
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В. С. КИРЕЕВ, С. В. СИНИЦЫН
Московский инженерно-физический институт (государственный университет)
ДВУХЭТАПНЫЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ ДАННЫХ
Задачи группировки данных или задачи кластерного анализа очень часто встречаются в различных прикладных областях науки и производства, например, группировки респондентов в маркетинговом исследовании – сегментации. Поэтому особой актуальностью обладает разработка новых методов кластеризации, с минимальным числом параметров и наиболее универсальных в смысле границ применимости.
Рассмотрим задачу кластерного анализа следующего вида: разбиение достаточно большого числа наблюдений ( N ~ 102-103 ) на некоторое число групп (априори неизвестное), причём расстояние (в смысле выбранной меры близости) между наблюдениями внутри группы - невелико. Для решения задач такого рода обычно используются итеративные методы, и число групп или кластеров определяется в ходе работы метода по достижении некоторым критерием заранее заданного порога [1].
Для решения этой задачи кластеризации автором предлагается метод, сочетающий качества итеративного и агломеративного подходов, последний подробно описан в [2]. Агломеративный подход позволяет построить дерево объединения данных в кластеры и затем выбрать наиболее подходящее число кластеров, но для большого объёма данных вычислительная сложность этой процедуры значительно увеличивается, поэтому предлагается двухшаговая схема расчёта:
1. Построение начального кластерного решения.
2. Построение дерева агломерации и выбор подходящего числа кластеров.
На первом шаге исходная выборка разбивается на подвыборки, и для заранее заданного числа кластеров в них применяется метод К – средних. В ходе работы метода рассчитываются центры кластеров E и веса центров W - равные количеству элементов в кластерах:
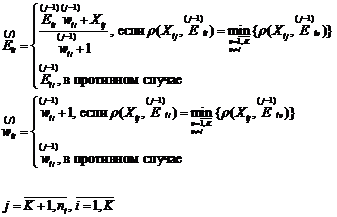 (1)
(1)
Эти центры кластеров считаются объектами на следующем шаге – в агломеративной процедуре, и при слиянии ближайших кластеров используются те же операции, что и в (1). При резком скачке расстояния объединения процедуру агломерации можно прекратить и в результате будут рассчитаны окончательные центры кластеров, и известна их мощность. Этих данных достаточно для расчёта значений критериев оптимальности решения – межкластерной и внутрикластерной дисперсий. Проведённые эксперименты (7 выборок по 200 наблюдений – результатов маркетинговых исследований) показывают, что в результате работы алгоритма получается оптимальное решение в смысле этих критериев.
Список литературы
1. , Мхитарян статистика. Основы эконометрики: Учебник для вузов: В 2 т.– Т. 1:. Теория вероятностей и прикладная статистика. – М.: ЮНИТИА-ДАНА, 2001. – 656 с.
2. , , Трошин статистические методы: Учебник. – М.: Финансы и статистика, 2003. – 352 с.
