
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сегментация границ символов, управляемая моделью слова
, ,
В статье рассказывается об алгоритмах разделения символов (сегментации границ). Эта процедура является необходимой частью любой системы оптического распознавания, функционирующей под управлением лингвистической модели. Рассмотрены отличия от универсальных методов сегментации и особенности реализации.
1. ВВЕДЕНИЕ
Сегментация границ символов (в дальнейшем - сегментация) является важнейшим элементом в процессе оптического ввода (распознавания) образов документов. Это обусловлено тем обстоятельством, что границы рукописных и печатных символов известны в редчайших вариантах оформления документов, например, индексы на почтовых конвертах или специальные случаи использования символов, напечатанных шрифтами с постоянной шириной. Поиск границ символов усложняется дефектами оцифровки (сканирования) документа, такими, как рассыпание и склеивание образов различных символов. В настоящей статье мы будем рассматривать только классы печатных документов.
Использование в программах оптического ввода (OCR) принципов адаптивности, многопроходности и комбинирования алгоритмов распознавания [1,2] требуют их учета в схемах и алгоритмах сегментации. Простейшая схема OCR [3], состоящая из последовательных этапов анализа формата документа, сегментации, определения признаков и классификации, являясь простейшей моделью распознавания, не отвечает на многочисленные вопросы, возникающие при анализе результатов сегментации. Одним из таких вопросов является определение границ применимости методов сегментации, базирующихся на классификации образов отдельных символов. Например, ограничением признаковой классификации является невозможность различения геометрически близких символов, например, пары d и cl или H и I-I [3,4].
Следует отметить существенное различие характеристик алгоритмов распознавания символов (классификации), определяемых на автономных наборах символов, например, таких, как наборы NIST, и алгоритмов распознавания в процессе сегментации. Дело в том, что процедура сегментации порождает значительно число «несимволов», количество и форму которых оценить и учесть в классификации не всегда возможно. Например, метод «гор и долин» нахождения отрезков разделения символов [3,5] дает число отрезков, в 4-5 раз превосходящее число правильных границ, вследствие чего последующий перебор генерирует несимволы в обязательном порядке.
Данная работа посвящена алгоритму сегментации, основанному на модели «слова» и сужении алфавита распознавания.
2. СЕГМЕНТАЦИЯ НА ПОЛНОМ АЛФАВИТЕ
Рассмотрим один из алгоритмов сегментации символов печатных документов, применяемый в реально работающей OCR [6]. Он разделяет символы различных языков, использующих как кириллицу, так и латиницу.
Суть алгоритма [6] состоит в следующем. Зона сегментации (слово или его часть), обладает массивом точек разрезания x0,x1,…,xN. Пусть определен способ извлечения образа для каждой из пар точек xi и xj. Образ символа распознается комбинированным методом Â [1,7], дающим штрафную оценку r(xi,xj). Для путей τ, являющихся подмножеством исходного набора отрезков разрезания, определим меру m(τ) как сумму из оценок пар соседних точек разрезания r(xi,xi+1). Целью сегментации является нахождение пути с минимальной оценкой m(τ). Оптимальный путь определяется с помощью динамического программирования, опирающегося в каждом отрезке на уже построенные оптимальные пути в промежуточные точки, этим достигается построение оптимального пути, ведущего из начальной точки зоны сегментации в ее конечную точку за один проход. При этом алгоритм имеет квадратичную сложность относительно числа точек разрезания. Особое внимание при разработке этого алгоритма уделялось соблюдению аддитивности оценки пути в условиях работы реальных алгоритмов Â распознавания отдельных символов, которые, в частности, могут отказываться распознавать некоторые образы, что требует уточнения способа построения оценки пути [6].
Значительная доля ошибок этого и иных [3,4] алгоритмов сегментации связана с возможностями алгоритма Â распознавания символов, которые зависят от алфавита распознавания. Алфавит распознавания в первом приближении – это множество кодов символов, которое алгоритм Â умеет различать при классификации образов, в первую очередь, заданное процессом обучения алгоритма. Очевидно, что алфавит распознавания во многих случаях отличается от множества кодов символов, которые были использованы при печати документа и которые ожидаются в результате распознавания. Например, алгоритмы распознавания, использующие масштабированное представление образов, не в состоянии различать прописные и строчные буквы с одинаковым начертанием (ОоРрСс). Для устранения этого обстоятельства необходимо комбинирование подобного алгоритма с механизмами, использующими модели полиграфических базовых линий. Однако, не все сходные по начертанию символы могут быть надежно разделены комбинированием. Дело в том, что алфавит распознавания произвольной строки документа достаточно велик и включает в себя следующие группы символов:
- буквы
- цифры
- специальные символы: @#$£§©®
- знаки пунктуации и математические знаки: \,!-/:;”<>(){}[]=.
Большое число близких по начертанию символов (и их частей) в алфавите является причиной возникновения во время сегментации значительного числа близких по оценкам путей, например, изображенных на рисунке 1. Появление несимволов, классифицированных как символы, приводит к ухудшению характеристик качества распознавания в процессе сегментации по отношению к аналогичным характеристикам для отдельных символов, что требует специальных алгоритмов для устранения систематических ошибок сегментации.
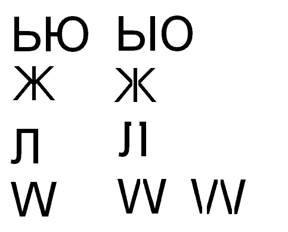
Рис. 1. Неверные пути сегментации с близкими начертаниями символов
(ЬЮ-ЫО, Ж->|<, Л-JI, W-VV-\/\/)
Мы коротко рассмотрим три группы средств устранения ошибок сегментации:
- комбинирование сегментации с эвристиками, снижающими вероятность систематического появления ложных символов, например, появления знаков препинания и пунктуации внутри слова;
- использование словарных и лингвистических механизмов для снижения оценок путей, содержащих невозможные или редкие слова и части слов;
- применение моделей сегментируемых слов, позволяющих сужать алфавит распознавания, например, отнесение слова к цифровому столбцу таблицы значительно повышает точность классификации его символов.
Эти средства обладают рядом недостатков, главным из которых является необходимость распознавать слова, не укладывающиеся в сформулированные эвристики.
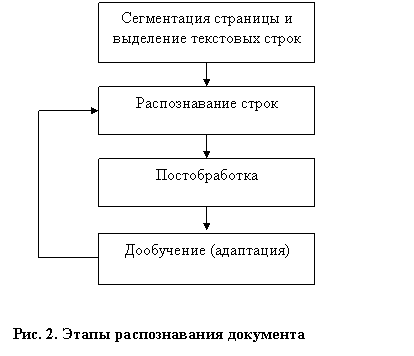
С нашей точки зрения, наиболее перспективным является применение моделей сегментируемых слов. Рассмотрим схему функционирования многопроходной OCR, представленную на рисунке. 2. Этап адаптации включает в себя как построение шрифтов, близких к используемым на странице образам, так и уточнение структуры документа, в частности, суженных алфавитов, относящихся к частям документа. Если в первом цикле распознавания строк сегментация проводится в достаточно широких предположениях, то на последующих этапах возможно использование множества ограничений, относящихся как к описаниям шрифтов, так и к модели слов, распознаваемых вторично. В частности, использование словарных механизмов позволяет формулировать следующую проблему относительно ненадежно распознанных слов: возможно ли распознать группу символов таким образом, чтобы получить в результате одно из слов заданной группы?
 |
Решение таким образом поставленной задачи позволяет значительно повысить качество сегментации и классификации. Это ограничение на слово (в отличие от ограничений на алфавит) требует существенных изменений в базовом алгоритме [6] сегментации слова. Дальнейшее изложение будет посвящено содержанию алгоритма сегментации, основанного на наложении группы слов на набор геометрических образов.
3. СЕГМЕНТАЦИЯ НАЛОЖЕНИЕМ ГРУППЫ СЛОВ
Итак, пусть задан фрагмент строки (слово) и задана группа слов-кандидатов. Необходимо определить, на какое из них наиболее похож заданный фрагмент, и оценить степень похожести. Рассмотрим различные подходы к решению этой задачи.
Упомянутый в разделе 2 алгоритм [6] непосредственно не применим для решения поставленной задачи, потому что распознавание отдельных символов в нем производится независимо от других символов в слове. Пусть, к примеру, заданы слова-кандидаты: почта и ночка. Алфавит, таким образом, состоит из букв: а, к, н, о, п, т, ч. Допустим, оценки распознавания букв слова составили (рис 3):
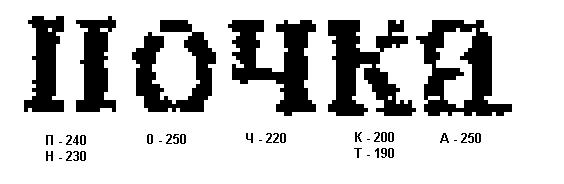
Рис. 3. Пример наложения группы из двух слов («почта» и «ночка»)
Алгоритм выберет для первой буквы версию «п», а для четвертой – «к», поскольку оценка для всего слова при этом будет максимальной, несмотря на то, что получается слово «почка», которого нет среди кандидатов «почта» и «ночка».
Подобная задача возникает при распознавании речи [8]. Применительно к нашим условиям алгоритм [8] можно изложить следующим образом.
Пусть задано слово a=(a1,a2, ... ,av) из v символов. Требуется сегментировать заданный фрагмент на v частей, чтобы получить наилучшее соответствие слову a, и вычислить оценку соответствия. Для определенности будем считать, что оптимальный путь тот, что имеет минимальную меру. [П.1] Кроме того, предполагаем аддитивность меры пути, то есть, если путь L разбить на два подпути L1 и L2, то
m(L) = m(L1) + m(L2).
Алгоритм состоит из следующих шагов.
(А1) Из геометрических соображений находим множество возможных точек разрезания x0, ... ,xt.
(А2) Для каждой точки разрезания xi вычисляем меру по формуле:
m1i = a1(x0,xi), i = 1, ... ,t
где - a1(x0,xi) - оценка распознавания (штрафная функция) сегмента (x0,xi) с алфавитом, состоящим из одной буквы a1. Величина m1i является мерой оптимального (и единственного) пути, ведущего из начала фрагмента (точки x0) в точку xi и состоящего из одного символа (в данном случае a1). Очевидно что, вычисления достаточно проводить для i=1, ... ,t-v+1.
(А3) Для каждой точки разрезания xi вычисляем меру по формуле
mji = min(m(j-1)k + aj(xk, xi)), i = j, ... ,t (1)
k<i
Пункт (А3) выполняем для значений j = 2, ... , v. Аналогично пункту (А2), вычисления достаточно проводить для i=j, ... , t-v+j.
Нетрудно видеть, что в пункте (А3) для каждого j вычисляется слой мер, так что mji представляет собой меру пути, ведущего из начала в точку xi и состоящего ровно из j символов.
(А4) Мера mvt является искомой оценкой.
Докажем, что mvt является оценкой оптимального пути. Доказательство проведем индукцией по j.
- Для j = 1 в каждую точку xi ведет единственный, а потому оптимальный, путь, представляющий один символ. Мера mvt соответствует максимальному интервалу
mvt = m1t = a1(x0,xt).
- Пусть для j = p имеем для каждой точки xi меру mpi, i = p, ... ,t-1, оптимального пути длины p, приходящего из начала в точку xi. Докажем, что меры, вычисленные по формуле (1), представляют меры оптимальных путей длины p+1. Пусть для точки xr, p+1 £ r £ t, существует путь длины p+1 с мерой mr < m(p+1)r. Рассмотрим предыдущую точку этого пути xq. Последнее неравенство можно тогда переписать так:
mq + a(p+1)(xq, xr)) < mpq + a(p+1)(xq, xr)),
где mq - мера части оптимального пути длиной p. Отсюда mq < mqp, то есть для точки xq существует путь длиной p с оценкой лучшей, чем mpq, что противоречит предположению индукции.
Недостатком рассмотренного алгоритма является ресурсоемкость. При вычислении j-того слоя для каждой из (t-v) точек нужно провести в среднем (t-v )/2 распознаваний. Таким образом, общее количество распознаваний равно v*(t-v)*(t-v)/2. Если требуется провести сравнение с m словами, то полученную величину нужно умножить на m.
Рассмотрим модификацию алгоритма, позволяющую сократить объем вычислений при нахождении соответствия с несколькими словами. Пусть заданы m слов: ak = (ak1,ak2, ... ,a![]() ), k=1, ... ,m. Определим набор алфавитов
), k=1, ... ,m. Определим набор алфавитов
gi = {a1i, a2i, ... ,ami}, i=1,..,max(lk)
k
составленных из первой, второй и т. д. букв заданного набора слов. Алфавиты будут иметь разный размер, если слова имеют разную длину. Будем считать, что слова и алфавиты упорядочены по убыванию размера.
(В1) Из геометрических соображений находим множество возможных точек разрезания x0, ... ,xt.
(В2) Для каждой точки разрезания xi вычисляем набор мер по формуле:
mk1i=ak1(x0,xi), i=1, ... ,t, k=1, ... ,m
Здесь, чтобы получить меру akl(x0,xi), распознаем сегмент (x0, xi) на алфавите g1 и берем оценку символа ak1.
(В3) Для каждой точки разрезания xi вычисляем набор мер по формуле:
mkji = min(mk(j-1)s + ajk(xs, xi)), i=j, ... ,t, k=1, ... ,m
s < i
используя алфавит gj. Если размер алфавита mj < m, то оставшиеся меры не вычисляем. Пункт В3 выполняем для значений j = 2, ... ,l1 (поскольку l1 - максимальная из длин слов).
(В4) Искомой мерой для k - го слова является m![]() .
.
(В5) Наилучшее соответствие достигается на слове с номером
s = argmin m![]()
k
В сравнении с предыдущим алгоритмом количество вычисляемых мер не изменилось, но количество распознаваний сокращается в m раз для m слов одинаковой длины, за счет того, что вместо m распознаваний сегмента с однобуквенным алфавитом производится одно распознавание с m буквенным алфавитом.
В рассмотренных алгоритмах предполагалось, что слово начинается и заканчивается на границах заданного фрагмента. Однако реально фрагмент может оказаться шире за счет грязи, приклеившейся с краев. В других случаях приходится искусственно присоединять к нему близлежащие компоненты, которые могут оказаться частями рассыпавшихся букв. Все эти случаи могут быть учтены добавлением в начале и конце каждого слова-кандидата по одному фиктивному символу. Распознавание такого символа не производится, а оценка выставляется из эмпирических соображений исходя из геометрических размеров и формы.

Рис. 4. Добавление фиктивного символа для уточнения границы фрагмента.
Рассмотрим пример, приведенный на рис. 4. Здесь подлежит сегментации фрагмент из трех склеившихся букв. Априори неизвестно, где проходит граница фрагмента: по сечению A или B. Проведение границы по сечению A означает, что компонента будет приклеена к левому символу, а по сечению B – что она будет отброшена. Чтобы предоставить выбор алгоритму, будем считать, что слово состоит из четырех символов, причем у первого (фиктивного) ширина может быть нулевой, а оценка зависит от его ширины: максимальна при нулевой ширине и убывает при возрастании ширины – и будем производить сегментацию не на три, а на четыре символа. Тогда все ненужные компоненты в начале фрагмента алгоритм поместит в фиктивный символ. По окончании сегментации мы его отбросим, а оставшиеся три символа будут представлять собой распознанное слово.
4. ОБЛАСТИ ПРИМЕНЕНИЯ
Сегментация границ символов, базирующаяся на наложении известных слов на образ слова может быть использована не только в проверке гипотез словарных механизмов в многопроходной схеме распознавания документа с неизвестной структурой. Не меньший интерес представляет аналогичная сегментация при разборе документов с известной структурой, содержащие заранее описанные статические тексты и ключевые слова, которые могут быть найдены более точно и более быстро, нежели в процессе распознавания с произвольной сегментацией.
Авторам представляется перспективным использование нескольких схем сегментации (как сложных, так и простых) в одном процессе распознавания с возможностью комбинирования результатов сегментации для оптимизации общей целевой функции системы оптического распознавания.
ЛИТЕРАТУРА
1. , , Адаптивное распознавание символов. В сб. "Интеллектуальные технологии ввода и обработки информации", 1998, с. 39-56
2. , , Методы распознавания грубых объектов. В сб. "Развитие безбумажных технологий в организациях", 1999, с. 290-311
3. Casey R., Lecolinet E. A Survey of Method and Strategies in Character Segmentation // IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 18, № 7, 1996, pp. 690-706
4. Nagy G. Twenty Years of Document Image Analysis in PAMI // IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, № 1, 2000, pp. 38-62
5. Tsujimoto S., Asada H. Major Components of a Complete Text Reading System // IEEE, Vol. 80, № 7, pp.
6. , , Распознавание печатных текстов. В сб. "Методы и средства работы с документами", 2000, с. 31-51
7. Kim J., Seo K., Chung K. A Systematic Approach to Classifier Selection on Combining Multiple Classifiers for Handwritten Digit Recognition // IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 20, № 12, 1998, pp. 459-462
8. C. S. Myers, L. R. Rabiner. A Level Building Dynamic Time Warping Algorithm for Connected Word Recognition // IEEE Trans. on ASSP, v. 29, № 2, 1981, pp. 284-290
[П.1] Определил меру в разделе 2
