
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
К ПОСТРОЕНИЮ БЫСТРОГО АЛГОРИТМА ОБРАТНОГО ПРЕОБРАЗОВАНИЯ В БЛОЧНОЙ КРИПТОСИСТЕМЕ
,
Минск, ОИПИ НАН БЕЛАРУСИ
Современные криптосистемы характеризуются применением многоэлементных композиций разнообразных функциональных преобразований, что существенно затрудняет решение задач, стоящих перед криптоаналитиком. Тем не менее, представляет интерес исследование этих преобразований по отдельности и разработка быстрых алгоритмов их реализации.
Универсальным (хотя и тривиальным) способом представления любых преобразований, аналитических и алгоритмических, является использование табличной формы, в которой преобразование задается двумя последовательностями A и B, каждая из которых содержит m кодовых комбинаций (булевых векторов). Элементарным способом кодирования некоторого сообщения может служить последовательная замена его символов (представляемых булевыми векторами, отыскиваемыми в A) на соответствующие (с тем же номером) элементы последовательности B.
При реализации этого тривиального способа на компьютере последовательность A представляется одноименным упорядоченным массивом, и для поиска нужного элемента в нем можно применить известный алгоритм бинарного поиска. В литературе этот алгоритм иногда называется методом деления пополам или логарифмическим поиском.
Суть этого метода заключается в следующем. Длина массива A делится пополам и выполняется сравнение со средним элементом массива. Результат сравнения позволяет определить, в какой половине массива продолжать поиск, применяя к ней ту же процедуру, и т. д. После не более чем примерно log2 m сравнений либо будет найден искомый элемент, либо будет установлено его отсутствие.
При обратном преобразовании массивы A и B меняются своими ролями, и требуется сначала отыскать некоторый символ в массиве B, что затруднительно, поскольку этот массив не упорядочен. Так возникает задача упорядочения данного массива, с сохранением исходного взаимно однозначного отношения между массивами A и B. В результате данная пара A и B заменяется на пару A* и B*, в которой массив B* упорядочен, а A* - не упорядочен. Конкретизируем поставленную задачу, учитывая, что ее практическое решение будет связано с некоторыми ограничениями.
Положим, что требуется упорядочить некоторый большой массив V, состоящий из n‑компонентных булевых векторов (n ≤ 32), причем общее число таких векторов m ≤ 1 000 000.
Для решения этой задачи нами был применен алгоритм поразрядной сортировки. Его суть заключается в следующем.
Сначала в массиве V анализируется значение первого байта каждого элемента и строится новый равномощный массив V1, условно разделенный на 256 групп. Эта операция выполняется за два просмотра всех элементов массива V.
При первом просмотре ведется подсчет элементов каждой группы (согласно значению первого байта номер группы совпадает со значением первого байта) и определяются адреса групп в новом массиве V1.
При втором просмотре элементы массива V переписываются в соответствующую группу массива V1. В результате полученный массив V1 оказывается упорядочен по значению первого байта.
Аналогично выполняется сортировка по второму и третьему байтам внутри каждой группы. Схема поразрядной сортировки приведена на рис. 1.
Упорядочение по последнему четвертому байту в одной группе реализуется следующим образом. Строится новый массив V4, состоящий из 256 элементов, и в него переписываются элементы текущей группы согласно значению четвертого байта – индекс массива V4 совпадает со значением четвертого байта. В результате построенный массив V4 будет полностью упорядочен. В общем случае в массиве V4 могут быть свободные (незаполненные) элементы, поэтому при втором просмотре элементы массива уплотняются и переписываются в результирующий массив.
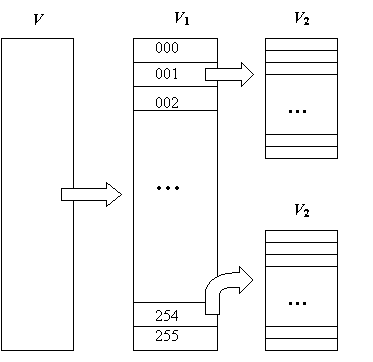 |
Рис. 1. Схема поразрядной сортировки
Описанные алгоритмы поразрядной сортировки и бинарного поиска были реализованы в среде Visual C++. Проведены их экспериментальные испытания на компьютере Pentium IV для различных значений n и m. Следующие результаты испытаний показали высокую эффективность данных алгоритмов: при n = 32 и m = 1 000 000 сортировка выполняется приблизительно за 17 с. При этих же параметрах поиск нужного элемента выполняется быстрее чем за 0,01 с.
