
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ОБ ОДНОМ ПОДХОДЕ К РЕШЕНИЮ ЗАДАЧИ ИДЕНТИФИКАЦИИ КЛАВИАТУРНОГО ПОЧЕРКА.
Учреждение Российской академии наук Научно – исследовательский институт прикладной математики и автоматизации КБНЦ РАН, г. Нальчик
Объектом исследования в данной работе является задача идентификации клавиатурного почерка с использованием чисто программных средств. Реализация этой задачи означает создание такого программного обеспечения для конкретного компьютера, которое позволит ему отличать друг от друга различных пользователей. В известном смысле мы хотим наделить компьютер всеми качествами искусного графолога. Фундаментальные работы по графологии на основе ряда формальных признаков (сила нажима, наклон и степень связанности букв, направление строки и т. д.) убедительно демонстрируют методы определения пола, возраста, образования, рода занятий писавшего.
Многие особенности рукописного почерка при работе на компьютере сопоставлять бесполезно, ведь клавиатура и драйверы стандартизируют написание букв. Но именно этот недостаток как раз и является тем преимуществом при идентификации клавиатурного почерка, так как в этом случае возможен анализ новых совершенно формализованных признаков: зависимость скорости ввода слов от их смысла, относительное время нажатия клавиш различных полей клавиатуры и т. д.
Как и у музыкантов исполнителей, у пользователей компьютером проявляется индивидуальность, заключающаяся, например, в скорости нажатия клавиш, в «удобной» последовательности нажимаемых клавиш, в привычке использовать основную и дополнительную часть клавиатуры, в характере «сдвоенных» нажатий клавиш и т. д. Разумеется, что по нескольким нажатиям клавиш отличить пользователя невозможно, следовательно, нужно какая – то статистика.
Существуют различные методы, выявляющие уникальные особенности клавиатурного почерка, которые существенно зависят от тематики защищаемого программного обеспечения. Ниже рассмотрим модельный вариант реализации задачи идентификации клавиатурного почерка, учитывающий только время между нажатиями клавиш с номером i и клавиши с номером j , когда i, j = 1,2,…,n, где n – количество символов, имеющихся на клавиатуре данного компьютера.
Обозначим через А кубическую матрицу порядка n x n x m, где m – количество последовательного нажатия клавиши с номером i, а затем клавиши с номером j, за определенный промежуток времени t = T. Следовательно, элемент матрицы а означает время прошедшее между нажатиями клавиши с номером i и номером j при k – ом случае их последовательного нажатия (k = 1,2,…, m).
Для каждого фиксированного значения i и j находим числовые характеристики выборки 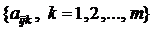 , предварительно отбросив все те значения а
, предварительно отбросив все те значения а![]() , которые достаточно сильно отличаются от большинства других (они могли появиться, например, из-за непредвиденных случаев, нарушивших установившийся темп работы пользователя). Полученные после такой процедуры квадратные матрицы порядка n x n будем называть эталонными.
, которые достаточно сильно отличаются от большинства других (они могли появиться, например, из-за непредвиденных случаев, нарушивших установившийся темп работы пользователя). Полученные после такой процедуры квадратные матрицы порядка n x n будем называть эталонными.
После того как эталонные матрицы сформированы, можно приступить к режиму идентификации.
Матрица А в режиме идентификации строится аналогичным образом. Единственное отличие может быть только в том, что элемент m её порядка будет, как правило, гораздо меньше чем у эталонной.
Далее проводится сравнение эталонной матрицы и идентификационной матрицы известными методами статистического анализа. Выход из алгоритма осуществляется через некоторый порог истинности P % , т. е. оценкой вероятности того, что пользователь – тот же, если полученная вероятность больше выбранного порога истинности.
В случае, когда трехмерный порядок идентификационной матрицы сравним с трехмерным порядком эталонной матрицы наиболее эффективным является сравнение так называемых разряженных матриц, т. е. таких матриц, которые содержат только экстремальные элементы. Например, разряженная матрица дисперсий – это такая матрица, которая содержит определенный набор минимальных и максимальных дисперсий. Все остальные элементы обнуляются. Такая матрица характеризует индивидуальные особенности стиля набора клавиш. Если элемент ![]() матрицы дисперсий
матрицы дисперсий ![]() достаточно близок к нулю, то это означает, что последовательный набор клавиш с номерами
достаточно близок к нулю, то это означает, что последовательный набор клавиш с номерами ![]() и
и ![]() является «удобным» для данного пользователя.
является «удобным» для данного пользователя.
