


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
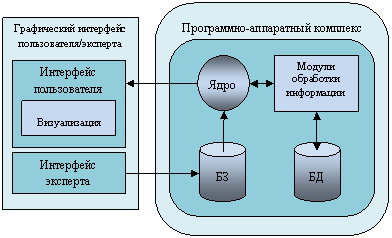
Рисунок 1 - Общая архитектура программно-инструментального комплекса
Ядро системы служит для поддержки процесса решения прикладной задачи. Часть ядра, называемая «диспетчер управляющих команд» запускает подзадачи на имеющихся вычислительных узлах и осуществляет равномерную загрузку вычислительной системы. При загрузке вычислительного ядра выполняется подключение описанных пользователем параметризованных модулей обработки и их связывание инициализированными каналами передачи данных. Сами модули не имеют привязки к вычислительному ядру и реализованы как динамически подключаемые библиотеки.
База знаний представляет собой набор описаний типов данных, модулей системы, схем решения задач, настроек модулей обработки, конфигурации многопроцессорной системы и др. База данных хранит в себе множество обрабатываемых в ходе решения прикладной задачи данных, так же, как и результаты обработки.
Процесс моделирования заключается в составлении схемы решения поставленной задачи средствами графического интерфейса. Он представляет собой редактор, позволяющий визуализировать процесс конструирования и редактирования схем решения задач на этапе проектирования, используя концепцию визуального блочного программирования.
Программное вычислительное ядро системы (рисунок 2), являющееся основой разрабатываемого комплекса, состоит из нескольких компонент, логически разделенных на 2 уровня: низкоуровневые и высокоуровневые. Компоненты, отвечающие за низкоуровневую реализацию, содержат в себе механизм менеджмента памяти и механизм передачи данных, что позволяет с легкостью адаптировать комплекс под определенную аппаратную или программную платформу. С точки же зрения разработчиков модулей обработки, ядро ПС монолитно и предоставляет лишь два необходимых и достаточных интерфейса: интерфейс управления ресурсами и интерфейс управления внешними модулями, что позволяет упростить задачу разработки прикладных решений.
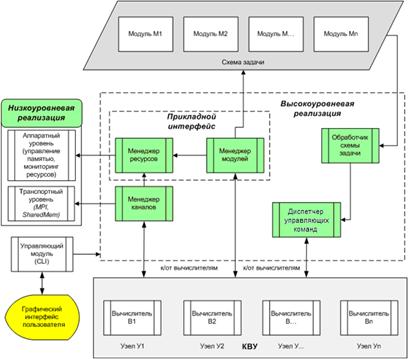
Рисунок 2 - Структурная модель ядра ПС
Приведенная схема демонстрирует основные компоненты ядра системы, наиболее важными из которых являются:
Вычислитель - модуль ядра, занимающийся непосредственно выполнением атомарных команд системы диспетчеризации. Такими командами являются инициализация/останов вычислителя, загрузка и инициализация модуля, запуск загруженного модуля и др. Вычислители являются абстракцией вычислительной единицы аппаратуры (узел кластера, ядро процессора), что упрощает как логическую структуру ПС, так и ее реализацию.
Диспетчер управляющих команд – модуль ядра, обеспечивающий сбалансированную загрузку имеющегося вычислительного устройства в рамках выполняемой задачи. Принимая на вход описание задачи и конфигурацию вычислительного устройства, диспетчер рассылает команды на инициализацию и запуск модулей, тем самым равномерно распределяя подзадачи между всеми вычислителями. В ходе своей работы диспетчер оперирует состояниями, состоящими из множества ожидающих выполнения команд запуска модулей, используя информацию о ресурсах доступных вычислителям. Переходом в новое состояние диспетчера является получение определенных событий от вычислителей, например, событие о завершении обработки пакета данных модулем, запущенным ранее.
Другие блоки показывают модули ядра, выполняющие сервисные функции и предоставляющие программные интерфейсы, обеспечивающие удобный инструментарий для прикладного программиста, занимающегося разработкой внешних модулей обработки.
Таким образом, в соответствии с общей концепцией ПС, программное ядро обеспечивает связь модулей, реализующих конкретные алгоритмы. Главной задачей ядра является доставка данных от модуля к модулю по инициализированным в схеме задачи каналам передачи и обеспечение контроля типов передаваемых данных. Помимо этого, ядро осуществляет равномерную загрузку имеющихся у него в распоряжении вычислительных ресурсов.
Из особенностей вычислительного ядра можно выделить следующее:
· Подключаемые модули реализуются в виде подгружаемых библиотек и могут содержать как последовательную, так и параллельную реализацию алгоритма.
· Обеспечивается одновременно как параллелизм работы модулей, так и конвейерный режим обработки данных.
Приведена информация о предлагаемом формате данных, использованном для описания БЗ. В качестве основы выбран формат xml-описаний. Основными для системы являются декларативные описания решаемой прикладной задачи и описание модулей обработки. Общий формат описания задачи имеет следующий вид:
<?xml version="1.0" standalone="yes"?> <task xmlns="http://tempuri. org/KernelTask. xsd"> <modules> <module internalname="" name=""> <var name = ""></var> </module> </modules> <channels> <channel> <out></out> <in></in> </channel> </channels> </task> |
Структурно, описание задачи состоит из двух основных секций:
1. Секции описания модулей (определена тегом <modules>), которые необходимо загрузить вычислительному ядру для решения прикладной задачи, с указанием параметров их инициализации.
2. Секция описания каналов передачи данных (определена тегом <channels>), указывающая, каким образом необходимо связать между собой модули.
Использование подобного подхода позволяет описывать задачу в виде ориентированного графа, представляющего собой фактически диаграмму потоков данных, где в качестве узлов выступают модули обработки, реализующие конкретные алгоритмы. Подход позволяет использовать принципы визуально-блочного программирования при составлении схем решения прикладных задач.
Описаны принципы расширения функциональных возможностей ПС, путем создания модулей обработки для решения прикладных задач. Для создания новых модулей система предоставляет прикладному программисту набор базовых программных интерфейсов на языке высокого уровня С++, поддержку которых необходимо реализовать. При этом разработчик модуля может реализовать алгоритм в виде функции, не имеющей сегментов параллельного кода и использовать сервисы предоставляемые ядром программной системы для реализации параллелизма по данным. Для включения в систему все созданные модули должны быть снабжены описанием, соответствующем следующему формату:
<?xml version="1.0" encoding="utf-8"?> <module parallel="" nodecountmin="" nodecountmax=""> <designer class=" "> <moduledesc name="" desc="" /> <vardesc name=" " desc="" /> <channeldesc name=" " desc="" /> </designer> <init> <var name="" type=""></var> </init> <channels> <channel type="" name="" datatype="" target=""/> </channels> </module> |
Описание модуля позволяет указать желаемые ограничения и выбрать наиболее подходящую стратегию передачи данных, кроме того, указанная в описания информация используется для валидации схем.
Приведены модели функционирования комплекса программных инструментальных средств. В качестве основы для моделирования выбран математический аппарат модифицированных сетей Петри (Е-сетей) и конечных автоматов. Данные модели взаимно дополняют друг друга, позволяя получить наиболее полное представление (описание) процессов функционирования системы и создают основу для научно-обоснованного проектирования подобных систем.
На рисунке 3 показана простейшая сеть Петри, реализующая принцип управления решением задачи с использованием разработанных инструментальных средств.
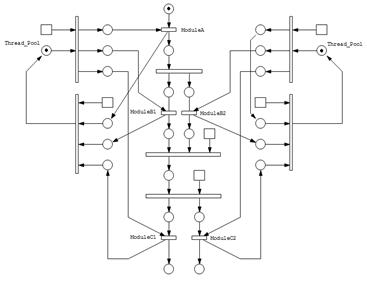
Рисунок 3 – Пример сети Петри, демонстрирующей прикладную задачу
На данной схеме приведены блоки, соответствующие пулам потоков на вычислительных узлах МВС и представление простой схемы из трех модулей, в которой:
· ModuleA - непараллельная реализация поставщика ресурсов;
· ModuleB - модуль обработчик данных, имеющий параллельную реализацию;
· ModuleС - непараллельная реализация потребителя ресурсов.
Данная модель тесно связана с моделью системы диспетчеризации, построенной с использованием конечного автомата (рисунок 4). В частности, команды системы диспетчеризации устанавливают значения управляющих позиций Е-сети, определяя последовательность срабатывания переходов (запуск программных модулей) и трассу передвижения меток (данных подлежащих обработке).
Указанный граф S является конечным автоматом, описывающим основные состояния работы системы диспетчеризации, и может быть формально определен как S = (Q, X, δ, q0, F) где:
Q = {Start, Init, Update, Select, Apply, Wait, End} – конечное множество состояний автомата, описывающих фазы функционирования диспетчера задач;
X = {λ, CMD_SENDED, EVENT_RECEIVED, CMD_SELECTED, NO_APPLICABLE_CMDS, CMDS_NOT_AVAILABLE} – входной алфавит КА, указанные входные символы подаются на вход КА после вычисления предикатов, оценивающих внутреннее состояние системы диспетчеризации (описываемое таблицами занятости вычислителей, списками доступных и применяемых в настоящий момент команд)
· λ – лямбда-переход, оценка внутреннего состояния системы диспетчеризации не производится;
· CMD_SENDED – выбранная (применимая) команда передана вычислителю;
· EVENT_RECEIVED – получено подтверждение от вычислителя о выполнении команды или создании ресурса подлежащего обработке;
· CMD_SELECTED – выбрана применимая команда;
· NO_APPLICABLE_CMDS – нет применимых команд;
· CMDS_NOT_AVAILABLE – список исполняемых в настоящий момент команд пуст.
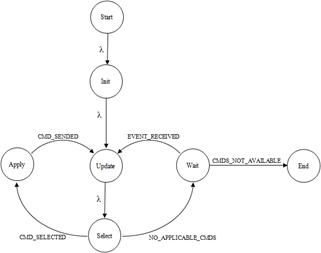
Рисунок 4 – Граф состояний системы диспетчеризации
δ : QxX → Q – функция перехода КА;
q0 = Start – начальное состояние автомата;
F = {End} – множество терминальных состояний КА.
Третья глава посвящена описанию разработанных механизмов и алгоритмов, предназначенных для реализации предлагаемого комплекса программно-инструментальных средств.
Приведена информация о разработанных алгоритмах реализующих основную функциональность программного комплекса. Подробно раскрыто понятие вычислителя, системы используемых команд и принципа организации системы диспетчеризации.
Процесс диспетчеризации построен на системе управляющих команд, при этом, в связи с имеющимися ограничениями определенными постановкой задачи, используется алгоритм, оперирующий лишь текущим состоянием системы.
Алгоритм 1. Общий алгоритм функционирования системы
· Чтение xml-файла с описанием решения задачи, чтение xml-описания каждого из требуемых для решения задачи модулей.
· Передача вычислительному ядру списка модулей, которые необходимо загрузить. Равномерная загрузка модулей на вычислительных узлах МВС с учетом наложенных пользователем ограничений.
· Инициализация каналов передачи данных. Первоначально все каналы находятся в отключенном состоянии. Установка связей переводит их в состояние ожидания.
· Начальная инициализация всех модулей на заданных узлах МВС. Ядру передаются значения переменных, которые необходимо установить для каждого из загруженных модулей.
· Запуск системы, передача данных через каналы, ожидание завершения работы всех модулей.
· Завершение работы системы.
Общая схема взаимодействия «Диспетчер управляющих команд» ↔Вычислители↔Модули, в ходе решения прикладной задачи, представлена на рисунке 5. На данной схеме введены следующие обозначения: S – диспетчер управляющих команд, Wj – вычислитель, ассоциированный с узлом j, mij – модуль i, загруженный на узле j.
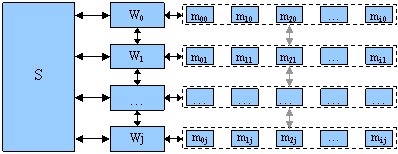
Рисунок 5 - Схема взаимодействия компонент системы диспетчеризации
Данная схема определяет связи следующих типов:
1) «Диспетчер управляющих команд↔Вычислители» - передача управляющих команд от диспетчера и подтверждений от вычислителей.
2) «Вычислитель↔Модули» и «Вычислитель↔Вычислитель» - данные связи позволяют обеспечить параллельно-конвейерную обработку данных средствами ядра системы в случае использования непараллельных модулей, реализуя межмодульное взаимодействие.
3) «Модуль↔Модуль» - связи, описывающие взаимодействие копий параллельных модулей находящихся на разных узлах.
Основной задачей системы диспетчеризации является управление процессом передачи данных между модулями и инициации их запуска, путем передачи вычислителям управляющих команд.
Алгоритм 2. Общий алгоритм работы системы диспетчеризации
1) Построить начальное состояние системы (включающее множество команд инициализации вычислителей, загрузки модулей необходимых для решения прикладной задачи и команд запуска модулей «поставщиков» ресурсов)
2) Построить список применимых команд
3) Если применимых команд нет, переход к пункту 7
4) Выбрать применимую команду, обладающую наивысшим приоритетом (приоритет команды прямо зависит от количества аппаратных ресурсов требуемых для ее исполнения, приоритетный выбор наиболее ресурсоемких вычислений в каждом состоянии максимизирует нагрузку на узлы МВС)
5) Передать выбранную приоритетную команду вычислителю
6) Обновление внутреннего состояния системы, далее переход к п. 2
7) Если есть команды, переданные вычислителям, но еще не завершенные в текущем состоянии:
7.1) Ждать подтверждения от вычислителей
7.2) Обновление внутреннего состояния системы, далее переход к п. 2
8) Завершение работы.
Количество потоков в пулах вычислителей на каждом из доступных узлов должно быть определено пользователем и напрямую зависит от возможностей имеющегося аппаратного обеспечения. Все сообщения генерируемые ядром системы, как управляющие команды от диспетчера к вычислителям, так и сообщения от вычислителей о завершении обработки того или иного пакета данных или создании нового ресурса подлежащего обработке, переводят систему в новое состояние.
В ходе работы системы могут возникать ситуации, в которых запуск модуля невозможен в текущий момент времени. Управляющие команды при этом буферизуются системой диспетчеризации (их выполнение откладывается) до момента, когда необходимые ресурсы будут доступны.
Предложенный подход к диспетчеризации работы, основанный на «жадном» алгоритме локально оптимального выбора применимых команд, несмотря на его простоту, является достаточно эффективным решением позволяющим задать ограничения на количество используемых аппаратных ресурсов МВС.
Говоря об аналогичных системах, следует указать, что используемые в них принципы диспетчеризации, по мнению автора, уступают предложенному. Система CODE не имеет диспетчера нагрузки, поскольку является, по своей сути, системой кодогенерации. Технология Microsoft Workflow Foundation использует принцип очереди заданий без приоритетов, последовательно запуская компоненты входящие в схему решения задачи в рамках одного потока исполнения, однако, позволяет задать пул потоков для исполнения либо реализовать многопоточный сервис, что может обеспечить параллелизм, но требует от прикладного программиста большей квалификации. Система Kepler, в конвейерно-параллельном режиме работы, исполняет каждый модуль входящий в схему решения задачи в независимом потоке, что при увеличении сложности решаемых прикладных задач (включающих большое количество модулей) приведет к излишним затратам, вызванным конкуренцией потоков.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
