

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Связность (агрегация) знаний является основным способом, обеспечивающим ускорение поиска релевантных знаний. Большинство специалистов пришли к убеждению, что знания следует организовывать вокруг наиболее важных объектов (сущностей) предметной области. Все знания, характеризующие некоторую сущность, связываются и представляются в виде отдельного объекта. При подобной организации знаний, если системе понадобилась информация о некоторой сущности, она ищет объект, описывающий эту сущность, а затем уже внутри объекта отыскивает информацию о данной сущности. В объектах целесообразно выделять два типа связок между элементами: внутренние и внешние. Внутренние связки объединяют элементы в единый объект и предназначены для выражения структуры объекта. Внешние связки отражают взаимозависимости, существующие между объектами в области экспертизы. Многие исследователи классифицируют внешние связки на логические и ассоциативные. Логические связки выражают семантические отношения между элементами знаний. Ассоциативные связки предназначены для обеспечения взаимосвязей, способствующих ускорению процесса поиска релевантных знаний.
Основной проблемой при работе с большой базой знаний является проблема поиска знаний, релевантных решаемой задаче. В связи с тем, что в обрабатываемых данных может не содержаться явных указаний на значения, необходимые для их обработки, необходим более общий механизм доступа, чем метод прямого доступа (метод явных ссылок). Задача этого механизма состоит в том, чтобы по некоторому описанию сущности, имеющемуся в рабочей памяти, найти в базе знаний объекты, удовлетворяющие этому описанию. Очевидно, что упорядочение и структурирование знаний могут значительно ускорить процесс поиска.
Нахождение желаемых объектов в общем случае уместно рассматривать как двухэтапный процесс. На первом этапе, соответствующем процессу выбора по ассоциативным связкам, совершается предварительный перебор в базе знаний потенциальных кандидатов на роль желаемых объектов. На втором этапе путем выполнения операции сопоставления потенциальных кандидатов с описаниями кандидатов осуществляется окончательный выбор искомых объектов. При организации подобного механизма доступа возникают определенные трудности (как выбрать критерий пригодности кандидата? как организовать работу в конфликтных ситуациях?) и т. п.
Операция сопоставления может использоваться не только как средство выбора нужного объекта из множества кандидатов; она может быть использована для классификации, подтверждения, декомпозиции и коррекции. Для идентификации неизвестного объекта он может быть сопоставлен с некоторыми известными образцами. Это позволит классифицировать неизвестный объект как такой известный образец, при сопоставлении с которым были получены лучшие результаты. При поиске сопоставление используется для подтверждения некоторых кандидатов из множества возможных. Если осуществлять сопоставление некоторого неизвестного объекта с неизвестным описанием, то в случае успешного сопоставления будет осуществлена частичная декомпозиция описания.
Операции сопоставления весьма разнообразны. Обычно выделяют следующие их формы: синтаксическое, параметрическое, семантическое и принуждаемое сопоставления. В случае синтаксического сопоставления соотносят формы (образцы), а не содержание объектов. Успешным является сопоставление, в результате которого образцы оказываются идентичными. Обычно считается, что переменная одного образца может быть идентична любой константе (или выражению) другого образца. Иногда на переменные, входящие в образец, накладываются требования, определяющие тип констант, с которыми они могут сопоставляться. Результат синтаксического сопоставления является бинарным: образцы сопоставляются или не сопоставляются. В параметрическом сопоставлении вводится параметр, определяющий степень сопоставления. В случае семантического сопоставления соотносят не образцы объектов, а функции. В случае принуждаемого сопоставления один сопоставляемый образец рассматривается с точки зрения другого. В отличие от других типов сопоставления здесь может быть получен положительный результат. Вопрос состоит в силе принуждения. Принуждение могут выполнять специальные процедуры, связываемые с объектами. Если эти процедуры не в состоянии осуществить сопоставление, то система сообщает, что успех может быть достигнут только в случае, если определенные части рассматриваемых сущностей можно считать сопоставляющимися.
3. Модели представления знаний в экспертных системах
Характеристики экспертной системы во многом зависят от модели представления знаний в ней — формального способа описания реального мира, который, в свою очередь, зависит от области использования экспертной системы.
Часто вопрос выбора модели представления знания сводят к обсуждению баланса между декларативным (ДП) и процедурным представлением (ПП). Различие между ДП и ПП можно выразить как различие между «знать что» и «знать как». ПП основано на предпосылке, что интеллектуальная деятельность есть знание проблемной среды, вложенное в программы, то есть знание о том, как можно использовать те или иные сущности. ДП основано на предпосылке, что знание неких сущностей («знать что») не имеет глубоких связей с процедурами, используемыми для обработки этих сущностей. При использовании ДП считается, что интеллектуальность базируется на некотором универсальном множестве процедур, обрабатывающих факты любого типа, и на множестве специфических фактов, описывающих частную область знаний. Основное достоинство ДП по сравнению с ПП заключается в том, что в ДП нет необходимости указывать способ использования конкретных фрагментов знания. Простые утверждения могут использоваться несколькими способами, и может оказаться неудобным фиксировать эти способы заранее. Указанное свойство обеспечивает гибкость и экономичность ДП, так как позволяет по-разному использовать одни и те же факты.
В ДП знание рассматривается как множество независимых или слабозависимых фактов, что позволяет осуществлять модификацию знаний и обучение простым добавлением или устранением утверждений. Для ПП проблема модификации значительно сложнее, так как здесь необходимо учитывать, каким образом используется данное утверждение. Однако известно, что существует значительное количество сущностей, которые удобно представить в виде процедур и весьма трудно – в чисто декларативном представлении. Желание использовать достоинства ДП и ПП привело к разработке формализмов, использующих смешанное представление, то есть декларативное представление с присоединенными процедурами (например, фрейм-представление или сети с присоединенными процедурами) или процедурное представление в виде модулей с декларативными образцами. В наиболее совершенном виде эта проблема реализована в объектно-ориентированном подходе.
Модели представления знаний обычно делят на логические (формальные) и эвристические (формализованные). В основе логических моделей представления знаний лежит понятие формальной системы (теории). Примерами формальных теорий могут служить исчисление предикатов и любая конкретная система продукций. В логических моделях, как правило, используется исчисление предикатов первого порядка, дополненное рядом эвристических стратегий. Эти методы являются системами дедуктивного типа, так как в них используется модель получения вывода из заданной системы посылок с помощью фиксированной системы правил вывода. Дальнейшим развитием предикатных систем являются системы индуктивного типа, в которых правила вывода порождаются системой на основе обработки конечного числа обучающих примеров.
В логических моделях представления знаний отношения, существующие между отдельными единицами знаний, выражаются только с помощью тех небогатых средств, которые предоставляются синтаксическими правилами используемой формальной системы.
В отличие от формальных моделей эвристические модели имеют разнообразный набор средств, передающих специфические особенности той или иной проблемной области. Именно поэтому эвристические модели превосходят логические как по возможности адекватно представить проблемную среду, так и по эффективности используемых правил вывода. К эвристическим моделям, используемым в экспертных системах, можно отнести сетевые, фреймовые, продукционные и объектно-ориентированные модели. Следует отметить, что продукционные модели, используемые для представления знаний в экспертных системах, отличаются от формальных продукционных систем тем, что они используют более сложные конструкции правил, а также содержат эвристическую информацию о специфике проблемной среды, выражаемую часто в виде семантических структур.
В настоящее время для баз знаний экспертных систем применяются следующие модели представления знаний:
1. продукционные правила;
2. логическое исчисление;
3. фреймы;
4. семантические сети;
5. объектные модели.
Подходы к представлению знаний
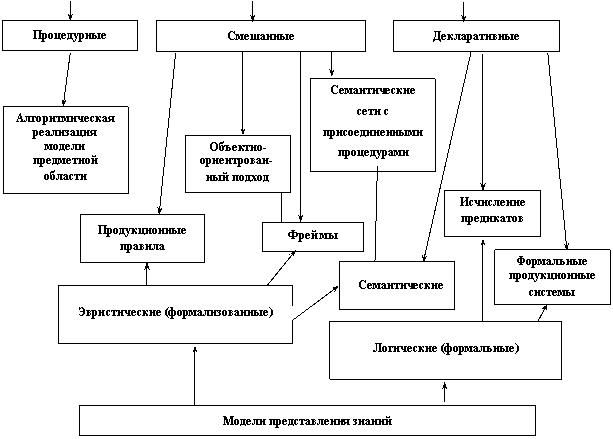
Рис. 12. Способы представления знаний
Более подробная классификация способов представления знаний в базах знаний экспертных систем приведена на рис. 12. Поскольку модель представления знаний должна позволять адекватно отображать некоторую предметную область, то производить детальное сравнение различных моделей между собой отдельно, вне контекста решения какой-либо конкретной задачи не имеет смысла. И тем более невозможно сказать, какой именно подход окажется способным решить любую задачу с максимальной эффективностью.
В продукционных системах база знаний состоит из базы данных и базы правил. База данных содержит факты, описывающие вводимые данные и состояние системы, они могут иметь различную форму, но у всех продукционных систем могут быть представлены как группа данных, содержащая имя данных, имена атрибутов, значения атрибутов.
База знаний содержит набор продукционных правил вида: ЕСЛИ <условие>, ТО <действие>. Механизмом выводов в продукционных системах является интерпретатор правил. Существуют два варианта организации цепочки выводов: суждение по цепочке вперёд и суждение по цепочке назад.
При суждении по цепочке вперёд выполняются все правила, которые могут быть выполнены в настоящий момент, при их исполнении происходит модификация базы данных, которая может привести к возможности выполнения других правил из базы знаний. Основной недостаток состоит в том, что необходимо пройти всю цепочку, чтобы получить требуемый результат (излишние затраты времени и финансовых средств, то есть неоптимальная работа системы).
 Эффективнее вывод при суждении по цепочке назад: в базе правил отыскивается правило, содержащее искомый факт в правой части (после TO), а затем в базе данных ищутся факты, указанные в левой части правила (после ЕСЛИ). Если таких фактов нет, система пытается найти правила, позволяющие прийти к ним, и так происходит до тех пор, пока не будут найдены все требуемые факты ("удача рассуждения"), или же не будет исчерпана возможность их нахождения ("неудача рассуждения"). В общем виде функционирование продукционной системы представлено на рис. 12.
Эффективнее вывод при суждении по цепочке назад: в базе правил отыскивается правило, содержащее искомый факт в правой части (после TO), а затем в базе данных ищутся факты, указанные в левой части правила (после ЕСЛИ). Если таких фактов нет, система пытается найти правила, позволяющие прийти к ним, и так происходит до тех пор, пока не будут найдены все требуемые факты ("удача рассуждения"), или же не будет исчерпана возможность их нахождения ("неудача рассуждения"). В общем виде функционирование продукционной системы представлено на рис. 12.
Рис. 12. Функционирование продукционной системы
В логическом исчислении применяются модели представления знаний с помощью предикатов (функций n-переменных произвольных типов, возвращающих логические значения истина или ложь) и представление знаний в виде логически правильных формул. При обработке знаний с помощью исчисления предикатов исключительно важное значение приобретает возможность логически выводить новые факты и правила из некоторого заданного набора. Вообще, способность логики к порождению ("логическому выводу") новой информации на основании старой представляет интерес в сфере программирования как средства для управляемого автоматизированного порождения логического вывода.
Конструирование сложных высказываний из элементарных с помощью кванторов и логических связок подчиняется определенным правилам, называемым правилами построения. Образованные по этим правилам сложные высказывания называются правильно построенными формулами ППФ. Правила вывода — утверждения самого общего характера о взаимосвязях между допущениями и заключениями, которые с позиций исчисления предикатов всегда справедливы. В исчислении предикатов есть много различных правил вывода. Обладая для исчисления предикатов универсальной истинностью, они могут применяться либо для установления истинности утверждения в целом, либо для порождения заключения. Их можно использовать отдельно и в сочетании с другими правилами. К таким правилам, например, относится правило двойного отрицания: А |- ~(~А), правило А->В, А|-В, правило А->В, ~В|- ~А и т. д. Одно из отрицательных свойств исчисления предикатов – множество путей утверждения одного и того же положения. Другим недостатком можно считать то, что при автоматизации процесса обработки знаний с помощью логического вывода возникает ряд серьезных проблем, связанных с различной природой рассуждений в исчислении предикатов и ходом рассуждений, основанном на здравом смысле.
Метод резолюций позволяет справится с такими проблемами, как выбор правил вывода и порождение не относящихся к делу высказываний, путем сведения процедуры доказательства к применению единственного правила. В случае использования метода резолюций выполняется операция исключения высказывания из различных предложений, если эти высказывания противоречивы (в одних предложениях отрицаются, в других — нет).
Преимущество логических моделей состоит в единственности теоретического обоснования и возможности реализации системы формально точных определений и выводов. Недостатком таких моделей является то, что классическая логика не позволяет решать ряд задач, что может требовать включения временных, модальных и т. п. категорий, для которых отсутствуют автоматические системы вывода, а также сложность создания подсистемы объяснений.
Одним из способов, позволяющим решать более широкий класс задач на основе логических моделей, является применение нечеткой логики (fuzzy logic). Подход, основанный на идеях нечеткой логики, в последнее время все шире используется как при создании экспертных систем, так и при создании автономных управляющих систем. Также, как булева логика строится на основе понятия множеств, нечеткая логика строится на основе понятия нечетких множеств.
То знание, которое использует эксперт при оценке признаков, обычно базируется скорее на отношениях между классами данных и классами гипотез, чем на отношениях между отдельными данными и конкретными гипотезами. Большинство методик решения проблем в той или иной форме включает классификацию данных (сигналов, признаков и т. п.), которые рассматриваются как конкретные представители некоторых более общих категорий. Редко когда эти более общие категории могут быть четко очерчены. Конкретный объект может обладать частью характерных признаков определенной категории, а частью не обладать, принадлежность конкретного объекта к определенному классу может быть размыта. Предложенная Заде, теория нечетких множеств представляет собой формализм, предназначенный для формирования суждений о таких категориях и принадлежащих к ним объектах. Эта теория лежит в основе нечеткой логики (fuzzy logic) и теории возможностей (possibility theory).
Классическая теория множеств базируется на двузначной логике. Выражения в форме а Î А, где а представляет индивидуальный объект, а А — множество подобных объектов, могут принимать только значение истина либо ложь. После появления понятия нечеткое множество прежние классические множества иногда стали называть жесткими. Жесткость классической теории множеств стала источником ряда проблем при попытке применить ее к нечетко определенным категориям.
Интуитивно кажется, что в противовес жестким множествам, нечеткие множество можно представить как множество с размытыми границами, где принадлежность элементов множеству может быть ранжирована.
В таком случае можно говорить о том, что отдельный объект более или менее типичен для этого множества (категории). Можно с помощью некоторой функции/охарактеризовать степень принадлежности объектов X такому множеству. Функция f(x) определена на интервале [0,1]. Если для объекта X функция f(x) = 1, то объект определенно является членом множества, если f(x) = 0, то объект определенно не является членом множества. Все промежуточные значения означают степень членства объекта X в этом множестве.
Ту роль, которую в классической теории множеств играет двузначная булева логика, в теории нечетких множеств играет многозначная нечеткая логика, в которой предположения о принадлежности объекта множеству, могут принимать действительные значения в интервале от 0 до 1. Используя концепцию неопределенности, вычисления значений сложных выражений производятся следующим образом.
По аналогии с теорией вероятности, если F представляет собой нечеткий предикат, операция отрицания реализуется по формуле
ØF(x) = 1 – F(x).
Но аналоги операций конъюнкции и дизъюнкции в нечеткой логике не имеют никакой связи с теорией вероятностей. В нечеткой логике существует соглашение: если F и G являются нечеткими предикатами, то
fFÙG(X) = min (fF(X),fG(X)).
Аналог операции дизъюнкции в нечеткой логике определяется следующим образом:
fFÚG(X) = max (fF(X),fG(X)).
Здесь также очевидна полная противоположность с теорией вероятностей, в которой
Р(А Ú В) = Р(А) + Р(В) - Р(А Ù В).
Операторы обладают свойствами коммутативности, ассоциативности и взаимной дистрибутивности. Как и к операторам в стандартной логике, к ним применим принцип композитивности, т. е. значения составных выражений вычисляются только по значениям выражений-компонентов. В этом операторы нечеткой логики составляют полную противоположность законам теории вероятностей, согласно которым при вычислении вероятностей конъюнкции и дизъюнкции величин нужно принимать во внимание условные вероятности.
Слот1: Атрибуты слота1 Слот2: Атрибуты слота2 … СлотN: Атрибуты слотаN
Фреймовая модель представляет собой систематизированный в общей теории технологический процесс памяти человека и его сознания. Она имеет все свойства, присущие языку представления знаний, и одновременно являет собой новый способ обработки информации. Фреймовая модель есть метод представления знаний, основанный на теории фреймов, опубликованной М. Минским в 1975 г., как одном из научных подходов к описанию знаний. Основой фреймовой модели является фрейм — структура данных о рассматриваемом объекте или ситуации. (Структура данных о текущей реальной ситуации — фрейм-прототип, структура данных об отображении текущей ситуации (то есть, как она мыслится) – фрейм-экземпляр.) Фрейм представляет собой множество слотов. Каждый слот представляется определённой структурой данных – атрибутами слота. Структура фрейма приведена на рис. 13.
Фрейм: Имя фрейма
[<роль1>] Слот1: Атрибуты слота1 [<роль2>] Слот2: Атрибуты слота2 … СлотN: Атрибуты слотаN
Фрейм: Имя фрейма
Рис. 13. Структура фрейма
Одной из характерных особенностей представления фреймами является назначение наследования (наследование атрибутов). Оно позволяет избежать дублирования информации и устранить противоречивые знания. Выводы во фреймовой системе исполняются обменом сообщениями между фреймами. Достоинствами фреймовой модели является естественность, наглядность представления и модульность, недостатком – отсутствие механизмов управления выводом. Отличие систем представления знаний, основанных на фреймах от систем управления базами данных, заключается в том, что в последних выполняется трансляция схемы БД и во время загрузки базы данных устанавливаются жесткие связи между экземплярами записей в соответствии со схемой. В базах знаний связи устанавливаются оперативно в зависимости от значения атрибутов или слотов в узле.
Фреймовая система не только описывает знания, но и может также использоваться человеком для написания алгоритмов вывода. Благодаря подобным свойствам, можно формально строить фреймовые системы в самом широком диапазоне.
Семантические сети — это формализованное представление знаний в виде ориентированного графа, в котором множество вершин образуется объектами или ситуациями, а множество дуг – отношениями между ними. Выводы на семантических сетях определяются отношениями между множеством дуг, имеющих общие узлы. Если вершины не имеют собственной структуры, то соответствующие сети называют простыми сетями. Если вершины обладают некоторой структурой, то такие сети называют иерархическими.
Одно из основных отличий иерархических семантических сетей от простых семантических сетей состоит в возможности разделить сеть на подсети (пространства) и устанавливать отношения не только между вершинами, но и между пространствами. Все вершины и дуги являются элементами по крайней мере одного пространства. Понятие пространства аналогично понятию скобок в математической нотации. Различные пространства, существующие в сети, могут быть упорядочены в виде дерева пространств, вершинам которого соответствуют пространства, а дугам — отношения видимости. На рис. 14 приведен пример дерева пространств, в соответствии с которым, например, из пространства Р6 (пространство-потомок) видимы все вершины и дуги, лежащие в пространствах-предках P4, P3, Р0, а остальные пространства невидимы. Отношение видимости позволяет сгруппировать пространства в упорядоченные множества — перспективы. Перспектива обычно используется для ограничения сетевых сущностей, видимых некоторой процедурой, работающей с сетью. Обычно в перспективу включают не любые, а иерархически сгруппированные пространства.
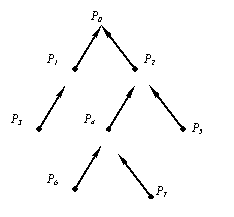
Рис. 14. Пример разбиения сети на пространства
При необходимости в иерархических сетях можно представить любые логические связки и кванторы. Кроме представления логических связок и кванторов сеть может быть использована также для кодирования других структур высших порядков.
При решении многих конкретных задач представление знаний только в виде семантических сетей оказывается неудобным или неэффективным. По этой причине в семантических сетях вводят механизм процедурных присоединений.
Проблемой семантических сетей является смешение групп знаний, относящихся к совершенно различным ситуациям при назначении дуг между узлами, что делает сеть трудной для понимания.
Наиболее развитым способом представления знаний в ЭС является объектно-ориентированная парадигма. Этот подход является развитием фреймового представления. В его основе лежат понятия объект и класс. В реальном мире, а точнее в интересующей разработчика предметной области, в качестве объектов могут рассматриваться конкретные предметы, а также абстрактные или реальные сущности. Объект обладает индивидуальностью и поведением, имеет атрибуты, значения которых определяют его состояние.
Каждый объект является представителем некоторого класса однотипных объектов. Класс определяет общие свойства для всех его объектов. К таким свойствам относятся состав и структура данных, описывающих атрибуты класса и соответствующих объектов, и совокупность методов — процедур, определяющих взаимодействие объектов этого класса с внешней средой. Например, описание класса автомобиль может включать такие атрибуты, определяющие состояние объектов, как название и тип, которые индивидуальны для каждого объекта этого класса – конкретного автомобиля, штатную комплектацию, количество оставшегося топлива, а также методы: перемещение заданным курсом и скоростью и т. д.
Объекты и классы обладают характерными свойствами, которые активно используются при объектно-ориентированном подходе и во многом определяют его преимущества. К этим свойствам относятся перечисленные ниже.
Инкапсуляция — это скрытие информации [8]. При объектно-ориентированном программировании имеется возможность запретить любой доступ к атрибутам объектов, доступ возможен только через его методы. Внутренняя структура объекта в этом случае скрыта от пользователя, объекты можно считать самостоятельными сущностями, отделенными от внешнего мира. Для того чтобы объект произвел некоторое действие, ему извне необходимо послать сообщение, которое инициирует выполнение нужного метода. Инкапсуляция позволяет изменять реализацию любого класса объектов без опасения, что это вызовет нежелательные побочные эффекты в программной системе. Тем самым упрощается процесс исправления ошибок и модификации программ.
Наследование — возможность создавать из классов новые классы по принципу "от общего к частному". Наследование позволяет новым классам при сохранении всех свойств классов-родителей (называемых в дальнейшем суперклассами) добавлять свои черты, отражающие их индивидуальность. С точки зрения программиста новый класс должен содержать только коды и данные для новых или изменяющихся методов. Сообщения, обработка которых не обеспечивается собственными методами класса, передаются суперклассу. Наследование позволяет создавать иерархии классов и является эффективным средством внесения изменений и дополнений в программные системы.
Полиморфизм — способность объектов выбирать метод на основе типов данных, принимаемых в сообщении. Каждый объект может реагировать по-своему на одно и то же сообщение. Полиморфизм позволяет упростить исходные тексты программ, обеспечивает их развитие за счет введения новых методов обработки.
Объектно-ориентированный подход заключается в представлении системы в виде совокупности классов и объектов предметной среды. При этом иерархический характер сложной системы отражается в виде иерархии классов, а ее функционирование рассматривается как взаимодействие объектов, с которыми ассоциируются, например, продукционные правила. Ассоциирование продукционных правил ЭС с иерархией классов осуществляется за счет использования общих правил, в качестве префикса которых обычно используется ссылка на класс, к которому данное правило применимо. Указанный префикс с точки зрения декларативного представления знаний семантически подобен квантору всеобщности в исчислении предикатов.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
