

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Родрігес Заліпиніс Рамон Антоніо
Донецький національний технічний університет
НОВЫЙ ПАРАЛЛЕЛЬНЫЙ АЛГОРИТМ РАЗБИЕНИЯ ГРАФОВ
Научное направление: информатика и вычислительная техника, компьютерные науки
Ключевые слова: КОМПЬЮТЕРНЫЙ КЛАСТЕР, MPI, МНОГОУРОВНЕВАЯ ПАРАДИГМА, ГРАФ, РАЗБИЕНИЕ
Вступление. Разработана новая параллельная распределённая программная система разбиения графов. Она использует MPI и работает на компьютерном кластере. В системе реализован новый параллельный метод укрупнения графа в многоуровневой парадигме разбиения графов.
За 32 секунды на 8 процессорах удалось повысить качество решений, находимых METIS – одной из лучших и самых быстрых систем для разбиения графов – вплоть до 42% для некоторых графов.
Формулировка исследуемой проблемы. Проблема разбиения графов заключается в разбиении множества вершин графа на заданное количество подмножеств так, чтобы размеры этих подмножеств отличались не более чем на заданную величину и сумма весов рёбер, соединяющих эти подмножества – стоимость разбиения, была минимальна.
Разбиваются неориентированные графы с весами на вершинах и рёбрах. Размером подмножества вершин является сумма весов вершин входящих в это подмножество.
Значение проблемы и современное состояние её решения. Проблема разбиения графов практически важна. Она возникает при переупорядочивании разреженных матриц, в робототехнике, базах данных, обработке изображений, компьютерных сетях, параллельных вычислениях, проектировании СБИС, операционных системах и других областях [1–8].
Большая практическая потребность, NP-полнота [9] и огромные размеры графов привели к тому, что разбиение графов стало сложной проблемой. На сегодняшний день приложениям, применяемым на практике, приходится быстро находить разбиения графов из миллионов вершин [10], что явно нельзя осуществить на однопроцессорном компьютере.
Для эффективного разбиения больших графов разработана многоуровневая парадигма [10–14]. С ёё помощью можно быстро получать качественные решения.
Вначале исходный граф укрупняется стягиванием пар смежных вершин, вероятность которых быть помещёнными в разные подмножества разбиения мала, чтобы получить меньший граф – аппроксимацию исходного. Для выбора пар вершин используются специальные эвристики. Одной из лучших является HEM*, реализованная в системе разбиения графов METIS [15].
HEM* работает следующим образом [11]. Вершины посещаются в случайном порядке. Пусть v будет посещённой вершиной, Q – множество смежных с v вершин, у которых ещё нет пары, w – максимальный вес рёбер {v, q}, где q ![]() Q, H – множество вершин h из Q таких, что вес ребра {v, h} равен w. Для каждой вершины h
Q, H – множество вершин h из Q таких, что вес ребра {v, h} равен w. Для каждой вершины h ![]() H вычисляется s(v, h) – сумма весов рёбер, соединяющих h с вершинами, смежными с v. Пара для вершины v – вершина u, у которой s(v, u) максимально, рис. 1.
H вычисляется s(v, h) – сумма весов рёбер, соединяющих h с вершинами, смежными с v. Пара для вершины v – вершина u, у которой s(v, u) максимально, рис. 1.
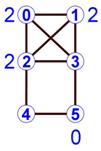
Рисунок 1 – Пример значений s(3, u) для НЕМ*
Укрупнение выполняется рекурсивно, пока не получится небольшой граф из нескольких десятков вершин. Его можно быстро разбить на требуемое число подмножеств эвристиками, которые не в состоянии работать на больших графах [16, 17]. Чтобы получить разбиение исходного графа, вершинам ![]() и
и ![]() , стянутым в вершину
, стянутым в вершину ![]() , назначается то же подмножество разбиения, что и для вершины
, назначается то же подмножество разбиения, что и для вершины ![]() .
.
Метод решения проблемы конкурсантом. Самостоятельно разработана распределённая система разбиения графов, работающая параллельно на компьютерном кластере. Она реализует новую самостоятельно разработанную параллельную схему укрупнения графов.
Порядок посещения вершин в схеме НЕМ* существенно влияет на качество стягивания. Если мы посетим вершину 5 до вершины 3, то мы можем с равной вероятностью выбрать для 5 в качестве пары вершину 3 либо 4, рис.1.
HEM* также не учитывает «мнение» выбираемой вершины: вершина 5 может выбрать вершину 3, однако вершина 3 могла бы выбрать вершину 5 только в том случае, когда все её соседние вершины уже заняты. В противном случае, вершина 5, выбирая вершину 3, не заботится о том, «согласна» ли вершина 3, чтобы её выбрала вершина 5, рис.1.
Описанные выше аспекты работы HEM*, приводят к тому, что некоторые вершины, которые должны быть помещены в разные подмножества разбиения, стягиваются в одну. Это приводит к увеличению стоимости разбиения.
Конкурсантом разработана новая параллельная схема укрупнения графа – HEM*+, которая с большей вероятностью, чем HEM*, стягивает вершины, вероятность которых быть помещёнными в разные подмножества разбиения мала.
Проведенные эксперименты на компьютерном кластере для графов из всемирного архива графов [18], на которых принято тестировать алгоритмы разбиения графов, показали, что можно улучшить разбиения, находимые METIS [21], вплоть до 42% для некоторых графов.
Основная часть (изложение самостоятельной работы).
Алгоритм HEM*+ работает следующим образом.
Порядок посещения вершин, как для HEM* не фиксирован, однако HEM*+ учитывает «мнение» выбираемой вершины. К тому же, HEM*+ несколько иначе вычисляет значение для соседних вершин, на основании которых вершина выбирает себе пару.
Вершина v для каждой своей смежной вершины u, не зависимо от того, имеет ли u пару, либо ещё нет, НЕМ*+ вычисляет значение t(v, u). Это значение равно сумме весов рёбер. ведущих из вершин v и u в их общие смежные вершины, плюс вес ребра {v, u}, рис. 2.
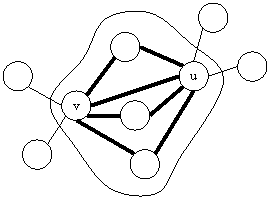

Рисунок 2 – HEM*+
После расчета значений t(v, u) кандидатами для стягивания являются только те вершины, у которых t(v, u) максимально. Кроме того, v может выбрать u только тогда, когда t(u, v) максимально для вершин, смежных с u, что является учётом «мнения» вершины u. Если таких вершин для v нет, либо все вершины заняты, для которых t(v, u) максимально, то v не выбирает себе пары.
Предполагается, что НЕМ*+ генерирует графы с меньшей средней степенью вершин, чем НЕМ*. Анализ [19] многоуровневого алгоритма разбиения графов [12] показывает, что чем меньше степень вершин укрупнённого графа, тем лучшие для него удаётся получать разбиения.
Также НЕМ*+ пытается более аккуратно оперировать на границе кластеров с другими вершинами, пытаясь не стянуть вместе вершины из кластера с соседними вершинами. Кластер вершин – группа вершин, которая гораздо плотнее связана друг с другом, чем с остальными вершинами.
Общая схема работы параллельной программной системы разбиения графов следующая.
Вначале списки смежности графа распределяются по узлам кластера. Используется блочное распределение – каждый узел получает примерно |V|/p вершин, где |V| – количество вершин графа, p – количество процессоров. Причём i-й процессор получает списки смежности вершин с индексами |V|/p*i…|V|/p*(i+1), где i = 0…p-1.
После получения своей части графа, каждый узел работает параллельно, вычисляя t() по схеме НЕМ*+ для каждой своей вершины. Процессоры не могут параллельно выбрать пары для своих граничных вершин (вершины, смежные с вершинами на других процессорах), поэтому им приходится делать это по очереди, сообщая о результатах другим процессорам. Такая схема работы необходима для того, чтобы вершина на одном процессоре не выбрала занятую вершину на другом процессоре, а также, чтобы граничная вершина знала, выбрала ли её граничная вершина на другом процессоре.
Теперь все процессоры могут параллельно независимо выбрать пары для своих вершин по схеме HEM*+.
Чтобы увеличить количество вершин, которые находят себе пару по схеме НЕМ*+, для внутренних вершин процессора разрешаются коллизии. Если вершина v не находит себе пары, то она может выбрать вершину u, для которой t(v, u) = t(u, v), даже если вершина u уже выбрала себе пару (либо её выбрали).
Когда для всех вершин определена пара (либо установлено, что для вершины нет подходящей пары), параллельно выполняется стягивание вершин и результаты собираются на один из процессоров, который сохраняет получившийся граф на главный узел компьютерного кластера.
Программная система реализована для 64-битной машины на языке С++ в среде Microsoft Visual Studio 2005 с использованием библиотеки MPI для обмена данными между процессорами компьютерного кластера.
Проведение экспериментов. Эксперименты были проведены на компьютерном кластере ВУЗа. Он представляет собой набор компьютеров – узлов кластера, соединённых между собой сетью 100 Mbit Ethernet.
Для управления компьютерным кластером установлен Microsoft Compute Cluster Pack, в состав которого входит библиотека Microsoft MPI.
В табл. 1 приведены основные характеристики узлов кластера.
Таблица 1. Характеристика узла кластера.
Наименование | Значение |
Операционная система | Microsoft Windows Server 2003 Enterprise x64 Edition, Service Pack 2 |
Тип системы | x64-based PC |
Процессор | 64-битный Core 2 Duo; каждое ядро: EM64T Family 6 Model 15 Stepping 6 GenuineIntel ~1868 Mhz |
Доступная RAM | 477.50 MB |
Доступная VRAM | 1.93 GB |
Свободно на HDD | 59.12 GB |
Существуют пакеты для разбиения графов для последовательных и параллельных машин. Они являются широко используемыми (порядка в 1000 организациях) и применяются на разных этапах во многих областях METIS [20], CHACO, ZOLTAN [21], PARTY [22], JOSTLE [23], SCOTCH [24].
Для проведения экспериментов выбран METIS, поскольку тесты на большом количестве графов показывают, что METIS генерирует существенно лучшие разбиения, чем другие широко используемые алгоритмы, демонстрируя при этом скорость на один либо два порядка выше [15].
Общая схема экспериментов следующая. С помощью Менеджера Задач кластера запускалась предлагаемая параллельная распределённая система. Для разбиения использовались графы из международного архива графов С. Walshaw [18], на которых принято тестировать алгоритмы разбиения графов.
Укрупнённый с помощью данной системы граф посылался для поиска бисекции в METIS. Полученная бисекция сравнивалась с бисекцией исходного графа, найденной с помощью METIS.
Основные результаты работы. В табл. 2 сведены главные результаты экспериментов над предложенными ранее идеями.
Таблица 2. Преимущество нового параллельного алгоритма разбиения графов по сравнению с системой разбиения графов METIS.
Имя графа | |V| | |E| | METIS | Новый алгоритм | Улучшение, % | Время работы, сек. |
add20 | 2 395 | 7 462 | 774 | 736 | 4,90 | 2,49 |
bcsstk32 | 44 609 |
| 6 230 | 5 616 | 9,86 | 44,96 |
bcsstk33 | 8 738 |
| 13 393 | 10 998 | 17,88 | 15,90 |
add32 | 4 960 | 9 462 | 12 | 11 | 8,33 | 3,86 |
bcsstk31 | 35 588 |
| 4 953 | 2 891 | 42,44 | 32,22 |
В табл. 2 для каждого графа указано количество вершин |V| и количество рёбер |E|. Все вершины и рёбра имеют единичный вес. Также приведены стоимости бисекций для графов, найденных METIS и новым параллельным алгоритмом.
Столбец «Улучшение» показывает процент уменьшения количества разрезанных рёбер разбиения, полученного предложенным алгоритмом по сравнению с результатами METIS.
Для предложенного алгоритма указано время его работы, измеренное с помощью MPI функций времени для распределённых вычислений. Приведенное в таблице время включает в себя время на загрузку и распределение графа между процессорами, вычисление эвристических значений для смежных вершин по схеме HEM*+, выбора пар для вершин, стягивание вершин (получения укрупнённого графа), сбор графа на один из процессоров и сохранение полученного графа по сети на главный узел компьютерного кластера.
Количество процессоров для работы программной системы указывалось равным восьми.
Возможное практическое и теоретическое применение. Разработанный конкурсантом параллельный алгоритм разбиения графов практически необходим при разрезании СБИС схем для их моделирования на компьютерном кластере с целью поиска неисправностей, при распределении сетки метода конечных элементов на процессоры кластера для решения задач аэродинамики и термодинамики, для переупорядочивания разреженных матриц для их быстрого параллельного умножения при параллельном решении систем уравнений и многих других практически важных областях [25].
Скорость работы упомянутых параллельных методов существенно зависит от качества получаемых разбиений. Разрезанные рёбра разбиения представляют собой определённый объём коммуникации между процессорами. При снижении стоимости разбиения, сокращается объём передаваемых данных между процессорами, что приводит к увеличению производительности.
Выводы. В работе исследована проблема разбиения графов. Конкурсантом разработан и реализован новый параллельный алгоритм разбиения графов.
Проведены эксперименты на компьютерном кластере для графов из всемирного архива, на которых принято тестировать алгоритмы разбиения графов.
Экспериментально показано, что предложенная схема укрупнения стягивает вместе группы вершин, которым следует находиться в одном подмножестве качественного разбиения графа с большей вероятностью, чем известные на сегодняшний день схемы.
Удалось добиться повышения качества решений, находимых METIS – одной из лучших и широко используемых систем для разбиения графов – вплоть до 42% для некоторых графов. Результат был получен за 32 секунды на 8 процессорах компьютерного кластера.
Дальнейшая работа по усовершенствованию алгоритма заключается в разработке и параллельной реализации специальных эвристик, которые можно применять на этапе восстановления графа в многоуровневой парадигме, чтобы получать ещё более качественные разбиения графов.
Использованные источники и литература
1. Schloegel K., Karypis G., Kumar V., Graph Partitioning for High Performance Scientific Simulations, CRPC Parallel Computing Handbook, Morgan Kaufmann, 2000.
2. Spatial Color Component Matching of Images, 2001.
3. Olson E. et al., Single-Cluster Spectral Graph Partitioning for Robotics Applications, Massachusetts Institute of Technology.
4. Chamberlain B., Graph Partitioning Algorithms for Distributing Workloads of Parallel Computations, 1998.
5. Yelick K., CS 267: Applications of Parallel Computers. Graph Partitioning, 2004.
6. Douglas et al., Cache Optimization for Structured and Unstructured Grid Multigrid, 2000.
7. Zabih R., Kolmogorov V., Spatially Coherent Clustering Using Graph Cuts, 2004.
8. Cong J., Smith M., A Parallel Bottom-up Clustering Algorithm with Applications to Circuit Partitioning in VLSI Design.
9. Вычислительные машины и труднорешаемые задачи, М.: Мир, 1982.
10. Karypis G., Kumar V., Parallel Multilevel k-way Partitioning Scheme for Irregular Graphs, 1998.
11. Karypis G., Kumar V., Multilevel k-way Partitioning Scheme for Irregular Graphs, 1998.
12. Karypis G., Kumar V., A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs, 1998.
13. Walshaw С., Multilevel Refinement for Combinatorial Optimization Problems, 2004.
14. Mohiuddin W., Multilevel Graph Partitioning and Fiduccia-Mattheyses.
15. Karypis G., Kumar V., METIS: A Software Package for Partitioning Unstructured Graphs, Partitioning Meshes, and Computing Fill-Reducing Orderings of Sparse Matrices. Version 4.0.
16. Kernighan B. W., Lin S., An Efficient Heuristic Procedure for Partitioning Graphs, The Bell Sys. Tech. Journal, vol. 49, no.2, pp. 291-307, 1970.
17. Fiduccia C., Mattheyses R., A Linear Time Heuristic for Improving Network Partitions, In Proc. 19th ACM/IEEE Design Automation Conference, 175-181, 1982.
18. Международный архив графов для тестирования алгоритмов разбиения графов, http://staffweb.cms.gre.ac.uk/~c.walshaw
19. Karypis G., Kumar V., Analysis of multilevel Graph Partitioning, Supercomputing 1995.
20. Пакет для разбиения графов METIS, http://www.cs.umn.edu/~karypis/metis
21. Пакеты для разбиения графов CHACO и ZOLTAN, http://www.cs.sandia.gov/Chaco/, http://www.cs.sandia.gov/Zoltan/
22. Пакет для разбиения графов PARTY, http://www.uni-paderborn.de/fachbereich/AG/monien/RESEARCH/ PART/party.html
23. Пакет для разбиения графов JOSTLE, http://staffweb.cms.gre.ac.uk/~c.walshaw/jostle/
24. Пакет для разбиения графов SCOTCH, http://www.labri.u-bordeaux.fr/~pelegrin/scotch/
25. Walshaw C., Cross M., JOSTLE: parallel multilevel graph-partitioning software – an overview, 2007.
