам, в том числе и по всей базе данных.
Для повышения эффективности параллельного использования транзакций, используются комбинирования разных типов синхронизационных захватов.
Рассматриваются 2 основных типа:
Совместный режим блокировки – нежесткая или разделяемая блокировка (S, Shared). Это означает разделяемый захват объекта. Объекты не изменяются в процессе выполнения транзакций и доступны другим только для чтения. Монопольный режим – жесткая или эксклюзивная блокировка (X, Exclusive). Требуется для выполнения операций занесения, удаления, модификации и предполагает монопольный захват объекта. Объекты недоступны для других транзакций.Правила совместимости захвата одного объекта другим
Транзакция B |
| ||||
Разблокирована | Нежесткая | Жесткая | |||
Транзакция А | Разблокирована | Да | Да | Да |
|
Нежесткая | Да | Да | Нет |
| |
жесткая | Да | Нет | Нет |
| |
Предполагается, что первой блокирует объект транзакция А, потом пытается получить транзакция B. Нескольким транзакциям допускается читать один и тот же объект. Захват объекта одной транзакцией по чтению не совместим с захватом другой транзакции того же объекта по записи. Захваты одного объекта разными транзакциями по записи несовместимы. Применение разных типов блокировок приводит к проблеме тупиков. Количество взаимно заблокированных транзакций может быть большим. Эту ситуацию каждая из транзакций самостоятельно обнаружить не может. Ее должна разрешить СУБД. Основой обнаружения тупиковых ситуаций является построение графа ожидания транзакции. Разрушение тупика начинается с выбора в цикле транзакций, так называемой транзакции-жертвы, т. е. транзакции, которой разрешено пожертвовать ради обеспечения возможности выполнения другой транзакции.
Критерий выбора – стоимость транзакции. Жертвой выбирается самая дешевая. Стоимость выбирается многофакторной оценкой, в которую включаются с разными весами время выполнения, приоритет, число накопленных захватов. После выбора жертвы происходит ее откат. Освобождаются захваты, и может быть предложено выполнение других транзакций.
44. Защита БД, методы обеспечения защиты данных.
Стабильная система управления пользователями – обязательное условие безопасности данных, хранящихся в любой реляционной СУБД. В языке SQL не существует единственной стандартной команды, предназначенной для создания пользователей базы данных – каждая реализация делает это по-своему
8. Безопасность и секретность.
Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это право, от неавторизованной модификации данных или их уничтожения.
Секретность определяют как право отдельных лиц или организаций определять, когда, как и какое количество соответствующей информации может быть передано другим лицам или организациям.
Основные положения, особенно важные с точки зрения обеспечения безопасности данных в базе данных:
n данные защищаются от искажения, хищения и других форм уничтожения,
n данные должны быть восстанавливаемыми,
n обеспечивается возможность контроля данных,
n система недоступна для вмешательства в неё,
n должна быть установлена процедура идентификации пользователя базы данных,
n в системе предусматривается контроль действий пользователя по обработке данных с точки зрения санкционирования их выполнения,
n контроль за работой пользователя осуществляется так, чтобы его ошибочные действия были с большой вероятностью обнаружены.
Вопросы обеспечения секретности данных и их безопасности принципиально тесно связаны между собой.
45. Постреляционная модель данных, многомерная модель данных.
Постреляционная модель данных
Universe представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных в таблицах. Допускает многозначные поля (поля, значения которых состоят из подзначений). Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Постреляционная модель поддерживает также многоуровневые ассоциированные поля. Совокупность ассоциированных полей называют ассоциацией. При этом, первое значение одного столбца ассоциации соответствует первым значениям всех остальных столбцов ассоциации. Аналогичным образом связанны вторые значения. На длину полей и количество полей в записях не накладывается ограничение постоянства.
Достоинства: возможность представления совокупности связанных таблиц одной постреляционной таблицей.
Недостатки: сложность решения проблемы целостности и непротиворечивости данных.
Многомерная модель данных
OLAP – Online Analytical Processing
Выдают 2 направления:
– системы оперативной транзакционной обработки
– аналитической обработки или поддержки принятия решений.
Основные понятия:
Агрегируемость – просмотр информации на различных уровнях обобщения. В информационной системе степень детальности представления информации для пользователя зависит от её уровня
Историчность – представляет обеспечение высокого уровня статичности данных и их взаимосвязи, а также обязательность привязки данных ко времени. Статичность позволяет использовать специальные методы при обработке, загрузки, хранении и индексации данных.
Прогнозируемость – задание функции прогнозирования и применение её к различным временным интервалам.
Многомерность модели данных означает многомерное логическое представление структуры при описании и при операциях манипулирования с данными.
Многомерная модель обладает более высокой наглядностью и информативностью по сравнению с реляционной
46. Использование Union для объединения результатов Select.
Язык SQL предоставляет два способа объединения таблиц:
· указывая соединяемые таблицы (в том числе подзапросы) во фразе FROM оператора SELECT. Сначала выполняется соединение таблиц, а уже потом к полученному множеству применяются указанные фразой WHERE условия, определяемое фразой GROUP BY агрегирование, упорядочивание данных и т. п.;
· определяя объединение результирующих наборов, полученных при обработке оператора SELECT. В этом случае два оператора SELECT соединяются фразой UNION, INTERSECT, EXCEPT или CORRESPONDING.
UNION-объединение
Фраза UNION объединяет результаты двух запросов по следующим правилам:
· каждый из объединяемых запросов должен содержать одинаковое число столбцов;
· тип значений из попарно объединяемых столбцов должен быть одинаковым или приводимым. Так, нельзя объединять значения из столбца типа integer и столбца типа varchar;
· из результирующего набора автоматически исключаются совпадающие строки
· если в строку вставляется какая-либо константа, добавляемая в запросе, то ее значение также влияет на идентичность строк
Стандарт не накладывает никаких ограничений на упорядочивание строк в результирующем наборе
Для того чтобы явно указать требуемый порядок сортировки, следует использовать фразу ORDER BY. При этом можно использовать как имя столбца, так и его номер
Фраза UNION ALL выполняет объединение двух подзапросов аналогично фразе UNION со следующими исключениями:
· совпадающие строки не удаляются из формируемого результирующего набора;
· объединяемые запросы выводятся в результирующем наборе последовательно без упорядочивания.
При объединении более двух запросов для изменения порядка выполнения операции объединения можно использовать скобки
Обобщённый алгоритм декомпозиции:
1. Построение универсального отношения для БД.
2. Определение всех ФЗ, существующих между атрибутами универсального отношения.
3. Удаление всех избыточных ФЗ из исходного набора ФЗ с целью получения минимального покрытия. Эта процедура проводится путём поочерёдного удаления избыточных ФЗ с последующей проверкой получаемого на каждом шаге набора ФЗ на наличие хотя бы одной избыточной ФЗ.
4. Использование ФЗ из минимального покрытия для декомпозиции универсального отношения в набор НФБК - отношений.
5. Если может быть получено более чем одно минимальное покрытие, осуществляется сравнение результатов, полученных на основе различных минимальных покрытий, с целью определения варианта, лучше других отвечающего требованиям заказчика.
При исполнении алгебраической декомпозиции необходимо помнить о нежелательности проекции, порождаемой ФЗ, у которой зависимостная часть является детерминантом другой ФЗ или когда зависимостная часть ФЗ зависит более чем от одного детерминанта. В любом из этих случаев может быть утеряна ФЗ из БД. Если достигнуть состояние, в котором проецирование, не влекущее за собой потерь ФЗ, становится невозможным, то необходимо сделать выбор:
а). выбор оставшихся ФЗ и создание одного отношения для каждых детерминанта и набора зависящих от него атрибутов;
б). изменение порядка ранее проведенных декомпозиций, т. к. алгоритм проектирования не ведёт к единственному решению.
47. Хэширование. Методы устранения коллизий
Хеширование.
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского "to hash" - резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи, организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
Традиционно принято различать методы прямой адресации (ключ, появление которого вызвало коллизию, помещается в один из свободных элементов хэш-таблицы) и методы цепочек (записи, для ключей которых выработано одинаковое значение хэш-функции связываются в линейный список).
Способы разрешения коллизий
1. Использование сгенерированного адреса в качестве начальной точки для последовательного просмотра, с этого адреса начинается поиск свободного места в памяти.
2. Сгенерированный адрес считается адресом не конкретной записи, а областью памяти, в пределах которого размещаются эти записи, получившие этот адрес. В пределах области записи могут располагаться последовательно в порядке поступления, если со временем страница или область памяти выдается новая область памяти, связанная с предыдущей указателем.
Используются индексные файлы – файлы, состоящие из 2 частей. Индексная область образует индексный (отдельный) файл, а основная область образует файл, для которого создается индекс. В зависимости от организации индекса и основной области различают файлы с плотным и неплотным индексом.
48. Три уровня представления данных в АИС.
Существует 3 уровня: логический уровень, уровень хранения и физический уровень.
На логическом уровне работают с логическими структурами данных, отражающими реальные отношения, которые существуют между объектами и их характеристиками, т. е. указывающими в каком виде данные представляются пользователю системы. Единицей информации на этом уровне является логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определёнными признаками, являющимися атрибутами записи. На логическом уровне устанавливается перечень признаков, полностью характеризующий описываемый класс объектов. Совокупность и их взаимосвязь определяют внутреннюю структуру логической записи.
На логическом уровне представления данных не учитывается техническое и математическое обеспечение данных.
На уровне хранения оперируют со структурами хранения - представления логической структуры данных в памяти ЭВМ. Структура хранения должна полностью отображать логическую структуру данных и поддерживать её в процессе функционирования АИС. Единицей информации на этом уровне также является логическая запись.
Поддержание структуры хранения осуществляется программными средствами.
На физическом уровне представление данных оперируют с физическими структурами данных. На этом уровне решаются задачи реализации структуры хранения непосредственно в конкретной памяти конкретной ЭВМ. Единицей информации на этом уровне является физическая запись, представляющая участок носителя на котором размещаются одна или несколько логических записей.
При разработке структур данных всех уровней должен обеспечиваться принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в техническом обеспечении системы не должны отражаться на логических структурах и прикладных программах, т. е. не должны вызывать в них изменений.
Логическая независимость данных означает, что изменения в структурах хранения не должны вызывать изменений в логических структурах данных и в прикладных программах.
Физическая независимость данных означает, что изменения в физическом расположении данных и техническом обеспечении системы не должны отражаться на логических структурах и прикладных программах, т. е. не должны вызвать их изменения.
Логическая независимость данных означает, что изменения в структурах хранения не должны вызывать изменения в логических структурах данных и прикладных программ.
1. Основные требования к организации БД (1)
2. (назначения) Основные компоненты БД (2)
3. Этапы проектирования БД (3)
4. Модели данных. Классификация (4)
5. Модель "сущность-связь". Основные понятия, область применения (5)
6. Иерархическая модель данных. Основные понятия, область применения, достоинства, недостатки (6)
7. Сетевая модель данных. Основные понятия, область применения, достоинства, недостатки (7)
8. Реляционная модель данных. Основные понятия, область применения, достоинства, недостатки (8)
9. Операции реляционной алгебры (9)
10. Реляционное исчисление с переменными кортежами (10)
11. Реляционное исчисление с переменными на доменах (11)
12. Функциональные зависимости. Аксиомы, правила выводов (12)
13. Избыточные функциональные зависимости. Минимальное покрытие декомпозиции (13)
14. Нормальные формы схем отношений. 1НФ, 2НФ (14)
15. Нормальные формы схем отношений. 3НФ (15)
16. Нормальная форма Бойса-Кодда (НФБК) (16)
17. Многозначная зависимость. Аксиомы (17)
18. Нормальные формы схем отношений. 4НФ (18)
19. Нормальные формы схем отношений. 5НФ (19)
20(21). Соединение без потерь, сохраняющих зависимость (20)
21(20). Условие отсутствия потерь при соединении (21)
22. Метод Табло (22)
23. Создание и модификация БД в FoxPro (23)
24. Создание индексов. Индексирование (24)
25. Поиск и сортировка. Ускоренный поиск. (фильтрация) (25)
26. Структурированный язык запросов SQL. Основные категории (26)
27. Структурированный язык запросов SQL. Описание данных, таблицы, типы данных, целостность данных. (27,28)
28. Структурированный язык запросов SQL. Операторы манипулирования данными, курсор (29)
29. Структурированный язык запросов SQL. Типы связывания (30)
30. Структурированный язык запросов SQL. Многотабличные запросы (31)
31. Структурированный язык запросов SQL. Операции изменения и обновления БД (32)
32. Структурированный язык запросов SQL. Индексы (33)
33. Структурированный язык запросов SQL. Определение пользовательских представлений (34)
34. Файловые структуры, используемые для хранения информации БД (35)
35. Файлы прямого и последовательного доступа (36)
36. Плотный и неплотный индексы. (Б-деревья) (37)
37. Инвертированные списки (38)
38. Модель "клиент-сервер" в технологии БД (39)
39. Модель файлового сервера (40)
40. Модель удаленного доступа к данным (41)
41. Модель сервера БД (42)
42. Модель сервера приложений (43)
43. Транзакция. Свойства, способы завершения транзакции (44,45)
44. Защита БД. Методы обеспечения защиты данных (46)
45. Постреляционная модель данных, многомерная модель данных (47)
Дополнительно:
46. Использование UNION для объединения результатов SELECT. Обобщенный алгоритм декомпозиции (48)
47. Хэширование. Методы устранения коллизий (49)
48. Три уровня представления данных в АИС (автоматизированных информационных системах). Логическая и физическая независимость данных (50)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
