
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Одна проблема здесь заключается в том, что следующий параметр может не оптимизироваться при новом значении параметра, оптимизированного первым. При этом не исключено, что его (этот следующий параметр) можно было оптимизировать раньше, а результаты его оптимизации могли превосходить полученные на деле. В результате обнаруживается возможность, выбрав не тот параметр на каком-то шаге, вступить не на тот холм.
Другая проблема возникает уже при выборе третьего параметра для оптимизации, так как совершенно не исключено, что наилучших результатов можно достигнуть, выбрав параметр, уже подвергшийся изменению, вместо десятков ещё не тронутых. Такие рассуждения приводят к выводу, что порядок, в котором должны выбираться параметры для их изменения, может оказаться практически любым. Исключение составляют только случаи, когда один параметр выбирается дважды подряд, ввиду того, что мы договорились искать экстремум по выбранному параметру. Но даже этот момент на деле может подвести. Возможно, дойдя до экстремума по выбранному параметру, мы прошли мимо очень крутого подъема по какому-то другому, и надо было остановиться на половине пути или пройти вдвое дальше. Таким образом, долгое прохождение по значениям параметра для поиска экстремума может быть не оправдано, по сравнению одним случайным, но удачным шагом.
Итак, окончательный вывод выглядит так: при выборе очередного параметра для изменения невозможно учитывать предыдущий порядок выбора параметров. То есть каждый раз, выбирая очередной параметр, мы стоим на распутье, где неоткуда получить никакой априорной информации, куда идти. Два выхода из такой ситуации это: выбрать параметр случайно или попробовать все и остановиться на том, который дает лучший результат. Второй выход сопряжен с огромным расходом времени. Кроме того, что параметров много, неизвестно, на сколько надо их менять. Таким образом, количество проб в таком случае приблизительно равно произведению числа параметров на число предполагаемых вариантов длины шага. Учитывая то, что каждая проба подразумевает состязание двух программ, которое в свою очередь обычно заключается в проведении нескольких партий, делаем вывод, что перебор всех вариантов - задача трудновыполнимая. Кроме того, даже при таком подходе отнюдь не исключается возможность пропустить верную дорогу, так как она может оказаться "за поворотом", то есть необходимо исследовать все возможности на два шага вперед, на три и т. д. Первый выход по крайней мере выполним. В таком методе обучение программы отдаётся на волю случая. Этот подход называют также эволюцией в популяции из двух особей. "Особями" здесь выступают конкурирующие программы, из которых "выживает" сильнейшая, даёт "потомство", которое "мутирует", то есть изменяет один из параметров своей оценочной функции.
Преимуществом этого метода является сравнительная простота. Процесс обучения можно запускать несколько раз из одной стартовой точки и если программы забрались на разные холмы, то можно выбрать забравшуюся на высочайший. Правда не решается проблема зависимости от стартовой оценочной функции. Если стартовую точку и некий холм разделены "оврагом", то программа никогда не заберется на него. Чтобы взобраться на холм, нужно по крайней мере, чтобы стартовая оценочная функция попала на его склон. И даже это не дает гарантии, что программа на него все-таки поднимется вообще и если поднимется, то за конечное время. На практике использование подобных методов нередко приводило, например, к бесконечному кружению по спирали по подножию холма.
1.8 Нетранзитивность игр
Одна из проблем метода вскарабкивания связана с транзитивностью отношения "более сильный - более слабый" игровых программ. Если программа A чаще всего выигрывает у программы B, а та в свою очередь чаще всего выигрывает у программы C, то последняя может чаще всего выигрывать у программы A. То есть транзитивность этого отношения стоит под вопросом. Программа, играющая на среднем уровне, может в силу стечения обстоятельств иметь, скажем, всего одну, но очень эффективную стратегию против гораздо более сильной программы и постоянно её обыгрывать. При этом эта стратегия не действует против других более сильных программ. Такие примеры существуют в жизни. Так, величайшего шахматиста Александра Алёхина, очень часто обыгрывал шахматист значительно менее высокого уровня Лайош Асталош. Известны и другие случаи подобного "везения", в том числе и в командных играх, что говорит о том, что это свойство нетранзитивности не является результатом каких-то психологических феноменов, а присуще самим играм, в особенности сложным позиционным.
Возможность такого свойства игр ставит под угрозу подход к обучению игровых программ, в котором все решается путем состязания только двух программ. Нередко может возникать ситуация когда предпочтение будет отдано программе более слабой, но знающей всего один изъян в стратегии другой. Учитывая то, что такой неверный выбор может быть сделан неоднократно в течение одного сеанса обучения, можно опасаться, что в результате программа вообще скатится вниз. Таким образом, невозможно быть уверенным даже в том, что описанный выше метод вскарабкивания на холм корректен. Он может привести к неконтролируемому понижению качества игры программы, что может выяснится слишком поздно. Возможна ситуация, в которой на некотором шаге метод вернется к исходной или уже встречавшейся оценочной функции. Все это требует поиска иного подхода к решению задачи обучения.
1.9 Обзор литературы и существующих программ.
В последние годы в мире был опубликован ряд статей и монографий, посвященных применению искусственного интеллекта (AI) в логических играх, в частности в нардах.
В работе [13] G. Tesauro “TD-Gammon, a self-teaching backgammon program” отмечается, что программа по игре в нарды (backgammon), реализованная с использованием нейронной сети, добилась высоких результатов при игре с лучшими игроками-людьми, используя параметры, полученные при игре сама с собой. Нейронная сеть использовалась для оценки качества позиций. Программа оценивала все доступные за один ход позиции и выбирала тот ход, который вел к наилучшей позиции. Параметры нейронной сети модифицировались с помощью алгоритма TD.
В работе [14] J.Pollack & A.Blair “Co-Evolution in the successful learning of backgammon strategy” рассматривают эволюционный подход к настройке весов нейронной сети, оценивающей позиции в нардах. В работе предлагается использовать упрощенный вариант генетических алгоритмов. Констатируется достижение достаточно высоких результатов несмотря на некоторые огрехи в методике.
В работе [15] M. Buro “Efficient approximation of backgammon race equities” предлагается использовать статистические методы и динамическое программирование для оценки вероятности выигрыша позиции в нардах. В работе сообщается об обоснованности применения данных методов.
Также в последнее время был выпущен ряд программ для PC и для мобильных устройств.
В частности была выпущена программа GNUbackgammon для PC, распространяемая бесплатно и использующая для оценки позиций нейронные сети. Предлагается использовать несколько обученных сетей для разных фаз игры (начальная фаза, активный контакт фишек, фаза вывода фишек с доски). Нужно отметить достаточно высокий класс игры.
Также был выпущен ряд игр для телефонов, поддерживающих J2ME фирмами gameloft, ZingMagic. Их отличает хорошая графика и приемлемый уровень игры.
1.10 Игровые деревья.
Для любой игры можно определить игровое дерево, узлы которого суть игровые позиции, а дочерние узлы – позиции, достижимые из исходной за один ход.
Также полагается, что дерево конечно, т. е. мы имеем дело с игрой которая не длится вечно или имеет бесконечно много ходов из одной позиции.
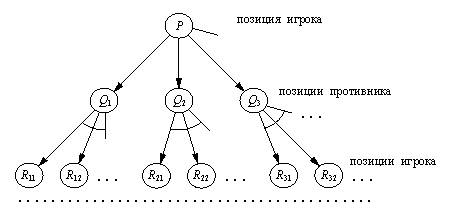
рис. 1 Фрагмент игрового дерева
Многие сложные реальные задачи можно смоделировать с помощью деревьев решений (decision trees). Каждый узел в дереве представляет собой один шаг решения задачи. Ветвь в дереве соответствует решению, которое ведет к более полному решению. Листы представляют собой окончательное решение. Цель состоит в том, чтобы найти «наилучший» путь от корня до листа при выполнении некоторых условий. Естественно, что условия и «наилучший» путь зависят от сложности конкретной задачи.
На примере крестиков-ноликов показаны способы поиска в деревьях игры наилучшего возможного хода. Последующие разделы описывают более общие способы исследования деревьев решений. Для самых маленьких деревьев можно использовать метод полного перебора(exhaustive searching) всех возможных решений. Для работы с большими деревьями более подходит метод ветвей и границ(brunch-and-bound technique), позволяющий отыскивать лучшее возможное решение без поиска по всему дереву. Для огромных деревьев лучше использовать эвристический метод (heuristic). При этом найденное решение может и не быть наилучшим из возможных, но должно быть достаточно близким к нему.
1.11 Дерево игры в нарды
Возможность игрока передвигать шашки определяется броском двух кубиков. Существует 36 равновероятных комбинаций выпадения кубиков, из них 21 принципиально разная. В сети интернет можно найти большое количество материалов по нескольким различным подходам к программированию игрока в нарды. Некоторая систематизация этих материалов произведена авторами.
Игра описывается посредством дерева игры. Далее также по аналогии определяются оценки позиций, применяется а, b - эвристика. Кроме того, вводится такое новое понятие, как функция риска.
Так как нарды в большой степени отличаются от игр, подобных шахматам, то некоторые подходы не применимы в отношении нард. Основным отличием нард от шахмат является недетерминированность. Её привносит в нарды стохастический фактор, обусловленный бросанием кубиков. Этот фактор значительно усложняет исследование нард, но в то же время делает его более актуальным. Ведь подавляющее большинство явлений и процессов в действительности так или иначе связано с явлениями случайными, описываемыми вероятностно. В результате, дерево игры в нарды - дерево недетерминированной игры. В связи с этим возникает потребность дополнительном анализе дерева игры в нарды.
Учитывая то, что у нард очень большой коэффициент ветвления дерева игровых позиций (достигает 200-300 доступных ходов из одной позиции) и наличие случайности (броски костей) перебор в осложняется, вследствие ограниченности вычислительных ресурсов. Для примера, в шахматах коэффициент ветвления составляет порядка 40 ходов, а для шашек 8-15. Так например при глубине поиска два существует 1,296 ходов, глубина 3 – 46,656 ходов. Поэтому рассматриваются наиболее вероятные ходы, например выпадение дубля несколько раз подряд маловероятно. При таком подходе число учитываемых ходов сокращается до 900 и 27,000 соответственно. Но даже такой подход не позволяет осуществлять перебор ходов на большую глубину, т. к. их количество слишком велико, и время работы существенно увеличивается. В следствие этого расчет ходов более чем на глубину 2 не целесообразен. На рисунке 3. показана зависимость количества вариантов ходов от глубины.
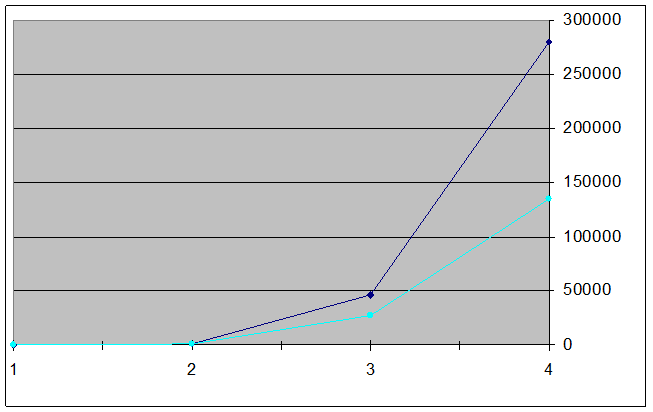
Рисунок 3. Зависимость количества вариантов ходов от глубины.
Поэтому необходима качественная оценочная функция, дающая правдоподобную оценку вероятности победы игрока в данной позиции.
Что представляет из себя просмотр дерева игры и поиск в нем ходов? При поиске ходов мы хотим создать в перспективе наиболее выгодную ситуацию, желательно через как можно большее количество ходов, нас интересует больше ситуация в будущем, а не в настоящем, поэтому и прибегают к дереву игры. Причем, скорее всего выгодной ситуации в будущем будут предшествовать не самые выгодные промежуточные ходы. Необходимо также учитывать наличие противника, который предположительно будет ходить оптимально со своей точки зрения и стараться ухудшить ситуацию для соперника.
Итак, строится дерево заданной глубины, в корне которого текущая ситуация, а листья которого (на самой большой глубине) соответствуют терминальным ситуациям, после которых улучшение невозможно. Фактически в большинстве случаев оно возможно, но эта возможность скрыта от нас ограниченностью дерева поиска.
Среди терминальных ситуаций требуется выделить лучшую с точки зрения того игрока, для которого мы ищем ход и достижимую при условии наиболее оптимального сопротивления второго игрока.
Качество хода определяется оценочной функцией, которая применяется к конкретной позиции на доске. Оценочная функция может вычисляться с точки зрения одного или другого игрока, например, количество белых или черных фишек.
2 Построение эвристических оценочных функций.
2.1 Выделение параметров.
Реализованная программа игры за компьютер состоит из двух частей. Первая часть генерирует все возможные ходы (при текущем броске костей) доступные из текущей позиции. Вторая часть – оценочная функция, с помощью которой выбирается наилучший ход. Учитывая то, что у нард очень большой коэффициент ветвления дерева игровых позиций (достигает 200-300 доступных ходов из одной позиции) и наличие случайности (броски костей) перебор в глубину не представляется целесообразным, вследствие ограниченности вычислительных ресурсов. Для примера, в шахматах коэффициент ветвления составляет порядка 40 ходов, а для шашек 8-15. Таким образом, применение «грубой силы» (“brute force”) для нард неэффективно.
В качестве оценочной функции используются линейные модели (линейная комбинация некоторых параметров) и нейронные сети (трехслойная нейронная сеть).
В простейшей модели в качестве параметров можно взять просто количество фишек на каждом поле, получив в сумме 26 параметров. Реально же используют некоторые вычисляемые параметры, представляющие определенные стратегические аспекты игры.
Одним из основных параметров является подсчет пипсов (pips) – это число, которое нужно выбросить на игральных костях, чтобы вывести все свои фишки. По этому параметру определяют лидерство и близость победы.
Число одинарных фишек (blots) также является важным параметром, который стремятся сокращать все игроки, так как только одинарные фишки можно побить в нардах, тем самым откинув противника в гонке за вывод фишек из доски.
Число полей с двумя и более фишками (hold) является противоположностью предыдущему параметру, его стремятся максимизировать. Чем больше таких полей, тем устойчивее позиция и тем сложнее через нее пройти.
Связанным параметром является построение блокад – несколько смежных полей, занятых двойными или более фишками. С этим параметром можно связать изменение стратегии – нужно проводить свои фишки вперед, если их запирают.
Также считают число прямых возможностей взятия (direct shot) – это число одинарных фишек на расстоянии 6 или меньше полей. Есть схожий с этим параметр indirect shots – число одинарных фишек на расстоянии меньшем 12. Схожим параметром является вероятность взятия одинарной фишки, которая в большинстве случаев рассчитывается по предварительно посчитанной таблице.
Равномерность распределения фишек по полям. Например, гораздо выгоднее иметь три фишки на одном поле и еще три на другом, чем две и четыре на тех же полях. В случае выпадения определенных костей может потребоваться сдвинуть фишку с первого поля и тем самым сделать как минимум одну одинарную фишку.
Анализируя сыгранные партии можно заметить, что занятие определенных позиций (golden point) на доске способствует победе. Такими позициями является 4-я и 5-я клетки и соответственно 20-я и 21-я симметричные клетки. Таким образом, в простейшем случае можно ввести факт занятия этих клеток в оценочную функцию. В более общем случае, вводят весовые коэффициенты для всех полей доски.
Также часто используется параметр коммуникации – нужно стремиться располагать свои фишки на расстоянии не более 6 пипсов друг от друга. Тем самым препятствовать разделению своих фишек.
При выводе своих фишек, нужно стремиться оставлять четное число фишек на каждом поле, чтобы минимизировать шансы оставления одиночной фишки после очередного хода.
Очень часто вводятся понятия контакта фишек – наличие хотя одной вражеской фишки в направлении движения. Наличие факта контакта влияет на используемую стратегию и может предполагать разные оценочные функции.
В целом можно отметить, что с ростом числа параметров в модели росло и время обучения, но также росло и качество оценки позиции.
2.2 Определение более сильного игрока из двух.
В силу того, что и в игре присутствует элемент везения возможна ситуация, когда слабый соперник может выиграть у более сильного, что ставит вопрос об определении более сильного игрока из двух. В случае, когда один соперник заведомо сильнее другого эффект везения практически не проявляется и выбрать сильнейшего можно сыграв незначительное число партий. К тому же данная ситуация случается не так часто. Когда же силы игроков примерно равны (такое часто случается при подборе весов оценочной функции) выбирать сложнее. Соответственно требуется оценить число партий, которые необходимо сыграть, чтобы достоверно определить победителя. Можно доказать, что число побед одного игрока над другим распределено по нормальному закону. В этом случае для получения доверительного интервала для оценки математического ожидания вероятности победы первого игрока можно воспользоваться следующим выражением: 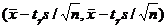 , где
, где ![]() -выборочное среднее,
-выборочное среднее, ![]() - “исправленное” среднее квадратическое отклонение,
- “исправленное” среднее квадратическое отклонение, ![]() - коэффициент Стьюдента с надежностью
- коэффициент Стьюдента с надежностью ![]() ,
, ![]() - объем выборки. Так как силы игроков примерно равны, можно считать, что вероятности выпадения 1 (победа белых) или 0 (победа черных) равны. Тогда задавшись
- объем выборки. Так как силы игроков примерно равны, можно считать, что вероятности выпадения 1 (победа белых) или 0 (победа черных) равны. Тогда задавшись ![]() , получим доверительный интервал для
, получим доверительный интервал для 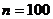 :
: 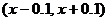 . А для
. А для ![]() :
: ![]() . Основываясь на полученных данных, сравнивать силу двух игроков, примерно равных по силе, корректно только при числе сыгранных партий близком к тысяче и более.
. Основываясь на полученных данных, сравнивать силу двух игроков, примерно равных по силе, корректно только при числе сыгранных партий близком к тысяче и более.
2.3 Настройка весовых коэффициентов.
Исходя из пункта 1.6 оценочная функция будет иметь вид:
f = - pip - one + group(x2 even if) + block + pos;
где pip – расстояние до конца доски,
one – количество одиночных фишек,
group – вхождение в группу фишек (умножается на два, если количество фишек в группе чётное),
block – если блокируется фишки противника,
pos – если занимается 4-я, 5-я, 20-я или 21-я клетка.
2.4 Линейная модель из 3-х параметров. Вид поверхности.
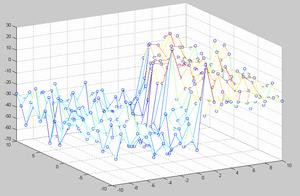
При нынешнем уровне развития вычислительной техники, при большом числе параметров модели (например, если в качестве параметров использовать число фишек на каждом поле) перебрать все параметры для определения подходящих величин не представляется возможным. Но получить представление о виде поверхности количества побед модели над эталонным игроком, на примере коротких нард, можно, сведя количество параметров до трех: pips (сумма чисел, которые нужно выкинуть на кубиках, чтобы выиграть партию), blots (число одиночных фишек), hold (число удерживаемых позиций, т. е. с числом фишек больше двух). В результате были построены зависимости количества побед над эталонным игроком (выбирающим ходы случайным образом) от blots и hold при фиксированных значениях pips, выбранных равными +1, -1, +5, -5. Учитывается разница этих параметров для игроков, играющих белыми и черными фишками. Перебор этих параметров осуществлялся в диапазоне от –10 до 10.
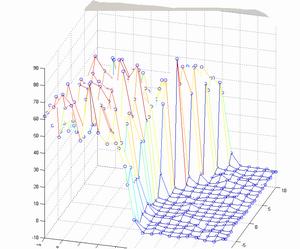
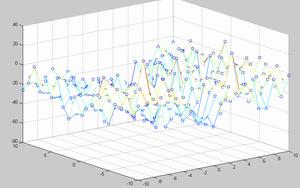
pips = 1 pips = -1
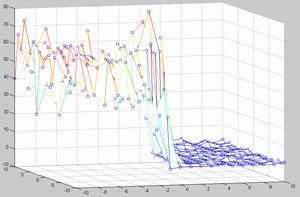
pips = 5 pips = -5
Рис. 3. Поверхности количества побед линейной модели над эталонным игроком от величины параметров.
Из графиков видно, что все три параметра в значительной мере влияют на качество оценки позиций. Так параметр pips можно проассоциировать с близостью победы, соответственно, следует максимизировать вес этого параметра. Количество удерживаемых клеток (две и более фишек на одном поле) также значительно влияет на количество побед так как его фишки сложнее побить и соответственно, игрок, обращающий на это внимание выигрывает чаще. Количество blots игрок должен стремиться минимизировать, так как это “откатывает” его назад. Наилучшие результаты дало сочетание весов pips = 1, blots = -8, hold = -8.
В процессе проведения расчетов было отмечено, что чем ближе игроки по силе (близость к 0 разницы количества побед игроков) тем дольше идет партия. Также в ряде статей (например в [11]) отмечается увеличение длины партий с ростом класса игрока. Данный эффект также был отмечен и в игре в нарды.
2.5 Таблицы вероятностей.
Для усиления игры программы были опробованы таблицы вероятностей. Для игры нарды можно построить два типа таких таблиц: двусторонние и односторонние. Двусторонние таблицы содержат предварительно просчитанные вероятности победы. Например для шести и менее фишек, находящихся в доме есть 924 возможных позиции, всего 924*924 = 853,776 возможных позиций для каждой из которых нужно хранить вероятность победы. Наибольшая проблема таких таблиц – экспоненциальный рост размера с увеличением числа фишек и полей. Так, для упомянутой таблицы объем занимаемой памяти можно оценить шестью мегабайтами, что выходит за рамки ограничений мобильных устройств.
Значительная экономия может быть достигнута при использовании односторонних таблиц в которых хранятся вероятности вывода всех фишек в данной позиции за n ходов - ![]() . Предположим, что для игроков A и B в текущей позиции нам известны распределения
. Предположим, что для игроков A и B в текущей позиции нам известны распределения ![]() и
и ![]() , тогда вероятность того что игрок A выведет все свои фишки первым будет рассчитываться по формуле:
, тогда вероятность того что игрок A выведет все свои фишки первым будет рассчитываться по формуле: ![]() . Число позиций состоящих из 15 фишек на 6 полях равно 54,264 и такая таблица будет занимать в памяти примерно 1.4 мегабайта, что гораздо ближе к ограничениям для существующих мобильных устройств.
. Число позиций состоящих из 15 фишек на 6 полях равно 54,264 и такая таблица будет занимать в памяти примерно 1.4 мегабайта, что гораздо ближе к ограничениям для существующих мобильных устройств.
Как оказалось, прирост качества игры от использования такой таблицы оказался незначительным, что может быть объяснено ее небольшим размером и тем, что только порядка 1-2% позиций в игре оценивается по ней.
Но можно применить похожие принципы для генерации выборки для обучения нейронной сети. Так, чтобы получить оценку вероятности выигрыша из данной позиции можно сформировать некоторый набор позиций. И для каждой из этих позиций провести по N партий, между двумя равными сильными игроками. Причем, под числом побед белых над черными можно понимать оценку данной позиции. На сгенерированной таким образом выборке можно обучить нейронную сеть и получить оценочную функцию высокого класса. Можно повторять этот процесс итеративно для улучшения качества оценки.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
