

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сортировка выбором
Сортировка выбором (англ. selection sort) — алгоритм сортировки, относящийся к неустойчивым алгоритмам сортировки. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае Θ(n2), предполагая что сравнения делаются за постоянное время.
Шаги алгоритма:
находим минимальное значение в текущем списке производим обмен этого значения со значением на первой позиции теперь сортируем хвост списка, исключив из рассмотрения уже отсортированный первый элементfor i := 1 to n - 1 do
begin
min := i;
for j := i + 1 to n do
if a[min] > a[j] then
min := j;
t := a[i];
a[i] := a[min];
a[min] := t
end;
Сортировка пузырьком
Сортировка пузырьком (англ. bubble sort) — простой алгоритм сортировки. Для понимания и реализации этот алгоритм — простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n2).
Алгоритм
Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма.
for i := n - 1 downto 1 do
for j := 1 to i do
if a[j] > a[j+1] then
begin
t := a[j];
a[j] := a[j+1];
a[j+1] := t;
end;
Сортировка простыми вставками
Сортировка вставками (англ. insertion sort) — простой алгоритм сортировки. Хотя этот метод сортировки намного менее эффективен, чем более сложные алгоритмы (такие как быстрая сортировка), у него есть ряд преимуществ:
На каждом шаге алгоритма, мы выбираем один из элементов входных данных и вставляем его на нужную позицию в уже отсортированном списке, до тех пор пока набор входных данных не будет исчерпан. Выбор очередного элемента, выбираемого из исходного массива — произволен, может использоваться практически любой алгоритм выбора.
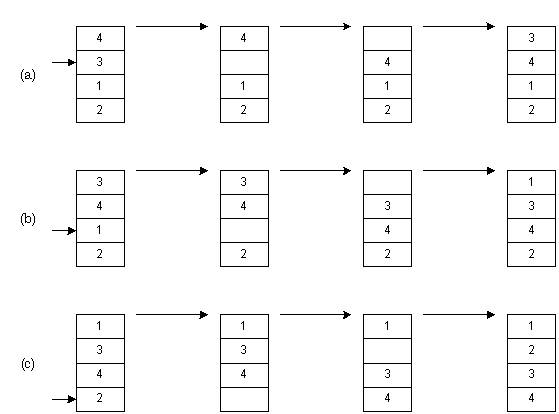
На рис (a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем вниз - до тех пор, пока не найдем место, куда нужно вставить 3. Это процесс продолжается на рис(b) для числа 1. Наконец, на рис (c) мы завершаем сортировку, поместив 2 на нужное место.
For i:=2 to Сount do
Begin
Tmp:=Arr[i];
j:=i-1;
While (Arr[j]>Tmp) and (j>0) do
Begin
Arr[j+1]:=Arr[j];
j:=j-1;
End;
Arr[j+1]:=Tmp;
End;
Сортировка Шелла (Ох и презабавная вещь).
Вариант описания №1 (длинный)
Сортировка Шелла является довольно интересной модификацией алгоритма сортировки простыми вставками.
Рассмотрим следующий алгоритм сортировки массива a[0].. a[15].
![]()
1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).

2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]).

В нулевой группе будут элементы 4, 12, 13, 18, в первой - 3, 5, 8, 9 и т. п.
3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).

4. В конце сортируем вставками все 16 элементов.
![]()
Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Так зачем нужны остальные?
Hа самом деле они продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. Последовательность и так почти отсортирована. Ускорение подтверждено многочисленными исследованиями и на практике оказывается довольно существенным.
Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
Вариант описания №2 (короткий)
Шаг 1. Упорядочиваемое множество разбивается на несколько непересекающихся подмножеств по следующему правилу:
берутся элементы неупорядоченного множества, расположенные на одинаковом расстоянии (дистанции) друг от друга. Полученные множества сортируются методом простых вставок, что позволяет уменьшить общую неупорядоченность множества.
Шаг 2. Алгоритм завершает работу, когда дистанция равна 1, иначе уменьшается дистанция между элементами и повторяется шаг 1.
Примечание:
Выбор последовательности дистанций между элементами в сортировке методом Шелла является отдельной проблемой, которая подробно рассматривается Д. Кнутом в монографии “Искусство программирования для ЭВМ. Т.3: Сортировка и поиск”.
Пример:
const N=10; {Количество элементов массива}
var a: array[1..N] of integer; {массив}
p: boolean; {флаг наличия перестановки}
l, d,i, j: integer; {служебные переменные}
...........
d:=N div 2; {Расстояние между обрабатываемыми элементами массива,
на каждом этапе алгоритма уменьшается в 2 раза вплоть до 0,
когда происходит останов алгоритма}
while d>0 do
begin
for j:=1 to N-d do {Перебор всех пар элементов массива,
расстояние между которыми равно d}
begin
l:=j {запоминаем индекс текущего элемента}
repeat
p:=false; {пока элементы не переставлялись}
if a[l]<a[l+d] then begin {если порядок нарушен, то}
c:=a[l];a[l]:=a[l+d];a[l+d]:=c; {меняем местами элементы массива}
l:=l-d; {перейдём к той паре, в которую
входит меньший из переставленных элементов}
p:=true; {запомним, что была перестановка}
end;
until (l<=1) and p; {продолжаем, пока идут перестановки и
не произошёл выход за пределы массива}
end;
d:=d div 2; {Уменьшим расстояние между сравниваемыми элементами
в 2 раза}
end;
Пирамидальная сортировка (Эх, мать…)
Вариант №1 (Вики):
Пирамидальная сортировка — алгоритм сортировки, работающий в худшем, в среднем и в лучшем случае (т. е. гарантированно) за О(n log n) операций при сортировке n элементов.
Может рассматриватъся как усовершенствованная пузырьковая сортировка, в которой элемент всплывает (min-heap) / тонет (max-heap) по многим путям.
Алгоритм:
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево – это такое двоичное дерево, у которого выполнены условия:
1. Каждый лист имеет глубину либо d либо d-1
2. Значение в любой вершине больше, чем значения ее потомков.
Пример сортирующего дерева

Удобная структура данных для сортирующего дерева – такой массив Array, что Array[1] – элемент в корне, а потомки элемента Array[i] - Array[2i] и Array[2i+1].
![]()
Алгоритм сортировки будет состоять из двух основных шагов:
1. Выстраиваем элементы массива в виде сортирующего дерева:
![]()
![]()
 при
при
Этот шаг требует О(n) операций.
2. Будем удалять элементы из корня по одному за раз и перестраивать дерево. Т. е. на первом шаге обмениваем Array[1] и Array[n], преобразовываем Array[1], Array[2], ... , Array[n-1] в сортирующее дерево. Затем переставляем Array[1] и Array[n-1], преобразовываем Array[1], Array[2], ... , Array[n-2] в сортирующее дерево. Процесс продолжается до тех пор, пока в сортирующем дереве не останется один элемент. Тогда Array[1], Array[2], ... , Array[n] - упорядоченная последовательность.
Этот шаг требует О(n log n) операций.
Вариант №2 (Алголист)
Итак, мы постепенно переходим от более-менее простых к сложным, но эффективным методам. Пирамидальная сортировка является первым из рассматриваемых методов, быстродействие которых оценивается как O(n log n).
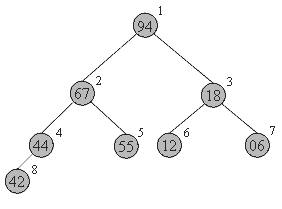
В качестве некоторой прелюдии к основному методу, рассмотрим перевернутую сортировку выбором. Во время прохода, вместо вставки наименьшего элемента в левый конец массива, будем выбирать наибольший элемент, а готовую последовательность строить в правом конце.
Пример действий для массива a[0]... a[7]:
4406 67 исходный массив
4406 |94 94 <-> 67
44|67<-> 06
44|55<-> 18
06|44<-> 06
06|42<-> 42
06 12 |1818 <-> 12
06 |1294 12 <-> 12
Вертикальной чертой отмечена левая граница уже отсортированной(правой) части массива.
Рассмотрим оценку количества операций подробнее.
Всего выполняется n шагов, каждый из которых состоит в выборе наибольшего элемента из последовательности a[0]..a[i] и последующем обмене. Выбор происходит последовательным перебором элементов последовательности, поэтому необходимое на него время: O(n). Итак, n шагов по O(n) каждый - это O(n2).
Произведем усовершенствование: построим структуру данных, позволяющую выбирать максимальный элемент последовательности не за O(n), а за O(logn) времени. Тогда общее быстродействие сортировки будет n*O(logn) = O(n log n).
Эта структура также должна позволять быстро вставлять новые элементы (чтобы быстро ее построить из исходного массива) и удалять максимальный элемент (он будет помещаться в уже отсортированную часть массива - его правый конец).
Итак, назовем пирамидой(Heap) бинарное дерево высоты k, в котором
- все узлы имеют глубину k или k-1 - дерево сбалансированное. при этом уровень k-1 полностью заполнен, а уровень k заполнен слева направо, т. е форма пирамиды имеет приблизительно такой вид:
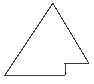
- выполняется "свойство пирамиды": каждый элемент меньше, либо равен родителю.
Как хранить пирамиду? Наименее хлопотно - поместить ее в массив.
Соответствие между геометрической структурой пирамиды как дерева и массивом устанавливается по следующей схеме:
- в a[0] хранится корень дерева левый и правый сыновья элемента a[i] хранятся, соответственнно, в a[2i+1] и a[2i+2]
Таким образом, для массива, хранящего в себе пирамиду, выполняется следующее характеристическое свойство: a[i] >= a[2i+1] и a[i] >= a[2i+2].
Плюсы такого хранения пирамиды очевидны:
никаких дополнительных переменных, нужно лишь понимать схему.
узлы хранятся от вершины и далее вниз, уровень за уровнем.
узлы одного уровня хранятся в массиве слева направо.
Запишем в виде массива пирамиду, изображенную выше.. Слева-направо, сверху-вниз:12На рисунке место элемента пирамиды в массиве обозначено цифрой справа-вверху от него.
Восстановить пирамиду из массива как геометрический объект легко - достаточно вспомнить схему хранения и нарисовать, начиная от корня.
Фаза 1 сортировки: построение пирамиды
Hачать построение пирамиды можно с a[k]...a[n], k = [size/2]. Эта часть массива удовлетворяет свойству пирамиды, так как не существует индексов i, j: i = 2i+1 ( или j = 2i+2 )... Просто потому, что такие i, j находятся за границей массива.
Следует заметить, что неправильно говорить о том, что a[k]..a[n] является пирамидой как самостоятельный массив. Это, вообще говоря, не верно: его элементы могут быть любыми. Свойство пирамиды сохраняется лишь в рамках исходного, основного массива a[0]...a[n].
Далее будем расширять часть массива, обладающую столь полезным свойством, добавляя по одному элементу за шаг. Следующий элемент на каждом шаге добавления - тот, который стоит перед уже готовой частью.
Чтобы при добавлении элемента сохранялась пирамидальность, будем использовать следующую процедуру расширения пирамиды a[i+1]..a[n] на элемент a[i] влево:
Смотрим на сыновей слева и справа - в массиве это a[2i+1] и a[2i+2] и выбираем наибольшего из них.
Если этот элемент больше a[i] - меняем его с a[i] местами и идем к шагу 2, имея в виду новое положение a[i] в массиве. Иначе конец процедуры.
Новый элемент "просеивается" сквозь пирамиду.
Ниже дана иллюстрация процесса для пирамиды из 8-и элементов:
44//Справа - часть массива, удовлетворяющая
44//свойству пирамиды,
44 55 //42
44 //06 42 остальные элементы добавляются
//12один за другим, справа налево.
В геометрической интерпретации ключи из начального отрезка a[size/2]...a[n] является листьями в бинарном дереве, как изображено ниже. Один за другим остальные элементы продвигаются на свои места, и так - пока не будет построена вся пирамида.
На рисунках ниже изображен процесс построения. Неготовая часть пирамиды (начало массива) окрашена в белый цвет, удовлетворяющий свойству пирамиды конец массива - в темный.
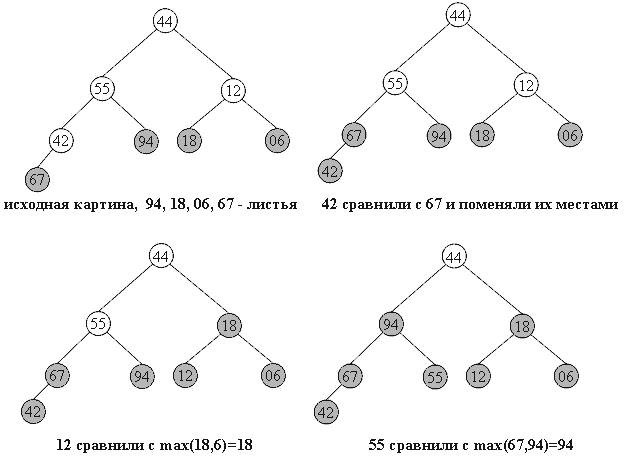
Фаза 2: собственно сортировка
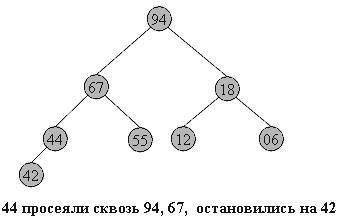
Итак, задача построения пирамиды из массива успешно решена. Как видно из свойств пирамиды, в корне всегда находится максимальный элемент. Отсюда вытекает алгоритм фазы 2:
· Берем верхний элемент пирамиды a[0]...a[n] (первый в массиве) и меняем с последним местами. Теперь "забываем" об этом элементе и далее рассматриваем массив a[0]...a[n-1]. Для превращения его в пирамиду достаточно просеять лишь новый первый элемент.
· Повторяем шаг 1, пока обрабатываемая часть массива не уменьшится до одного элемента.
Очевидно, в конец массива каждый раз попадает максимальный элемент из текущей пирамиды, поэтому в правой части постепенно возникает упорядоченная последовательность.
9406 42 // иллюстрация 2-й фазы сортировки
6712 // 94 во внутреннем представлении пирамиды
55// 67 94
44//
42//
18//
12 06 //94
06 //67 94
Каково быстродействие получившегося алгоритма?
Построение пирамиды занимает O(n log n) операций, причем более точная оценка дает даже O(n) за счет того, что реальное время выполнения downheap зависит от высоты уже созданной части пирамиды.
Вторая фаза занимает O(n log n) времени: O(n) раз берется максимум и происходит просеивание бывшего последнего элемента. Плюсом является стабильность метода: среднее число пересылок (n log n)/2, и отклонения от этого значения сравнительно малы.
Пирамидальная сортировка не использует дополнительной памяти.
Метод не является устойчивым: по ходу работы массив так "перетряхивается", что исходный порядок элементов может измениться случайным образом.
Поведение неестественно: частичная упорядоченность массива никак не учитывается.
Пример:
Type
arrType = Array[1 .. n] Of Integer;
{ первый вариант : }
Procedure HoarFirst(Var ar: arrType; n: integer);
Procedure sort(m, l: Integer);
Var i, j, x, w: Integer;
Begin
i := m; j := l;
x := ar[(m+l) div 2];
Repeat
While ar[i] < x Do Inc(i);
While ar[j] > x Do Dec(j);
If i <= j Then Begin
w := ar[i]; ar[i] := ar[j]; ar[j] := w;
Inc(i); Dec(j)
End
Until i > j;
If m < j Then Sort(m, j);
If i < l Then Sort(i, l)
End;
Begin
sort(1, n)
End;
Type
arrType = Array[1 .. n] Of Integer;
{ второй вариант : }
Procedure HoarSecond(Var ar: arrType; n: Integer);
Procedure Sort(m, l: Integer);
Var i, j, x, w: Integer;
Begin
If m >= l Then Exit;
i := m; j := l;
x := ar[(m+l) div 2];
While i < j Do
If ar[i] < x Then Inc(i)
Else If ar[j] > x Then Dec(j)
Else Begin
w := ar[i]; ar[i] := ar[j]; ar[j] := w;
End;
Sort(m, Pred(j));
Sort(Succ(i),l);
End;
Begin
Sort(1, n)
End
Сортировка быстрая («Чем дальше в лес, тем злее дятлы…»)
Вариант №1 (Вики):
Алгоритм
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
- Выбираем в массиве некоторый элемент, который будем называть опорным элементом. Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него. Рекурсивно упорядочиваем подсписки, лежащие слева и справа от опорного элемента.
Базой рекурсии являются списки, состоящие из одного или двух элементов, которые уже упорядочены. Алгоритм всегда завершается, поскольку за каждую итерацию он ставит по крайней мере один элемент на его окончательное место.
Улучшения
При выборе опорного элемента из данного диапазона случайным образом, худший случай становится очень маловероятным и ожидаемое время выполнения алгоритма сортировки - O(n log n).
Вариант №2 (Forum. ):
Быстрая сортировка Хоара
Это улучшенный метод, основанный на обмене. При "пузырьковой" сортировке производятся обмены элементов в соседних позициях. При пирамидальной сортировке такой обмен совершается между элементами в позициях, жестко связанных друг с другом бинарным деревом. Ниже будет рассмотрен алгоритм сортировки К. Хоара, использующий несколько иной механизм выбора значений для обменов. Этот алгоритм называется сортировкой с разделением или быстрой сортировкой. Она основана на том факте, что для достижения наибольшей эффективности желательно производить обмены элементов на больших расстояниях.
Предположим, что даны N элементов массива, расположенные в обратном порядке. Их можно рассортировать, выполнив всего N/2 обменов, если сначала поменять местами самый левый и самый правый элементы и так далее, постепенно продвигаясь с двух сторон к середине. Это возможно только, если мы знаем, что элементы расположены строго в обратном порядке.
Рассмотрим следующий алгоритм: выберем случайным образом какой-то элемент массива (назовем его X). Просмотрим массив, двигаясь слева направо, пока не найдем элемент a[ i ]>X (сортируем по возрастанию), а затем просмотрим массив справа налево, пока не найдем элемент a[ j ]<X. Далее, поменяем местами эти два элемента a[ i ] и a[ j ] и продолжим этот процесс "просмотра с обменом", пока два просмотра не встретятся где-то в середине массива.
После такого просмотра массив разделится на две части: левую с элементами меньшими (или равными) X, и правую с элементами большими (или равными) X. Итак, пусть a[k] (k=1,...,N) - одномерный массив, и X - какой-либо элемент из a. Надо разбить "a" на две непустые непересекающиеся части а1 и а2 так, чтобы в a1 оказались элементы, не превосходящие X, а в а2 - не меньшие X.
Рассмотрим пример. Пусть в массиве a: <6, 23, 17, 8, 14, 25, 6, 3, 30, 7> зафиксирован элемент x=14. Просматриваем массив a слева направо, пока не найдем a[ i ]>x. Получаем a[2]=23. Далее, просматриваем a справа налево, пока не найдем a[ j ]<x. Получаем a[10]=7. Меняем местами a[2] и a[10]. Продолжая этот процесс, придем к массиву <6, 7, 3, 8, 6> <25, 14, 17, 30, 23>, разделенному на две требуемые части a1, a2. Последние значения индексов таковы: i=6, j=5. Элементы a[1],....,a[i-1] меньше или равны x=14, а элементы a[j+1],...,a[n] больше или равны x. Следовательно, разделение массива произошло.
Описанный алгоритм прост и эффективен, так как сравниваемые переменные i, j и x можно хранить во время просмотра в быстрых регистрах процессора. Наша конечная цель - не только провести разделение на указанные части исходного массива элементов, но и отсортировать его. Для этого нужно применить процесс разделения к получившимся двум частям, затем к частям частей, и так далее до тех пор, пока каждая из частей не будет состоять из одного единственного элемента. Эти действия описываются следующей программой. Процедура Sort реализует разделение массива на две части, и рекурсивно обращается сама к себе...
Сложность O(n*logn), на некоторых тестах работает быстрее сортировки слияниями, но на некоторых специально подобранных - работает за O(n^2).
Примеры:
Type
arrType = Array[1 .. n] Of Integer;
{ первый вариант : }
Procedure HoarFirst(Var ar: arrType; n: integer);
Procedure sort(m, l: Integer);
Var i, j, x, w: Integer;
Begin
i := m; j := l;
x := ar[(m+l) div 2];
Repeat
While ar[i] < x Do Inc(i);
While ar[j] > x Do Dec(j);
If i <= j Then Begin
w := ar[i]; ar[i] := ar[j]; ar[j] := w;
Inc(i); Dec(j)
End
Until i > j;
If m < j Then Sort(m, j);
If i < l Then Sort(i, l)
End;
Begin
sort(1, n)
Type
arrType = Array[1 .. n] Of Integer;
{ второй вариант : }
Procedure HoarSecond(Var ar: arrType; n: Integer);
Procedure Sort(m, l: Integer);
Var i, j, x, w: Integer;
Begin
If m >= l Then Exit;
i := m; j := l;
x := ar[(m+l) div 2];
While i < j Do
If ar[i] < x Then Inc(i)
Else If ar[j] > x Then Dec(j)
Else Begin
w := ar[i]; ar[i] := ar[j]; ar[j] := w;
End;
Sort(m, Pred(j));
Sort(Succ(i),l);
End;
Begin
Sort(1, n)
End;
End;
Сортировка поразрядная
Пусть имеем максимум по k байт в каждом ключе (хотя за элемент сортировки вполне можно принять и что-либо другое, например слово - двойной байт, или буквы, если сортируются строки). k должно быть известно заранее, до сортировки.
Разрядность данных (количество возможных значений элементов) - m - также должна быть известна заранее и постоянна. Если мы сортируем слова, то элемент сортировки - буква, m = 33. Если в самом длинном слове 10 букв, k = 10. Обычно мы будем сортировать данные по ключам из k байт, m=256.
Пусть у нас есть массив source из n элементов по одному байту в каждом.
Для примера можете выписать на листочек массив source = <7, 9, 8, 5, 4, 7, 7>, и проделать с ним все операции, имея в виду m=9.
for i := 0 to Pred(255) Do distr[i]:=0;
for i := 0 to Pred(n) Do distr[source[i]] := distr[[i]] + 1;
Для нашего примера будем иметь distr = <0, 0, 0, 0, 1, 1, 0, 3, 1, 1>, то есть i-ый элемент distr[] - количество ключей со значением i.
Заполним таблицу индексов:index: array[0] of integer;
index[0]:=0;
for i := 1 to Pred(255) Do index[i]=index[i-1]+distr[i-1];
В index[ i ] мы поместили информацию о будущем количестве символов в отсортированном массиве до символа с ключом i.
Hапример, index[8] = 5 : имеем <4, 5, 7, 7, 7, 8>.
А теперь заполняем новосозданный массив sorted размера n:for i := 0 to Pred(n) Do Begin
sorted[ index[ source[i] ] ]:=source[i];
{
попутно изменяем index уже вставленных символов, чтобы
одинаковые ключи шли один за другим:
}
index[ source[i] ] := index[ source[i] ] +1;
End;
Итак, мы научились за O(n) сортировать байты. А от байтов до строк и чисел - 1 шаг. Пусть у нас в каждом числе - k байт.
Будем действовать в десятичной системе и сортировать обычные числа ( m = 10 ).
сначала они в сортируем по младшему на один беспорядке: разряду: выше: и еще раз:
Hу вот мы и отсортировали за O(k*n) шагов. Если количество возможных различных ключей ненамного превышает общее их число, то 'поразрядная сортировка' оказывается гораздо быстрее даже 'быстрой сортировки'!
Пример:
Const
n = 8;
Type
arrType = Array[0 .. Pred(n)] Of Byte;
Const
m = 256;
a: arrType =
(44, 55, 12, 42, 94, 18, 6, 67);
Procedure RadixSort(Var source, sorted: arrType);
Type
indexType = Array[0 .. Pred(m)] Of Byte;
Var
distr, index: indexType;
i: integer;
begin
fillchar(distr, sizeof(distr), 0);
for i := 0 to Pred(n) do
inc(distr[source[i]]);
index[0] := 0;
for i := 1 to Pred(m) do
index[i] := index[Pred(i)] + distr[Pred(i)];
for i := 0 to Pred(n) do
begin
sorted[ index[source[i]] ] := source[i];
index[source[i]] := index[source[i]]+1;
end;
end;
var
b: arrType;
begin
RadixSort(a, b);
end.
25 Табличный редактор Excel абсолютные и относительные адреса. Запись и выполнение операций. Графическое оформление результатов.
Основным достоинством электронной таблицы Excel является наличие мощного аппарата формул и функций. Любая обработка данных в Excel осуществляется при помощи этого аппарата. Вы можете складывать, умножать, делить числа, извлекать квадратные корни, вычислять синусы и косинусы, логарифмы и экспоненты. Помимо чисто вычислительных действий с отдельными числами, вы можете обрабатывать отдельные строки или столбцы таблицы, а также целые блоки ячеек. В частности, находить среднее арифметическое, максимальное и минимальное значение, среднеквадратичное отклонение, наиболее вероятное значение, доверительный интервал и многое другое.
После того как формула введена в ячейку, вы можете ее перенести, скопировать или распространить на блок ячеек.
При перемещении формулы в новое место таблицы ссылки в формуле не изменяются, а ячейка, где раньше была формула, становится свободной. При копировании формула перемещается в другое место таблицы, ссылки изменяются, но ячейка, где раньше находилась формула, остается без изменения. Формулу можно распространить на блок ячеек.
При копировании формул возникает необходимость управлять изменением адресов ячеек или ссылок. Для этого перед символами адреса ячейки или ссылки устанавливаются символы “$”. Изменяться только те атрибуты адреса ячейки, перед которыми не стоит символ “$”. Если перед всеми атрибутами адреса ячейки поставить символ “$”, то при копировании формулы ссылка не изменится.
Например:
Если в записи формулы ссылку на ячейку D7 записать в виде $D7, то при перемещении формулы будет изменяться только номер строки “7”. Запись D$7 означает, что при перемещении будет изменяться только символ столбца “D”. Если же записать адрес в виде $D$7, то ссылка при перемещении формулы на этот адрес не изменится, и в расчетах будут участвовать данные из ячейки D7. Если в формуле указан интервал ячеек G3:L9, то управлять можно каждым из четырех символов: “G”, “3”, “L” и “9”, помещая перед ними символ “$”.
Если в ссылке используются символы $, то она называется абсолютной, если символов $ в ссылке нет — относительной. Адреса таких ссылок называются абсолютными и относительными, соответственно.
Абсолютные адреса при перемещении формул не изменяются, а в относительных адресах происходит смещение на величину переноса.
BONUS
Список вопросов в нормальном виде:
1. Функции ОС, интерфейс пользователя.
2. Функции ОС MS DOS. Обеспечение автоматического запуска ОС,
3. Файлы AUTOEXEC.BAT и CONFIG.SYS Начальная загрузка.
4. Файловая структура. Диски, файлы, их имена
5. Каталоги. Корневой и текущий каталоги. Путь к файлу.
6. Основные команды MS DOS. Команды работы с каталогами.
7. Оболочка Norton Commander. Возможности Norton Commander
8. Дерево каталогов в Norton Commander. Просмотр и редактирование файлов. Создание и удаление файлов. Работа с группами файлами.
9. Панели и функциональные клавиши в Norton Commander. Меню Norton Commander, Memo пользователя.
10. Структура и общие принципы построения программы в Turbo Pascal 'e Алфавит, лексика. Операторные скобки. Алфавит Константы. Переменные.
11. Типы данных в Turbo Pascal`е. Порядковый, вещественный, структурированный Совместимость и преобразование типов.
12. Имена и доступ к файлам в Turbo Pascal`е
13.Операторы ввода' вывоза в Turbo Pascal`е
14.Операции в Turbo Pascal`е
15.Условный оператор. Оператор выбора в Turbo Pascal'e.
16.Метки и оператор перехода.
17.Операторы циклов с предусловием, постусловием и с параметром в Turbo Pascal`е
18.Процедуры и функции в Turbo Pascal`е. Локализация имен.
19.Локальные и глобальные переменные в Turbo Pascal'e.
20.Процедуры и функции формальные и фактические параметры в Turbo Pascal`е
21.Переход в графический режим в Turbo Pascal`е. Масштабирование
22.Процедуры и функции в Turbo Pascal`е Pascal'е для работы с экраном в графическом режиме.
23.Алгоритмы поиска и выборки элементов из массивов данных.
24.Алгоритмы сортировки данных. Критерии эффективности работы алгоритма.Сортировка выбором. Сортировка пузырьком. Сортировка простыми вставками. Сортировка Шелла. Сортировка пирамидальная. Сортировка быстрая. Сортировка поразрядная.
25.Табличный редактор Excel абсолютные и относительные адреса. Запись и выполнение операций. Графическое оформление результатов.
Список Крематоров. Примечания и пожелания.
От имени редакторского совета издания «Йа консолько!»
(то есть от лица компилятора).
Я рад, что это всё закончилось и вот в день сдачи экзамена, в 5 часов 13 минут. Я готов разослать то, что получилось. Большое спасибо, всем кто принял участие в этом безобразии и столь же большой удачи на экзамене! Надеюсь, то, что мы тут все компилировали, вам поможет. Успехов друзья!
Внимание: Плохо проработан вопрос номер два.
В фильме снимались:
Brutal Scorpion (Саня): Табличка сравнения сортировок.
Bigpek(Лёха): Большой кусок ДОСа, excel и «Нортон коммандер».
Немой(Паша): Гигантский кусок вопросов.
Ph0enix(Я, т. е. Лёха): Всё остальное и компиляция.
Искренне Ваш, компилятор Ph0enix.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
