

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ДЕПАРТАМЕНТ ОБРАЗОВАНИЯ ГОРОДА МОСКВЫ
МОСКОВСКИЙ ГОРОДСКОЙ ДВОРЕЦ ДЕТСКОГО (ЮНОШЕСКОГО) ТВОРЧЕСТВА
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУТ РАДИОТЕХНИКИ,
ЭЛЕКТРОНИКИ И АВТОМАТИКИ (ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
Кафедра «ТИССУ» Факультета «Кибернетики» МИРЭА
Сектор НИТ Отдела технического творчества МГДД(Ю)Т
ЛАБОРАТОРНЫЙ ПРАКТИКУМ ПО ИНФОРМАТИКЕ ДЛЯ ГРУПП ЭЛИТНОГО ОБРАЗОВАНИЯ В ПОСТАНОВКЕ АКАДЕМИИ ДОПОЛНИТЕЛЬНОГО ОБРАЗОВАНИЯ НАЦИОНАЛЬНОЙ КОМПЬЮТНОЙ КОРПОРАЦИИ, МГДД(Ю)Т и МИРЭА
На правах рукописи
, ,

Москва 2005
УДК 9
Главный редактор: Первый заместитель директора МГДД(Ю)Т
Руководитель эксп. техн. комплекса: заведующий отделом МГДД(Ю)Т
Литературный редактор: заместитель заведующего отделом МГДД(Ю)Т
Выпускающий редактор:
Руководитель инф.-технол. группы:
Сопровождение в портале:
Лицей № 000 «Воробьевы горы», МГДД(Ю)Т, МИРЭА, , 2005. - ## с.
Настоящее учебно-методическое издание содержит задания на лабораторные работы по дисциплине «Информатика» и практические рекомендации по их выполнению.
Материалы рекомендуются студентам специальности 230«Информационные системы и технологии» направления подготовки дипломированных специалистов 654700 «Информационные системы» в качестве методических указаний для выполнения лабораторных работ по дисциплине «Информатика».
Печатаются по решению редакционно-издательского совета Московского государственного института радиотехники, электроники и автоматики (технического университета).
По специальностям (специализациям):
- 071900 «Информационные системы в образовании»;
База данных размещена на сервере Технологической экспериментальной площадки ГНИИ ИТТ “Информика” - МГДД(Ю)Т – МИРЭА (http://www. *****/). Соответствующий автоматизированный глоссарий встроен в ядро информационной системы дополнительного образования московского региона под управлением Lotus Notes.
ББК
Лицензия на издательскую деятельность: ЛР № 000 от 01.01.01 года
Адрес в МГДД(Ю)Т: email – *****@***ru, Москва, ул. Косыгина, комн. 4-21, 4-31.
Адрес в МИРЭА: email – *****@***ru, Москва, пр-т Вернадского, д. 78.
МГДД(Ю)Т Заказ ___________ Тираж 40 экз.
Лабораторная работа №1 Использование оптимизирующего компилятора
Цель:
1. Научиться измерять интервалы времени в программах на языке Си,
2. Исследовать зависимость времени исполнения программы от использования ключей оптимизации компилятора.
Задание:
1. Написать программу на языке Си для решения поставленной задачи. Вычислительную часть оформить отдельной функцией. До и после вызова вычислительной функции вставить соответствующие вызовы функций замера времени.
2. Компилируя программу компилятором gcc без оптимизации, подобрать такое значение параметра задачи N, чтобы вычисление занимало время порядка нескольких десятков секунд.
3. Скомпилировать тестовую программу доступными компиляторами с различными ключами оптимизации и замерить время вычисления при найденном значении параметра. Использовать различные уровни оптимизации, оптимизацию под архитектуру используемого процессора. Результаты представить в таблице:
Процессор | Компилятор | Ключи оптимизации | Время вычисления |
Варианты заданий
1. Вычисление числа Пи по формуле:
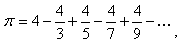
Параметр: N – число итераций.
2. Вычисление определенного интеграла методом трапеций:
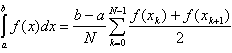 , f(x)=exsin(x), a = 0, b = π.
, f(x)=exsin(x), a = 0, b = π.
Параметр: N – число интервалов.
3. Вычисление квадратного корня с помощью алгоритма Ньютона:
Сходящаяся серия итераций: ai+1 = (ai + x / ai ) / 2.
Начальное значение a0 можно взять произвольным.
Параметр: N – число итераций
4. Сортировка методом пузырька.
Дан массив случайных чисел длины N. На первой итерации попарно упорядочиваются все соседние элементы; на второй – все, кроме последнего; на третьей – кроме последнего и предпоследнего и т. п.
Параметр: N – размер массива.
5. Вычисление числа Пи методом Монте-Карло:
Генерируется N точек (x;y), равномерно распределенных на квадрате [0;1]x[0;1]. Вычисляется M – число точек, попавших в четверть круга с радиусом 1 (x2+y2≤1).
Число Пи можно приближенно вычислить по формуле: ![]() .
.
Параметр: N – число точек.
В отчет:
· Фамилия, группа,
· Вариант (что вычислялось),
· Какой способ измерения времени использовался,
· Программа,
· Результаты для следующих компиляторов и ключей оптимизации (на ccfit):
o gcc-3.0 –O0
o gcc-3.0 –O1
o gcc-3.0 –O2
o gcc-3.0 –O3
o icc –O0
o icc –O1
o icc –O2
o icc –O3
o icc –O3 –march=pentiumiii
Лабораторная работа №2 Изучение ассемблерного листинга программы
(архитектура x86)
Цель:
1. Познакомиться с программной архитектурой x86,
2. Научиться читать ассемблерный листинг программы для x86 и проводить его простейший анализ.
Язык ассемблера привязан к архитектуре процессора. Команды ассемблера напрямую отображаются в команды процессора. Поэтому, рассматривая ассемблерный код программы, можно с большой долей уверенности судить о том, как программа будет реально исполняться.
Некоторые операции, такие как ветвления и обращения к памяти, сильно замедляют процесс исполнения. Оптимизирующий компилятор старается сформировать максимально эффективный код, т. е. который исполняется наиболее быстро. Вот некоторые действия, которые компилятор выполняет с целью улучшения кода:
· Избежание частых обращений в медленную оперативную память. Компилятор старается расположить как можно больше данных в регистрах.
· Переупорядочение инструкций процессора
o с целью устранения задержек при обращении к памяти,
o чтобы максимально загрузить исполнительные устройства процессора,
o при оптимизации ветвлений.
· Устранение зависимостей по данным, чтобы иметь больше свободы при переупорядочивании инструкций.
· Исключение недосягаемого кода.
· Устранение лишних и избыточных вычислений и вызовов функций.
· Удаление неиспользуемых переменных.
· Вычисление выражений на этапе компиляции, выполнение алгебраических упрощений.
· Устранение ветвлений путем дублирования кода, использования условного присваивания.
· Оптимизация ветвлений
o удаление лишних и заведомо ложных условий,
o оптимизация константных условий,
o замена переходов арифметическими операциями.
· Замена дорогостоящих операций на более эффективные (например, деление à умножение à сложение à побитовый сдвиг).
· Оптимизация циклов:
o Раскрутка цикла – многократное дублирование тела цикла с уменьшением числа итераций с целью увеличения расстояния между ветвлениями,
o Вынос инвариантного кода за пределы цикла,
o Удаление ветвлений из циклов,
o Замена циклов с предусловием на циклы с постусловием,
o Замена возрастающих циклов на убывающие.
· Переупорядочивание функций.
· Встраивание функций с целью устранения ветвлений при вызове функции, для возможности переупорядочить инструкции на границе тела функции и вызывающего кода.
· Оптимизация для конкретной архитектуры, использование специальных расширений (MMX, SSE, SSE2, 3DNow!, …).
Задание
Для тестовой программы (из первой лабораторной работы) сгенерировать ассемблерные листинги при компиляции с различными уровнями оптимизации. В программе использовать тип данных float. В каждом ассемблерном листинге:
1. Распознать вычислительную функцию, сопоставить команды языка Си с командами ассемблера.
2. Локализовать обращения в память, которые происходят при выполнении вычислительной функции. Определить позиции в исходной программе на Си, в которых происходят обращения в память. Посчитать общее число обращений в память при выполнении вычислительной функции (в зависимости от параметра задачи).
3. Определить, какие переменные и параметры вычислительной функции отображены на регистры, и какие размещены в памяти. Какие регистры используются для реализации вычислений (регистры общего назначения, регистры x87, MMX, XMM).
4. Описать видимые изменения в ассемблерном коде программы при переходе от одного уровня оптимизации к другому. Описать какие оптимизационные преобразования выполнил компилятор.
Для выполнения задания использовать компилятор Intel (icc) со следующими ключами оптимизации:
Ключи icc | Краткое описание ключей оптимизаций |
-O0 | Без оптимизации |
-O1 | Оптимизация по скорости исполнения. Используется локальная оптимизация: распределение регистров, небольшие перестановки кода. Используется также оптимизации, которые могут приводить к увеличению размера кода (например, раскрутка циклов, дублирование вычислений для избежания ветвлений). |
-O2 | Для icc то же, что и –O1. |
-O3 | Более агрессивная оптимизация. Преобразования циклов, оптимизация доступа к памяти, встраивание функций. В некоторых случаях может не привести к улучшению производительности. |
-O3 –march=pentiumiii | Оптимизация под Pentium III. Более агрессивный анализ кода с учетом особенностей целевого процессора, использование SSE инструкций. |
В отчет включить:
· Фамилия, группа,
· Текст вычислительной функции (на Си) и небольшое описание (что вычисляется),
· Для каждого ключа оптимизации указать:
· число обращений в память внутри вычислительной функции (функция от N),
· какие переменные размещены на регистрах, на регистрах какого типа (регистры общего назначения, регистры x87, регистры MMX, регистры XMM), если можно сделать такое соответствие.
· какие видимые изменения в коде программы произошли при переходе от предыдущего уровня оптимизации (текст в произвольной форме). Например:
- были убраны ненужные инструкции,
- переменные стали располагаться на регистрах,
- стали использоваться другие инструкции,
- инструкции стали располагаться в другом порядке,
- цикл развернулся сколько-то раз,
- функция не вызывается с помощью call, а подставляется ее код,
- и т. п.
Где возможно, приводить конкретные примеры ассемблерных команд из листинга.
Лабораторная работа №3 Использование SIMD-расширений архитектуры x86
Цель: научиться использовать в программах на языке Си SIMD-расширения архитектуры x86.
SIMD-расширения архитектуры x86
SIMD-расширения (Single Instruction Multiple Data) были введены в архитектуру x86 с целью повышения скорости обработки потоковых данных. Основная идея заключается в одновременной обработке нескольких элементов данных за одну инструкцию.
Расширение MMX
Первой SIMD-расширение в свой x86-процессор ввела фирма Intel – это расширение MMX. Оно стало использоваться в процессорах Pentium MMX (расширение архитектуры Pentium или P5) и Pentium II (расширение архитектуры Pentium Pro или P6). Расширение MMX работает с 64-битными регистрами MM0-MM7, физически расположенными на регистрах сопроцессора, и включает 57 новых инструкций для работы с ними. 64-битные регистры логически могут представляться как одно 64-битное, два 32-битных, четыре 16-битных или восемь 8-битных упакованных целых.
Еще одна особенность технологии MMX – это арифметика с насыщением. При этом переполнение не является циклическим, как обычно, а фиксируется минимальное или максимальное значение. Например, для 8-битного беззнакового целого x:
обычная арифметика: x=254; x+=3; // результат x=1
арифметика с насыщением: x=254; x+=3; // результат x=255
Расширение 3DNow!
Технология 3DNow! была введена фирмой AMD в процессорах K6-2. Это была первая технология, выполняющая потоковую обработку вещественных данных. Расширение работает с регистрами 64-битными MMX, которые представляются как два 32-битных вещественных числа с одинарной точностью. Система команд расширена 21 новой инструкцией, среди которых есть команда выборки данных в кэш L1. В процессорах Athlon и Duron набор инструкций 3DNow! был несколько дополнен новыми инструкциями для работы с вещественными числами, а также инструкциями MMX и управления кэшированием.
Расширение SSE
С процессором Intel Pentium III впервые появилось расширение SSE (Streaming SIMD Extension). Это расширение работает с независимым блоком из восьми 128-битных регистров XMM0-XMM7. Каждый регистр XMM представляет собой четыре упакованных 32-битных вещественных числа с одинарной точностью. Команды блока XMM позволяют выполнять как векторные (над всеми четырьмя значениями регистра), так и скалярные операции (только над одним самым младшим значением). Кроме инструкций с блоком XMM в расширение SSE входят и дополнительные целочисленные инструкции с регистрами MMX, а также инструкции управления кэшированием.
Расширение SSE2
В процессоре Intel Pentium 4 набор инструкций получил очередное расширение – SSE2. Оно позволяет работать с 128-битными регистрами XMM как с парой упакованных 64-битных вещественных чисел двойной точности, а также с упакованными целыми числами: 16 байт, 8 слов, 4 двойных слова или 2 учетверенных (64-битных) слова. Введены новые инструкции вещественной арифметики двойной точности, инструкции целочисленной арифметики, 128-разрядные для регистров XMM и 64-разрядные для регистров MMX. Ряд старых инструкций MMX распространили и на XMM (в 128-битном варианте). Кроме того, расширена поддержка управления кэшированием и порядком исполнения операций с памятью.
Расширение SSE3
Дальнейшее расширение системы команд – SSE3 – вводится в процессоре Intel Pentium 4 с ядром Prescott. Это набор из 13 новых инструкций, работающих с блоками XMM, FPU, в том числе двух инструкций, повышающих эффективность синхронизации потоков, в частности, при использовании технологии Hyper-Threading.
Поддержка SIMD-расширений архитектурой x86-64
Процессоры AMD Athlon64 и AMD Opteron с архитектурой x86-64 поддерживают все выше перечисленные SIMD-расширения, кроме SSE3. Кроме того, число XMM регистров у этих процессоров увеличилось до 16 (XMM0-XMM15).
Использование SIMD-расширений при написании программ
Использование векторных расширений может дать значительный прирост производительности, поэтому стремление их использовать является вполне оправданным. Существует несколько способов, позволяющих реализовать возможности имеющихся SIMD-расширений в программах языках высокого уровня:
1) Воспользоваться знаниями компилятора.
Оптимизирующий компилятор, умеющий генерировать код для данного SIMD - расширения – это наиболее простой путь к достижению высокой производительности. Основными недостатками этого подхода являются следующие:
- Существует не так много компиляторов, умеющих эффективно применять команды существующих SIMD-расширений. Расширения SSE и SSE2 хорошо применяются компилятором от Intel, тогда как расширение 3DNow! почти не один компилятор использовать не умеет.
- Компилятор может не распознать возможность эффективного применения векторных операций для увеличения производительности.
2) Использовать вставки на ассемблере.
При этом подходе мы полностью контролируем эффективность программы, исключая возможность компилятора помочь нам при создании эффективного кода. Недостатки этого подхода очевидны:
- необходимо знать основы программирования на языке ассемблера,
- ухудшается переносимость программ.
3) Использовать специальные встроенные функции (intrinsics), отображаемые в соответствующие команды SIMD-расширений. Конечно, эти команды должны поддерживаться компилятором. Преимуществами данного подхода, по сравнению с остальными, являются:
- возможность использовать SIMD-инструкции там, где это необходимо (а не надеяться на компилятор),
- возможность управлять эффективностью векторизации программы не спускаясь до уровня ассемблера,
- возможность использования знаний компилятора при генерации кода.
Библиотеки подпрограмм
Для некоторых предметных областей существуют эффективно реализованные библиотеки операций, оптимизированные под различные вычислительные системы. Наиболее ярким примером таких библиотек можно назвать BLAS и Lapack, которые содержат процедуры, реализующие многие операции линейной алгебры (работа с векторами, матрицами).
Существуют реализации этих библиотеки под многие архитектуры, что обеспечивает переносимость программ, написанных с их использованием. Каждая реализация стремится учесть все особенности целевой архитектуры для достижения высокой производительности, в частности, векторные операции, кэш-память.
Задание
Обращение матрицы A размером N*N можно выполнить с помощью разложения в ряд:
![]()
где ![]() ,
, 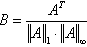 ,
,
![]() ,
, ![]() ,
,
I – единичная матрица (на диагонали – единицы, остальные – нули).
1) Написать три варианта программы вычисления обратной матрицы:
- без использования специальных расширений (обычный вариант),
- с использованием встроенных векторных функций расширения SSE.
- с использованием библиотеки BLAS.
Каждый вариант программы:
- оптимизировать по скорости, насколько это возможно,
- проверить на правильность на небольшом тесте.
Использовать тип данных float.
Размер N предполагать кратным четырем.
Программы компилировать с помощью icc с ключом –O3.
2) Сравнить: время работы четырех вариантов программы для N=512, число шагов 10:
- обычный без оптимизации под Pentium III,
- обычный с оптимизацией под Pentium III (ключ –march=pentiumiii),
- с использованием SSE без оптимизации под Pentium III,
- c использованием BLAS без оптимизации под Pentium III.
Определить:
- среднее время одной итерации цикла (умножение + сложение матриц),
- время вычислений вне цикла (общее время минус время в цикле).
Замер времени выполнить несколько раз, в качестве результата взять минимальное время. Для измерения времени использовать функцию times (измерения времени работы процесса).
Лабораторная работа №4 Исследование влияния кэш-памяти
Цель:
1. Сравнить скорости различных способов обхода данных в памяти.
2. Определить влияние кэш-памяти на скорость доступа к данным.
Кэш-память является промежуточным хранилищем данных между процессором и оперативной памятью. Она содержит копии наиболее часто используемых блоков данных. Размер кэш-памяти составляет от нескольких килобайт до нескольких мегабайт, а скорость доступа к ней в несколько раз превосходит скорость доступа к оперативной памяти, но уступает скорости обращения к регистрам.
Допустим, некоторая программа производит многократную обработку элементов массива. Если построить график зависимости времени обработки массива от размера массива, то он должен иметь нелинейный характер. При превышении размера кэш-памяти время обращения к элементам массива несколько возрастет.
Данные из оперативной памяти в кэш-память считываются целыми строками. Размер кэш-строки в большинстве распространенных процессоров составляет 16, 32, 64, 128 байт. При последовательном обходе попытка чтения первого элемента кэш-строки вызывает копирование всей строки из медленной оперативной памяти в кэш. Чтение нескольких последующих элементов выполняется намного быстрее, т. к. они уже находятся в быстрой кэш-памяти.
В большинстве современных микропроцессорах реализована аппаратная предвыборка данных. Она состоит в том, что при последовательном обходе очередные данные считываются из оперативной памяти еще до того, как к ним произошло обращение. За счет этого скорость последовательного обхода данных еще возрастает.
Задание
1. Написать программу, многократно выполняющую чтение элементов массива заданного размера. Элементы массива представляют собой связный список, в котором значение очередного элемента представляет собой номер следующего. Способы обхода массива:
1) Прямой:
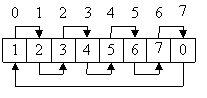

2) Обратный:

3) Случайный:
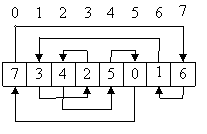

2. Построить графики зависимости среднего времени обращения к элементу массива от размера обрабатываемого массива для трех видов обхода. На графиках должно быть видно влияние кэш-памяти (1 и 2 уровня).
Число обходов массива для тестирования: 10. Перед замером времени выполнить одиночный обход массива для «разогрева» кэш-памяти. Параметры изменения размеров массива:
Pentium III: до 512 KB с шагом 512 B,
Opteron: до 2048 KB с шагом 1 KB.
Указания по выполнению
1. Компилируйте программу с ключом оптимизации –O1, чтобы переменные расположились на регистрах, и не происходило лишних обращений к памяти.
2. Для замера времени с большей точностью и меньшими накладными расходами используйте функцию rdtsc (см. Программы à mark3.c).
Примечания
1. Для удобства переноса данных в Excel лучше выводить значения в две колонки: размер массива и время, а при запуске перенаправить вывод в txt-файл. Текстовый файл (*.txt) можно открыть в Excel-е (а не набирать все это вручную).
2. При выполнении программы на ccfit график может оказаться сильно «замусоренным» посторонними задачами (много высоких пиков). Здесь возможны только два варианта:
- запустить программу в более «спокойное» время, когда будет меньше пользователей работать на сервере,
- запустить программу на более «спокойной» машине, например, Opteron (логин спросить у преподавателя) или домашнем компьютере.
В отчет включить:
· Титульный лист (ФИО, группа),
· Подробная информация о запуске программы:
- на каком процессоре программа запускалась (Pentium III, Opteron, …),
- используемый компилятор и ключ оптимизации,
· Результаты
- графики зависимости среднего времени чтения одного элемента от размера массива для трех способов обхода (все на одной координатной плоскости),
· Вывод
Параметры кэш-памяти некоторых процессоров:
Pentium III (Coppermine)
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 16 KB | 4 | 32 B |
общий кэш L2 | 256 KB | 8 | 32 B |
Pentium 4 (Willamette, Northwood)
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 8 KB | 4 | 64 B |
общий кэш L2 | 256 KB | 8 | 64 B |
Opteron
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 64 KB | 2 | 64 B |
общий кэш L2 | 1024 KB | 16 | 64 B |
Alpha 21264
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 64 KB | 2 | 64 B |
Лабораторная работа №5 Определение степени ассоциативности кэш-памяти
Цель: научиться определять степень ассоциативности кэш-памяти.
Большинство современных микропроцессоров имеют множественно-ассоциативную (наборно-ассоциативную) организацию кэш-памяти. При множественно-ассоциативной организации кэш-память разделена на несколько банков, и каждый блок данных из оперативной памяти может быть помещен в одну из определенного множества (набора) строк кэш-памяти. Число строк в множестве определяется числом банков. Схема кэш-памяти данных первого уровня на Pentium III (16 Кб):
Банки | ||||||
0 | 1 | 2 | 3 | |||
Множества (наборы) | 0 | 32 B | 32 B | 32 B | 32 B | ß 32B * 4 = 128 B |
1 | 32 B | 32 B | 32 B | 32 B | ß 128 B | |
2 | 32 B | 32 B | 32 B | 32 B | ß 128 B | |
… | … | … | … | … | ||
126 | 32 B | 32 B | 32 B | 32 B | ß 128 B | |
127 | 32 B | 32 B | 32 B | 32 B | ß 128 B | |
32B * 128 = = 4 KB | 4 KB | 4 KB | 4 KB | 4 KB * 4 = = 128 B * 128 = = 16384 B = 16 KB |
Номер множества, в которое будет помещен блок данных из памяти, определяется адресом этого блока данных. Например:
Адрес: | Номер множества | Смещение в строке | ||
7 бит | 5 бит |
В какой конкретный элемент множества строка будет записана, определяется алгоритмом замещения (циклический, случайный, LRU, псевдо-LRU, …). Таким образом, блоки, отстоящие на определенное расстояние в памяти (в примере: на 212B = 4096 B = 4 KB), помещаются в одно и то же множество строк. Число элементов в каждом множестве (число банков) называется степенью ассоциативности кэш-памяти. Например, кэш данных L1 в Pentium III имеет объем 16 KB, степень ассоциативности 4 (4-way set-associative), размер строки 32B:
16KB = 4-way * 4 KB = 4-way * 128 множеств * 32B
Данные, расположенные в памяти с шагом на расстоянии 4KB приходятся на одно множество. На все эти данные приходится всего 4 кэш-строки, т. е. 4 * 64B = 256 B. Если выполнять обход данных с шагом 4 KB, то из всех 16 KB кэша L1 будет использоваться всего 256 B, которые будут постоянно перезаписываться (эффект «буксования» кэша). Производительность при этом будет такая же, как при отсутствии кэш-памяти.
Степень ассоциативности кэш-памяти можно определить, выполняя следующий обход данных:
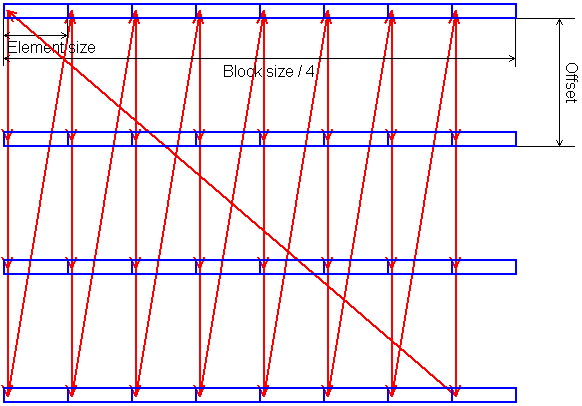
Параметры обхода:
BlockSize - размер обходимого блока данных,
Offset - расстояние между началами соседних блоков.
N - число фрагментов (на картинке N = 4).
Block size должен быть не больше объема кэш-памяти. Offset должно быть кратно величине «размер кэша» / «ассоциативность». Как правило, это степени двоек, так что можно взять заведомо кратное такому значению расстояние (например, 1MB). В тесте выполняется обход массива данных одного и того же размера (BlockSize), который разделен на N частей, отстоящих друг от друга на «плохой шаг» – величину, кратную размеру банка ассоциативности. Изменяя число частей N, мы увидим, как меняется время обхода.
Задание
1. Написать программу, многократно выполняющую чтение элементов массива заданного размера. Элементы массива представляют собой связный список указанного выше вида, в котором значение очередного элемента представляет собой номер следующего.
2. Построить графики зависимости среднего времени обращения к элементу массива от числа фрагментов.
BlockSize = размер кэша данных 1 уровня,
Offset = 1 MB.
Число фрагментов N = 1…20.
По полученному графику определить степень ассоциативности кэш-памяти.
Примерный вид графика:
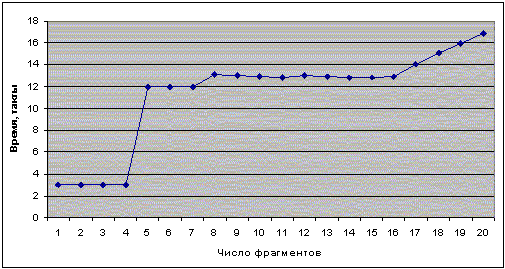
Видно, что при увеличении числа фрагментов с 4 до 5 произошло сильное замедление. Значит, ассоциативность равна 4, что соответствует действительной ассоциативности кэша данных 1 уровня на PentiumIII.
Указания по выполнению
1. Компилируйте программу с ключом оптимизации –O1, чтобы переменные расположились на регистрах, и не происходило лишних обращений к памяти.
2. Для замера времени с большей точностью и меньшими накладными расходами используйте функцию rdtsc (см. Программы à mark3.c).
3. В цикле обхода данных не должно быть «лишних» обращений к памяти (проверить по листингу), т. е. используемые переменные должны быть расположены в регистрах. Если график получается «непохожим», то либо обход выполняется неправильно, либо происходят лишние обращения к памяти.
В отчет включить:
· Титульный лист (ФИО, группа),
· Подробная информация о запуске программы:
- на каком процессоре программа запускалась (Pentium III, Opteron, …),
- используемый компилятор и ключ оптимизации,
· Результаты
- график зависимости среднего времени чтения одного элемента от числа фрагментов,
· Вывод
Параметры кэш-памяти некоторых процессоров:
Pentium III (Coppermine)
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 16 KB | 4 | 32 B |
общий кэш L2 | 256 KB | 8 | 32 B |
Pentium 4 (Willamette, Northwood)
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 8 KB | 4 | 64 B |
общий кэш L2 | 256 KB | 8 | 64 B |
Opteron
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 64 KB | 2 | 64 B |
общий кэш L2 | 1024 KB | 16 | 64 B |
Alpha 21264
Кэш-память | Объем | Ассоциативность | Размер строки |
кэш данных L1 | 64 KB | 2 | 64 B |
СОДЕРЖАНИЕ
Лабораторная работа №1 Использование оптимизирующего компилятора. 3
Лабораторная работа №2 Изучение ассемблерного листинга программы (архитектура x86) 5
Лабораторная работа №3 Использование SIMD-расширений архитектуры x86. 7
Лабораторная работа №4 Исследование влияния кэш-памяти. 10
Лабораторная работа №5 Определение степени ассоциативности кэш-памяти. 12
