
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
I. Выдача - Берет команду из очереди команд ПТ. Если операция является операцией ПТ, выдает ее при наличии свободной станции резервирования и посылает операнды на станцию резервирования, если они находятся в регистрах. Если операция является операцией загрузки или записи, она может выдаваться при наличии свободного буфера. При отсутствии свободной станции резервирования или свободного буфера возникает структурный конфликт и команда приостанавливается до тех пор, пока не освободится станция резервирования или буфер.
II. Выполнение - Если один или более операндов команды не доступны по каким либо причинам, контролируется состояние CDB и ожидается завершение вычисления значений нужного регистра. На этой стадии выполняется контроль конфликтов типа RAW. Когда оба операнда доступны, выполняется операция.
III. Запись результата - Когда становится доступным результат, он записывается на CDB и оттуда в регистры и любое функциональное устройство, ожидающее этот результат.
Хотя эти шаги в основном похожи на аналогичные шаги в централизованной схеме управления, имеются три важных отличия. Во-первых, отсутствует контроль конфликтов типа WAW и WAR - они устраняются как побочный эффект алгоритма. Во-вторых, для трансляции результатов используется CDB, а не схема ожидания готовности регистров. В-третьих, устройства загрузки и записи рассматриваются как основные функциональные устройства.
Спекулятивное выполнение
Построение любой, желательно оптимальной последовательности, строится на методах предсказания, т. е. спекулятивно. Примером является последовательность команд построенных на основе предсказания команд ветвления (условные операторы)
Процессор вычисляет команды на обоих концах команды ветвления. А результаты вычисления сохраняются как предположительные (спекулятивные). На каком то этапе, порядок инструкций восстанавливается.
Существуют следующие варианты спекулятивного выполнения:
- предикация (predication) - одновременное исполнение нескольких ветвей программы вместо предсказания переходов (выполнения наиболее вероятного); опережающее чтение данных (speculative loading), то есть загрузка данных в регистры с опережением, до того, как определилось реальное ветвление программы (переход управления).
Эти возможности осуществляются комбинированно - при компиляции и выполнении программы.
Предикация.
Обычный компилятор транслирует оператор ветвления (например, if-then-else) в блоки машинного кода, расположенные последовательно в потоке. Обычный процессор в зависимости от исхода условия исполняет один из этих базовых блоков, пропуская все другие. Более развитые процессоры пытаются прогнозировать исход операции и предварительно выполняют предсказанный блок. При этом в случае ошибки много тактов тратится впустую. Сами блоки зачастую весьма малы - две или три команды, - а ветвления встречаются в коде в среднем каждые шесть манд. Такая структура кода делает крайне сложным его параллельное выполнение.
При использовании предикации компилятор, обнаружив оператор ветвления в исходной программе, анализирует все возможные ветви (блоки) и помечает их метками или предикатами (predicate). После этого он определяет, какие из них могут быть выполнены параллельно (из соседних, независимых ветвей).
В процессе выполнения программы ЦП выбирает команды, которые взаимно независимы и распределяет их на параллельную обработку. Если ЦП обнаруживает оператор ветвления, он не пытается предсказать переход, а начинает выполнять все возможные ветви программы.
Таким образом, могут быть обработаны все ветви программы, но без записи полученного результата. В определенный момент процессор наконец «узнает» о реальном исходе условного оператора, записывает в память результат «правильной ветви» и отменяет остальные результаты.
В то же время, если компилятор не «отметил» ветвление, процессор действует как обычно - пытается предсказать путь ветвления и так далее Испытания показали, что описанная технология позволяет устранить более половины ветвлений в типичной программе, и, следовательно, уменьшить более чем в 2 раза число возможных ошибок в предсказаниях.
Опережающее чтение данных
Опережающее чтение (предварительная загрузка данных, чтение по предположению) разделяет загрузку данных в регистры и их реальное использование, избегая ситуации, когда процессору приходится ожидать прихода данных, чтобы начать их обработку.
Прежде всего, компилятор анализирует программу, определяя команды, которые требуют приема данных из оперативной памяти. Там, где это возможно, он вставляет команды опережающего чтения и парную команду контроля опережающего чтения (speculative check). В то же время компилятор переставляет команды таким образом, чтобы ЦП мог их обрабатывать параллельно.
В процессе работы ЦП встречает команду опережающего чтения и пытается выбрать данные из памяти. Может оказаться, что они еще не готовы (результат работы блока команд, который еще не выполнился). Обычный процессор в этой ситуации выдает сообщение об ошибке, однако система откладывает «сигнал тревоги» до момента прихода процесса в точку «команда проверки опережающего чтения». Если к этому моменту все предшествующие подпроцессы завершены и данные считаны, то обработка продолжается, в противном случае вырабатывается сигнал прерывания.
Буфер прогнозирования условных переходов
Простейшей схемой динамического прогнозирования направления условных переходов является буфер прогнозирования условных переходов (branch-prediction buffer) или таблица "истории" условных переходов (branch history table). Буфер прогнозирования условных переходов представляет собой небольшую память, адресуемую с помощью младших разрядов адреса команды перехода. Каждая ячейка этой памяти содержит один бит, который говорит о том, был ли предыдущий переход выполняемым или нет. Это простейший вид такого рода буфера. В нем отсутствуют теги, и он оказывается полезным только для сокращения задержки перехода в случае, если эта задержка больше, чем время, необходимое для вычисления значения целевого адреса перехода. В действительности мы не знаем, является ли прогноз корректным (этот бит в соответствующую ячейку буфера могла установить совсем другая команда перехода, которая имела то же самое значение младших разрядов адреса). Но это не имеет значения. Прогноз - это только предположение, которое рассматривается как корректное, и выборка команд начинается по прогнозируемому направлению. Если же предположение окажется неверным, бит прогноза инвертируется.
Двухбитовая схема прогнозирования в действительности является частным случаем более общей схемы, которая в каждой строке буфера прогнозирования имеет n-битовый счетчик. Этот счетчик может принимать значения от 0 до 2n - 1. Тогда схема прогноза будет следующей:
- Если значение счетчика больше или равно 2n-1 (точка на середине интервала), то переход прогнозируется как выполняемый. Если направление перехода предсказано правильно, к значению счетчика добавляется единица (если только оно не достигло максимальной величины); если прогноз был неверным, из значения счетчика вычитается единица. Если значение счетчика меньше, чем 2n-1, то переход прогнозируется как невыполняемый. Если направление перехода предсказано правильно, из значения счетчика вычитается единица (если только не достигнуто значение 0); если прогноз был неверным, к значению счетчика добавляется единица.
1) Любая машинная команда рассматривается, как некоторое сложное действие, которое состоит из последовательности элементарных действий над словами информации – микроопераций.
2) Порядок следования микроопераций зависит не только от значений преобразуемых слов, но также от их информационных сигналов, вырабатываемых операционным автоматом. Примерами таких сигналов могут быть признаки результата операции, значения отдельных битов данных и т. п.
3) Процесс выполнения машиной команды описывается в виде некоторого алгоритма в терминах микроопераций и логических условий. Описание информационных сигналов – микропрограмма
4) Микропрограмма служит не только для обработки данных, но и обеспечивает управление работой всего устройства в целом – принцип микропрограммного управления
Операционный блок обеспечивает выполнение определенного набора микроопераций и вычисление необходимых логических условий. Управляющий автомат, согласно заданной машинной команде, генерирует необходимую последовательность сигналов, инициирующих соответствующие микрооперации, согласно микропрограмме и значениями логических условий, формируемых операционным в ходе обработки по микропрограмме. Таким образом, микропрограммы выступают, с одной стороны, в роли закона по которому выполняется обработка, с другой стороны, закон, по которому работает управляющий блок.
Все элементы в операционном автомате (ОП) соединяются между собой с помощью шин, которые обеспечивают передачу слов с выхода одного операционного элемента на вход другого. В зависимости от выполняемых микроопераций ОЭ делятся на разновидности: шина, регистр, счетчик, сумматор, схема сравнения, дешифратор, шифратор и т. д.
Суперскалярные архитектуры. Один конвейер – хорошо, а два – лучше
Одна из возможных схем процессора с двумя конвейерами показана на рис. 2.4. В ее основе лежит конвейер, изображенный на рисунке. Здесь общий блок выборки команд вызывает из памяти сразу по две команды и помещает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать из-за ресурсов (например, регистров), и ни одна из них не должна зависеть от результата выполнения другой. Как и в случае с одним конвейером, либо компилятор должен гарантировать отсутствие нештатных ситуаций (когда, например, аппаратура не обеспечивает проверку команд на несовместимость и при обработке таких команд выдает некорректный результат), либо за счет дополнительной аппаратуры конфликты должны выявляться и устраняться непосредственно в ходе выполнения команд.
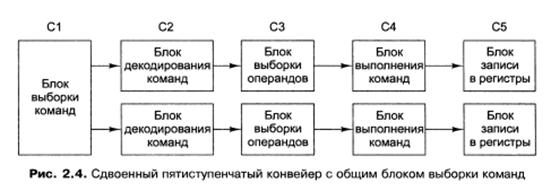
Сначала конвейеры (как сдвоенные, так и обычные) использовались только в RISC-компьютерах. У процессора 386 и его предшественников их не было. Конвейеры в процессорах компании Intel появились, только начиная с модели 486. Процессор 486 имел один пятиступенчатый конвейер, a Pentium — два таких конвейера. Похожая схема изображена на рис. 2.4, но разделение функций между второй и третьей ступенями (они назывались декодер 1 и декодер 2) было немного другим. Главный конвейер (u-конвейер) мог выполнять произвольные команды. Второй конвейер (v-конвейер) мог выполнять только простые команды с целыми числами, а также одну простую команду с плавающей точкой (FXCH).
Имеются сложные правила определения, является ли пара команд совместимой в отношении возможности параллельного выполнения. Если команды, входящие в пару, были сложными или несовместимыми, выполнялась только одна из них (в u-конвейере). Оставшаяся вторая команда составляла затем пару со следующей командой. Команды всегда выполнялись по порядку. Таким образом, процессор Pentium содержал особые компиляторы, которые объединяли совместимые команды в пары и могли порождать программы, выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали, что программы, в которых применяются операции с целыми числами, при той же тактовой частоте на Pentium выполняются почти в два раза быстрее, чем на 486. Вне всяких сомнений, преимущество в скорости было достигнуто благодаря второму конвейеру. Переход к четырем конвейерам возможен, но требует громоздкого аппаратного обеспечения. Вместо этого используется другой подход. Основная идея — один конвейер с большим количеством функциональных блоков, как
показано на рис. 2.5. Pentium II, к примеру, имеет сходную структуру. В 1987 году для обозначения этого подхода был введен термин суперскалярная архитектура. Однако подобная идея нашла воплощение еще тридцатью годами ранее в компьютере CDC 6600. Этот компьютер вызывал команду из памяти каждые 100 не и помещал ее в один из 10 функциональных блоков для параллельного выполнения. Пока команды выполнялись,
центральный процессор вызывал следующую команду.
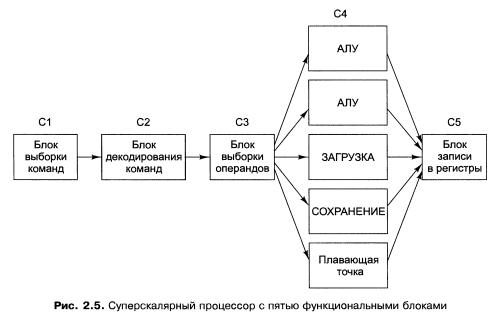
Со временем значение понятия «суперскалярный» несколько изменилось. Теперь суперскалярными называют процессоры, способные запускать несколько команд (зачастую от четырех до шести) за один тактовый цикл. Естественно, чтобы передавать все эти команды, в суперскалярном процессоре должно быть несколько функциональных блоков. Поскольку в процессорах этого типа, как правило, предусматривается один конвейер, его устройство обычно соответствует рис. 2.5. В свете такой терминологической динамики на сегодняшний день можно утверждать, что компьютер 6600 не был суперскалярным с технической точки зрения — ведь за один тактовый цикл в нем запускалось не больше одной команды.
Однако при этом был достигнут аналогичный результат — команды запускались быстрее, чем выполнялись. На самом деле разница в производительности между ЦП с циклом в 100 не, передающим за этот период по одной команде четырем функциональным блокам, и ЦП с циклом в 400 не, запускающим за это время четыре команды, трудноуловима. В обоих процессорах соблюдается принцип превышения скорости запуска над скоростью управления; при этом рабочая нагрузка распределяется между несколькими функциональными блоками. Отметим, что на выходе ступени 3 команды появляются значительно быстрее, чем ступень 4 способна их обрабатывать. Если бы на выходе ступени 3 команды появлялись каждые 10 нс, а все функциональные блоки делали свою работу также за 10 нс, то на ступени 4 всегда функционировал бы только один блок, что сделало бы саму идею конвейера бессмысленной. В действительности большинству функциональных блоков ступени 4 (точнее, обоим блокам доступа к памяти и блоку выполнения операций с плавающей точкой) для обработки команды требуется значительно больше времени, чем занимает один цикл. Как видно из рис. 2.5, на ступени 4 может быть несколько АЛУ.
VLIW процессоры
Архитектура с командными словами сверхбольшой длины или со сверхдлинными командами (VLIW, Very Long Instruction Word) известна с начала 80-х. VLIW - это набор команд, организованных наподобие горизонтальной микрокоманды в микропрограммном устройстве управления.
Идея VLIW базируется на том, что задача эффективного планирования параллельного выполнения нескольких команд возлагается на «разумный» компилятор. Такой компилятор вначале исследует исходную программу с целью обнаружить все команды, которые могут быть выполнены одновременно, причем так, чтобы это не приводило к возникновению конфликтов. В процессе анализа компилятор может даже частично имитировать выполнение рассматриваемой программы. Наследующем этапе компилятор пытается объединить такие команды в пакеты, каждый из которых рассматривается так одна сверхдлинная команда. Объединение нескольких простых команд в одну сверхдлинную производится по следующим правилам:
· количество простых команд, объединяемых в одну команду сверхбольшой длины, равно числу имеющихся в процессоре функциональных (исполнительных) блоков (ФБ);
· в сверхдлинную команду входят только такие простые команды, которые исполняются разными ФБ, то есть обеспечивается одновременное исполнение всех составляющих сверхдлинной команды
Длина сверхдлинной команды обычно составляет от 256 до 1024 бит. Такая метакоманда содержит несколько полей (по числу образующих ее простых команд), каждое из которых описывает операцию для конкретного функционального блока. Сказанное иллюстрирует рис, 13,26, где показан возможный формат сверхдлинной команды и взаимосвязь между ее полями и ФБ, реализующими отдельные операции.
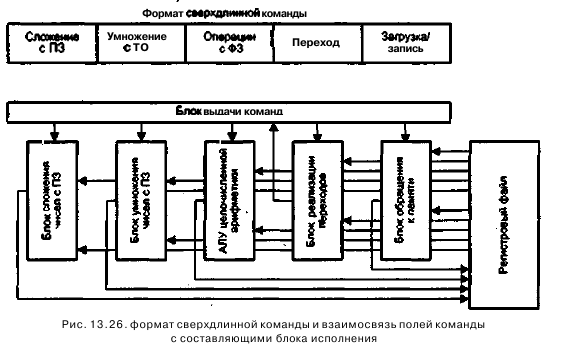
Как видно из рисунка, каждое поле сверхдлинной команды отображается на свой функциональный блок, что позволяет получить максимальную отдачу от аппаратуры блока исполнения команд. VLIW-архитектуру можно рассматривать как статическую суперскалярную архитектуру. Имеется в виду, что распараллеливание кода производится на этапе компиляции, а не динамически во время исполнения. То, что в выполняемой сверхдлинной команде исключена возможность конфликтов, позволяет предельно упростить аппаратуру VLIW-процессора и, как следствие, добиться более высокого быстродействия.
В качестве простых команд, образующих сверхдлинную, обычно используются команды RISC-типа, поэтому архитектуру VLIW иногда называют пocтRISC-apхитектурой. Максимальное число полей в сверхдлинной команде равно числу вычислительных устройств и обычно колеблется в диапазоне от 3 до 20. Все вычислительные устройства имеют доступ к данным, хранящимся в едином многопортовом регистровом файле. Отсутствие сложных аппаратных механизмов, характерных для суперскалярных процессоров (предсказание переходов, внеочередное исполнение и т. д.), дает значительный выигрыш в быстродействии и возможность более эффективно использовать площадь кристалла. Подавляющее большинство цифровых сигнальных процессоров и мультимедийных процессоров с производительностью более 1 млрд операций/с базируется на VLIW-архитектуре. Серьезная проблема VLIW - усложнение регистрового файла и связей этого файла с вычислительными устройствами.
Преимущества.
1. Использование компилятора позволяет устранить зависимости между командами до того, как они будут реально выполняться, в отличие от суперскалярных процессоров, где такие зависимости приходится обнаруживать и устранять "на лету".
2. Отсутствие зависимостей между командами в коде, сформированном компилятором, ведет к упрощению аппаратных средств процессора и за счет этого к существенному подъему его быстродействия.
3. Наличие множества функциональных блоков дает возможность выполнять несколько команд параллельно.
Недостатки.
1. Требуется новое поколение компиляторов, способных проанализировать программу, найти в ней независимые команды, связать такие команды в строки длиной от 256 до 1024 бит, обеспечить их параллельное выполнение.
2. Компилятор должен учитывать конкретные детали аппаратных средств.
3. При определенных ситуациях программа оказывается недостаточно гибкой
Основные сферы применения.
VLIW-процессоры пока еще распространены относительно мало. Основными сферами применения технологии VLIW-являются цифровые сигнальные процессоры и вычислительные системы, ориентированные на архитектуру IA-64. Наиболее известной была VLIW-система фирмы Multiflow Computer, Inc. (Уже не существующей.) В России VLIW-концепция была реализована в суперкомпьютере Эльбрус 3-1 и получила дальнейшее развитие в его последователе - Эльбрус-2000 (Е2к). К VLIW можно причислить семейство сигнальных процессоров TMS320C6x фирмы Texas Instruments. С 1986 года ведутся исследования VLIW-архитектуры в IBM. В начале 2000 года фирма Transmeta заявила процессор Crusoe, представляющий собой программно-аппаратный комплекс. В нем команды микропроцессоров серии х86 транслируются в слова VLIW длиной 64 или 128 бит. Оттранслированные команды хранятся в кэш-памяти, а трансляция при многократном их использовании производится только один раз. Ядро процессора исполняет элементы кода в строгой последовательности.
EPIC архитектуры
Дальнейшим развитием идеи VLIW стала новая архитектура IA-64 — совместная разработка фирм Intel и Hewlett-Packard (IA - это аббревиатура от Intel Architecture). В IA-64 реализован новый подход, известный как вычисления с явным параллелизмом команд (EPIC, Explicitly Parallel Instruction Computing) и являющийся усовершенствованным вариантом технологии VLIW. Первым представителем данной стратегии стал микропроцессор Itanium компании Intel. Корпорация HewlettPackard также реализует данный подход в своих разработках.
В архитектуре IA-64 предполагается наличие в процессоре разрядных регистров общего назначения (РОН) и разрядных регистров с плавающей запятой. Кроме того, процессор IA-64 содержит 64 однобитовых регистра предикатов.
Формат команд в архитектуре IA-64 показан на рис. 13.27.
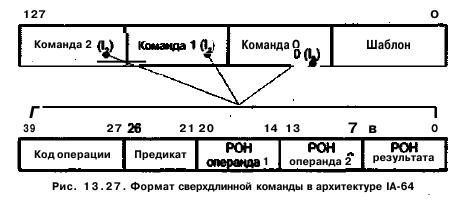
Команды упаковываются (группируются) компилятором в сверхдлинную команду — связку (bundle) длиною в 128 разрядов. Связка содержит три команды и шаблон, в котором указываются зависимости между командами (можно ли с командой I0 запустить параллельно I1 или же I1 должна выполниться только после Iо), а также между другими связками (можно ли с командой I2 из связки So запустить параллельно команду I3 из связки S1).
Перечислим все варианты составления связки из трех команд:
- I0 || I1 || 12 — все команды исполняются параллельно;
- Iо & I1 || I г — сначала I0, затем исполняются параллельно I1 и I2;
- I0 || I 1 & I2 - параллельно обрабатываются I0 и I1 после них - I2;
- I0& I1 & I2 — команды исполняются в последовательности I0,I1, I2.
Одна связка, состоящая из трех команд, соответствует набору из трех функциональных блоков процессора. Процессоры IA-64 могут содержать разное количество таких блоков, оставаясь при этом совместимыми по коду. Благодаря тому что в шаблоне указана зависимость и между связками, процессору с N одинаковыми блоками из трех ФБ будет соответствовать сверхдлинная команда из N х 3 команд (Nсвязок). Тем самым обеспечивается масштабируемость IA-64.
Поле каждой из трех команд в связке, в свою очередь, состоит из пяти полей:
- 13-разрядного поля кода операции;
- 6-разрядного поля предикатов, хранящего номер одного из 64 регистров предиката;
- 7-разрядного поля первого операнда (первого источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится первый операнд;
- 7-разрядного поля второго операнда (второго источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится второй операнд;
- 7-разрядного поля результата (приемника), где указывается номер регистра общего назначения или регистра с плавающей запятой, куда должен быть занесен результат выполнения команды
Следует пояснить роль подполя предикатов. Предикация - это способ обработки условных ветвлений. Суть в том, что еще компилятор указывает, что обе ветви выполняются на процессоре параллельно, ведь EPIC-процессоры должны иметь много функциональных блоков. Если в исходной программе встречается условное ветвление (по статистике — через каждые шесть команд), то команды из разных ветвей помечаются разными регистрами предиката (команды имеют для этого соответствующие поля), далее они выполняются совместно, но их результаты не записываются, пока значения регистров предиката (РП) не определены. Когда, наконец, вычисляется условие ветвления, РП, соответствующий «правильной» ветви, устанавливается в 1, а другой - в 0. Перед записью результатов процессор проверяет поле предиката и записывает результаты только тех команд, поле предиката которых указывает на РП с единичным значением. Предикаты формируются как результат сравнения значений, хранящихся в двух регистрах. Результат сравнения («Истина» или «Ложь») заносится в один из РП, но одновременно с этим во второй РП записывается инверсное значение полученного результата. Такой механизм позволяет процессору более эффективно выполнять конструкции типа I F - T H E N-E L S E. Логика выдачи команд на исполнение сложнее, чем в традиционных процессорах типа VLIW, но намного проще, чем у суперскалярных процессоров с неупорядоченной выдачей. По мнению специалистов Intel и HP, концепция EPIC, сохраняя все достоинства архитектурной организации VLIW, свободна от большинства ее недостатков. Особенностями архитектуры EPIC являются:
- большое количество регистров;
- масштабируемость архитектуры до большого количества функциональных блоков. Это свойство представители компаний Intel и HP называют наследственно масштабируемой системой команд (Inherently Scaleable Instruction Set);
- явный параллелизм в машинном коде. Поиск зависимостей между командами осуществляет не процессор, а компилятор;
- предикация — команды из разных ветвей условного предложения снабжаются полями предикатов (полями условий) и запускаются параллельно;
- предварительная загрузка — данные из медленной основной памяти загружаются заранее.
Первые процессоры Intel 80 86
Корпорация Intel разработала три типа ISA, которые ориентируются на различные секторы рынка. Для их именования часто используется акроним из выражения IntelArchitecture, IA
- Архитектура IA-32 предназначена для выполнения массовых 32-разрядных приложения на ПК начального уровня и реализована в следующих семействах процессоров:
- Intel Celeron и Intel Pentium (в корпусе FC-PGA2); процессорах Intel, использующих технологии ультранизкого напряжения питания; Intel Core Duo.
- Архитектура набора команд IA-64 реализована в семействе процессоров Intel Itanium.
- Архитектура Intel 64 предназначена для современных ПК и серверов среднего уровня, оптимизированных для выполнения 64-разрядных приложений. Эта архитектура реализована в следующих семействах процессоров:
- Intel Xeon; Intel Core 2 Duo.
Intel архитектура 64
Знание архитектуры процессора, или в более узком смысле, его системы команд, необходимо не только для программирующих на языке ассемблера данного процессора. В учебные курсы в области информатики традиционно входят дисциплины, в которых рассматривается программирование на ассемблере. В период доминирования больших универсальных ЭВМ большинство специалистов знали ассемблер мэйнфреймов IBM S/360-370 (соответственно ЕС ЭВМ). Затем доминирующим стал, вероятно, ассемблер x86. Современные специалисты по компьютерным архитектурам хорошо знают и системы команд RISC-процессоров.
Системы команд современных RISC-процессоров во многом похожи друг на друга. Например, говорят, что в этом смысле MIPS и Alpha близки друг к другу. Однако появление архитектуры IA-64, которая претендует на монополию на рынке микропроцессоров, разработчики из HP и Intel характеризуют как наступление эры "пост-RISC". Доступная информация свидетельствует, что IA-64 революционным образом отличается от предшественников, даже от своих прямых предков таких, как HP PA-RISC. Процессоры с архитектурой IA-64 (Merced, McKinley и т. д.) могут обойти RISC-процессоры по производительности.
Со временем архитектура IA-64 способна вытеснить в будущем x86 (IA-32) не только на рынке, но и в качестве багажа "базовых знаний" специалистов по информатике. Однако необходимость разработки для IA-64 весьма сложных компиляторов и трудности с созданием оптимизированных машинных кодов может вызвать дефицит специалистов, пишущих на ассемблере IA-64, особенно на начальных этапах. Это делает актуальным анализ IA-64.
На момент подготовки статьи детали микроархитектуры процессора Merced, получившего официальное название Itanium, все еще не раскрыты. Официальная информация [1,2] позволяет сделать определенные предположения о характеристиках Itanium. Укажем также на публикацию по микроархитектуре E2K [3] отечественной разработки, имеющей близкие к IA-64 архитектурные особенности.
Основным источником данных для данной статьи послужили, естественно, публикации [1,2]. Мы остановимся в первую очередь на концептуально новых особенностях IA-64 и общем описании. Более традиционные части системы команд IA-64 напоминают обычный набор команд RISC, в первую очередь архитектуры PA-RISC. Cовместимость с PA-RISC в IA-64 обеспечивается за счет динамической трансляции команд (т. е. подобно Compaq/DEC FX!32). Применительно к прикладным программам такой подход оказывается вполне эффективным благодаря близости части команд PA-RISC к соответствующим командам IA-64.
Что касается аппаратно поддерживаемой совместимости с архитектурой IA-32, то, с точки зрения автора, это тема для отдельного разговора; основной интерес представляет собой в первую очередь принципиально новые черты IA-64. По мнению автора, аппаратная совместимость с IA-32 препятствует эффективному развитию IA-64 и росту производительности. Косвенным подтверждением этому служат неофициальные "приватные" данные о том, что McKinley, производительность которого должна быть гораздо выше Merced, якобы не имеет столь развитых средств аппаратной поддержки IA-32, как у Merced.
Наиболее кардинальным нововведением IA-64 по сравнению с RISC является "явный параллелизм команд (EPIC - Explicitly Parallel Instruction Computing), привносящий в IA-64 некоторые элементы, напоминающие архитектуру "сверхбольшого командного слова" (VLIW - Very Large Instruction Word). В обеих архитектурах явный параллелизм представлен уже на уровне команд, управляющих одновременной работой функциональных исполнительных устройств (ФИУ). Соответствующие "широкие команды" HP/Intel назвали связками (bundle).

Рис. 1. Формат связки команд IA-64
Связка имеет длину 128 разрядов (рис. 1). Она включает 3 поля - "слота" для команд длиной 41 разрядов каждая, и 5-разрядное поле шаблона. Предполагается, что команды связки могут выполняться параллельно разными ФИУ. Возможные взаимозависимости, препятствующие параллельному выполнению команд связки, отражаются в поле шаблона. Не утверждается, впрочем, что параллельно не могут выполняться и команды разных связок.
Шаблон указывает, какого типа команды находятся в слотах связки. В общем случае команды одного типа могут выполняться в более чем одном типе ФИУ (табл.1). Шаблоном задаются так называемые остановки, определяющие слот, после начала выполнения команд которого команды последующих слотов должны ждать завершения. Порядок слотов в связке (возрастание справа налево) отвечает и порядку байт - little endian. Однако данные в памяти могут располагаться и в режиме big endian. Режим устанавливается специальным разрядом в регистре маски пользователя.
Таблица 1. Типы команд и исполнительных устройств | ||
Тип команд | Тип исполнительного устройства | Описание команд |
A | I или M | Целочисленные, АЛУ |
I | I | Целочисленные неарифметические |
M | M | Обращение в память |
F | F | C плавающей запятой |
B | B | Переходы |
L+X | I | Расширенные |
При использовании ассемблера остановки отмечаются двумя подряд знаками "точка с запятой" - ";;". Места, в которых необходимо указывать остановку выглядят интуитивно понятными, по крайней мере, в приведенных в [1,2] примерах.
Последовательность команд от остановки до остановки (или выполняемого перехода) называется группой команд. Она начинается с заданного адреса команды (адрес связки плюс номер слота) и включает все последующие команды - с увеличением номера слота в связке, а затем и адресов связок, пока не встретится остановка.
Процессоры Itanium
64-разрядные процессоры семейства Itanium созданы на базе архитектуры EPIC. Архитектура EPIC позволяет проводить программно достаточно серьезные оптимизации, при этом задействуя и ILP на аппаратном уровне, за счет чего существенно растет эффективность работы системы в целом.
Семейство процессоров Itanium разрабатывалось совместно Intel и HP. Следует отметить обратную совместимость процессоров Itanium с процессорами Intel x86 и HP PA-RISC.
В процессорах Itanium 2 применяются 64-разрядные инструкции непосредственно на аппаратном уровне, чего не было на процессорах Itanium.
В целом, в Itanium 2 стало больше функциональных устройств, чем было у Itanium:
· Всего в Itanium 2 есть 6 АЛУ, в то время как Itanium может использовать лишь 4 за такт.
· В Itanium 2 есть 4 порта памяти, позволяющие по 2 целочисленных загрузки и сохранения за такт, в то время как в Itanium есть только 2 порта.
· Itanium 2 может выполнить одну SIMD инструкцию с плавающей точкой за такт, в то время как Itanium - две.
· При определенных условиях Itanium 2 может перенаправлять выполнение инструкций на непрофильные функциональные элементы.
· При обработке операций Itanium 2 учитывает многократно повторяющиеся операции.
Основы многопоточной (мультитредовой) архитектуры
Классификация ВС по соотношению потока команд и потока данных
К концу 60-х годов, в связи с различными архитектурными решениями в области разработки новых вычислительных систем, назрела необходимость в их классификации. Научное сообщество и сообщество разработчиков ЭВМ признало классификацию, предложенную в 1970 годах Г. Флинном.
Классификационным признаком этой группировки вычислительных систем является соотношение между потоком команд и потоком данных. По этому признаку выделяют 4 группы ВС:
- с одним потоком команд и одним потоком данных (ОКОД);
- с одним потоком команд и множеством данных (ОКМД);
- с множеством команд и одним потоком данных (МКОД);
- с множеством команд и множеством данных (МКМД);
К 1-ой группе относятся традиционные или классические ЭВМ и построенные на их основе вычислительные системы. Работа таких ЭВМ или вычислительных систем иллюстрируется рисунком 1а (на этом рисунке для обозначения потока данных применяется аббревиатура ПД, а потока команд – ПК, П-1, П-2,……П-N –процессоры или процессорные элементы).
Даже в ВС типа ОКОД возможно совместное решение нескольких задач. Такой режим работы системы называется мультипрограммным режимом. Программы и данные для совместно решаемых задач хранятся в оперативной памяти, где всем программам выделяются свои сегменты (разделение оборудования). Время работы процессора разделено на небольшие периоды (такты), в течение которых он выполняет команды для одной программы. Когда такт заканчивается, происходит прерывание, и передача управления операционной системе (программе-супервизору), которая просматривает очередь задач и определяет, есть ли в очереди задачи с более высоким или таким же приоритетом, что и у прерванной программы. Если есть, то в следующий такт процессор выполняет команды другой программы, если нет, то продолжает выполнение прерванной (разделение времени процессора). В таких ВС различаются 2 вида задач: фоновые и интерактивные. Первые из них не требуют вмешательства пользователя, вторые требуют ответов на запросы или ввода информации или, иначе говоря, выполняются в диалоговом режиме. Первые задачи имеют низкий приоритет, вторые – более высокий. Такое назначение приоритетов объясняется тем, что реакция пользователя на запросы значительно медленнее скорости работы процессора и ответы на запросы оказываются готовыми только через несколько тактов работы за которые процессор успевает либо решить фоновую задачу, либо обслужить других пользователей.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
