


q | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
πP[q] | 0 | 0 | 0 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 |
Приведенный алгоритм вычисления πP не является эффективным, так как осуществляет лишние проверки. Более эффективным будет использовать ранее полученные результаты (значения функции πP для меньших q). Рассмотрим шаг алгоритма при q = 7 и 8. К моменту обработки q = 7 уже получены значения πP[1] – πP[6]. Если длина максимального префикса продолжает увеличиваться, то первым необходимо проверить префикс, полученный для P6, удлиненный на один символ:
7 | k < 7 | P7 | abcdabc | 3 | |
πP[6]+1 | P3 | abc |
|
К моменту обработки q = 8 уже получены значения πP[1] – πP[7]. Если длина максимального префикса продолжает увеличиваться, то первым необходимо проверить префикс, полученный для P7, удлиненный на один символ. Далее, если совпадения не происходит, стоит проверить префикс длины (πP[πP[7]] + 1) и т. д.:
8 | k < 8 | P8 | abcdabcx | 0 | |
πP[7]+1 | P4 | abcd | |||
πP[4]+1 | P1 | a | |||
!πP[1]+1 = πP[1]! 0 | P0 |
|
Псевдокод алгоритма вычисления префикс-функции приведен в Листинге 3.1.
Листинг 3.1. COMPUTE_PREFIX_F(P) m ← len(P) πP[1] ← 0 k ← 0 for q ← 2 to m do while k > 0 и P[k + 1] ≠ P[q] do k ← πP[k] if P[k + 1] = P[q] then k ← k + 1 πP[q] ← k return πP |
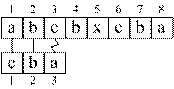
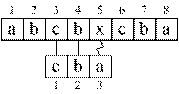
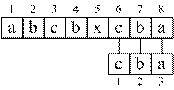
Эвристика[1] стоп-символа. Для эффективного использования эвристики проверка образца должна производиться справа налево. Пусть в процессе сравнения образца с текстом по смещению s обнаруживается несовпадение символов P[i] и T[s+i]. Пусть первое вхождение символа T[s+i] в P находится по индексу k < i. Тогда сдвиг s может быть увеличен на значение (i – k) без риска пропустить допустимый сдвиг. Для применения эвристики стоп-символа необходимо для образца P построить таблицу λP (рис. 3.4, а). Пример применения эвристики стоп-символа приведен на рис. 3.4.
Рис. 3.4 – Пример использования эвристики стоп-символа |
Эвристика безопасного суффикса
Для эффективного использования эвристики проверка образца должна производиться справа налево. Пусть в процессе сравнения образца с текстом (справа налево) по смещению s обнаруживается несовпадение символов P[i] и T[s+i], 0 < i < m, т. е. символы образца с (i+1) по m совпадают с соответствующими символами текста. Эвристика безопасного суффикса предполагает использование знаний о содержимом образца для вычисления максимально возможного сдвига, при котором нет риска пропустить допустимый сдвиг. Для использования эвристики безопасного суффикса необходимо по заданному образцу построить функцию безопасного суффикса (good suffix function) γP, которая определяется следующим образом:
![]()
Рассмотрим на примере прямой алгоритм построения функции γP (рис. 3.5).
Р = "abcdeabcdkbcdmcdsdabcd"
. . .
Рис. 3.5 – Пример вычисления функции безопасного суффикса |

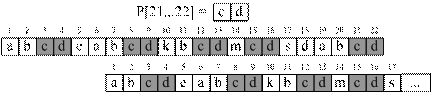
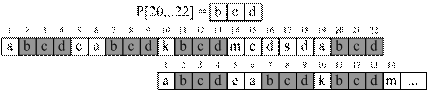

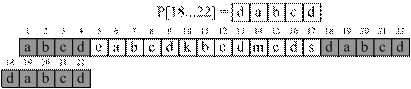
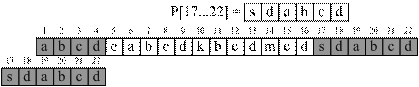
На рис. 3.5 видно, что когда очередной суффикс P[i … m] не может быть найден в образце, то значение функции безопасного суффикса становится равно значению префикс функции для аргумента m (πP[m]). Другими словами мы сдвигаем образец так, чтобы его начало максимально совпало с его окончанием, длина совпадения определяется согласно формуле:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
