


Для организации рекурсивного обхода могут быть использованы функции opendir/readdir/closedir, подробно описанные в общей информации к разделу №2.
Выделение образца в тексте
Для того, чтобы сделать результаты поиска более наглядными можно использовать цветовыделение текста в консоли ОС GNU/Linux. Демонстрационная программа приведена ниже. Более подробную информацию о возможностях представления текста в консоли можно получить по следующим адресам:
1) http://en. wikipedia. org/wiki/ANSI_escape_code#Colors
2) http://tiebing. blogspot. ru/2010/05/add-color-to-your-linux-console-program. html
#include <stdio. h> #define CSI "\x1B\x5B" char colors[][5] = { "0;30", /* Black */, "1;30", /* Dark Gray */, "0;31", /* Red */ "0;33", /* Yellow */, "1;33", /* Bold Yellow */ "0;34", /* Blue */ "1;34", /* Bold Blue */ "0;35", /* Purple */ "1;35", /* Bold Purple */ "0;36", //* Cyan */ "1;36" /*Bold Cyan */ }; int colors_sz = sizeof(colors)/sizeof(colors[0]); int main() { char text1[] = "This is demonstration text\n"; int i; // 1. Print out text with different colors for(i=0;text1[i] != '\0';i++){ int color = i%(colors_sz-2) + 2; // do not use black and dark gray printf("%s%sm%c%s0m",CSI, colors[color],text1[i],CSI); } printf("\n"); // 2. highlight "demonstration" word with red in output text // this word starts at 8th position and ends at 20th position for(i=0;i<8;i++){ printf("%c",text1[i]); } printf("%s%sm",CSI, colors[2]); // setup text color to red for(i=8;i<=20;i++){ printf("%c",text1[i]); } printf("%s0m",CSI); // return normal text color for(i=21;text1[i] != '\0'; i++){ printf("%c",text1[i]); } printf("\n"); // 3. highlight "demonstration" word with RED and ITALIC in output text // this word starts at 8th position and ends at 20th position for(i=0;i<8;i++){ printf("%c",text1[i]); } printf("%s%sm",CSI, colors[2]); // setup text color to red printf("%s4m",CSI); // setup text color to bold for(i=8;i<=20;i++){ printf("%c",text1[i]); } printf("%s0m",CSI); // return normal text color for(i=21;text1[i] != '\0'; i++){ printf("%c",text1[i]); } printf("\n"); // 4. highlight "demonstration" word with RED and WHITE BACKGROUND // this word starts at 8th position and ends at 20th position for(i=0;i<8;i++){ printf("%c",text1[i]); } printf("%s%sm",CSI, colors[2]); // setup text color to red printf("%s47m",CSI); // setup background color to white for(i=8;i<=20;i++){ printf("%c",text1[i]); } printf("%s0m",CSI); // return normal text color for(i=21;text1[i] != '\0'; i++){ printf("%c",text1[i]); } printf("\n"); } |
Литература
1. (CLRS) Алгоритмы: построение и анализ, 2-е изд.: Пер. с англ. – М.: Издательский дом "Вильямс", 2012. – 1296 с.: ил. – Парал. тит. англ. ISBN 978–5–8459–0857–5 (Алгоритмы Рабина-Карпа, Кнута-Моррисона-Пратта и автоматы поиска подстрок описаны)
2. Алгоритмы: построение и анализ, М.:МЦНМО, 2002, 960 с. (Алгоритм Бойера-Мура).
ВАРИАНТ 3.1 АЛГОРИТМ РАБИНА-КАРПА
Задание
Реализовать программу rkmatcher (Rabin-Karp string MATCHER) полнотекстового поиска по шаблону. Шаблон и имя файла (директории) в которой осуществляется поиск передаются через аргументы командной строки в следующем порядке:
$ ./rkmatcher "g*.le" ~/mydir | Анализ всех файлов, расположенных в ~/mydir. |
$ ./rkmatcher -r "g*.le" ~/mydir | Рекурсивный поиск во всех директориях, расположенных ниже ~/mydir. |
Критерии оценки
§ Оценка «отлично»: разработанная программа обеспечивает поиск текста по шаблону рекурсивно в заданной директории. Под рекурсивным поиском понимается анализ всех текстовых файлов в текущей директории, а также во всех вложенных директориях.
§ Оценка «хорошо»: разработанная программа не предусматривает поиск по шаблону ИЛИ не способна выполнять рекурсивный поиск в дереве каталогов (поиск только в одном файле).
§ Оценка «удовлетворительно»: реализован только алгоритм Рабина-Карпа.
Указание к выполнению задания
Алгоритм Рабина-Карпа предусматривает предварительную обработку образца перед его поиском в тексте. Для этого образец рассматривается как целое число по модулю q, где q – параметр алгоритма. Далее в процессе поиска фрагменты текста также представляются в виде целых чисел, с применением которых производится первое (приближенное) сравнение. Сначала рассмотрим задачу поиска цифровой последовательности:
| Производится поиск трехсимвольного сочетания цифр "212". Соответствующее целое число – 212. Если q будет равно 1000, то для поиска образца достаточно будет выполнить сравнение чисел, получаемых из подпоследовательностей текста. Однако в данном примере q = 100, поэтому возможны "коллизии", когда несколько трехсимвольных сочетаний соответствуют одному числу. В примере это "312" и "212". Таким образом, при совпадении чисел необходимо дополнительно выполнить посимвольное сравнение образца с фрагментом текста. |
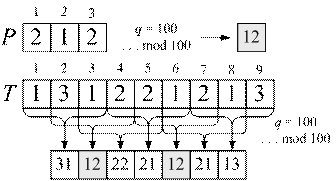
Пусть преобразование некоторой строки x в число в n-ичной системе счисления производится функцией h(x). Если известно число h1, соответвующее строке T[i … (i + m)] ( h1 = h(T[i … i+m]) ), то для вычисления числа h2, соответствующего T[(i + 1) … ( (i +1) + m )], достаточно вычесть из h1 вклад символа T[i], который больше не присутствует во фрагменте текста, далее сдвинуть число h1 на один n-ичный разряд влево, после этого добавить вклад нового символа T[(i +1) + m]. Рассмотрим пример:
T = "", T[3 … 5] = "122", T[4 … 6] = "221", h1 = h(T[3 … 5]), для вычисления h2 необходимо отнять вклад T[3]: h2 = h1 – 102∙'1' = 122 – 100 = 22, далее сдвинуть h2 на один n-ичный разряд влево: h2 = h2∙10 = 220. Следующим шагом требуется прибавить вклад символа T[6]: h2 = h2 + '1' = 221.
Для вычисления числового представления строки, содержащей произвольные символы таблицы ASCII обычно используется тот факт, что каждому символу ставится в соответствие ASCII-код, который находится в диапазоне от 0 до 255. Таким образом строка может быть рассмотрена как число в 256-ричной системе счисления. Более эффективным будет использование следующей функции:
h(x) = code(x[i])∙dm + code(x[i + 1])∙d(m – 1) + … + code(x[i + j])∙d(m – j) + … + code(x[i + m])∙d0, где d – основание используемой системы счисления, при d = 256 каждая строка будет представлена уникально, но предпочтительнее использование значений d = 7, 13, 17, 23, 29, 31, 37 (простые числа). |
В качестве q в работе предлагается использовать ограничения, накладываемые типом unsigned int и стандартную обработку переполнений (отбрасывание старших разрядов), которая реализована в современных процессорах. Рассмотрим обработку переполнения для ячейки размером 1 байт:

Обработка переполнений для многобайтовых ячеек производится аналогичным образом.
ВАРИАНТ 3.2 АВТОМАТЫ ПОИСКА ПОДСТРОК
Задание
Реализовать программу fsmatcher (Finit State Machine string mATCHER) полнотекстового поиска по шаблону. Шаблон и имя файла (директории), в которой осуществляется поиск, передаются через аргументы командной строки в следующем порядке:
$ ./fsmatcher "g*.le" ~/mydir | Анализ всех файлов, расположенных в ~/mydir. |
$ ./fsmatcher -r "g*.le" ~/mydir | Рекурсивный поиск во всех директориях, расположенных ниже ~/mydir. |
Критерии оценки
§ Оценка «отлично»: разработанная программа обеспечивает поиск текста по шаблону рекурсивно в заданной директории. Под рекурсивным поиском понимается анализ всех текстовых файлов в текущей директории, а также во всех вложенных директориях.
§ Оценка «хорошо»: разработанная программа не предусматривает поиск по шаблону ИЛИ не способна выполнять рекурсивный поиск в дереве каталогов (поиск только в одном файле).
§ Оценка «удовлетворительно»: реализован алгоритм поиска с помощью конечного автомата.
Указание к выполнению задания
Алгоритм поиска, использующий конечные автоматы (КА), основан на следующем принципе: для заданного шаблона P[1 … m] строится конечный автомат M(Q,q0,A,∑,δ), где Q = {0, 1, 2, …, m} – конечное множество состояний (states), q0 = 0 – начальное состояние, A = m ‑ конечное множество заключительных состояний. ∑ – входной алфавит, δ(q,a) – функция переходов, которая показывает, в какое состояние переходит КА, находящийся в состоянии q, при появлении символа а входного алфавита.
Функция δ строится для образца, для ее построения используется суффикс-функция, рассмотренная в общем материале к данному разделу. Она определяется следующим образом: δ(q,a) = σ(Pqa), т. е. если КА находился в состоянии q и был обнаружен символ a, то КА переходит в состояние σ(Pqa), т. е. определяет максимальную длину k префикса строки P[1 … q], к которой добавлен символ a, совпадающего со своим суффиксом (![]() a). Рассмотрим пример:
a). Рассмотрим пример:
| Соответствующая графу таблица переходов:
|
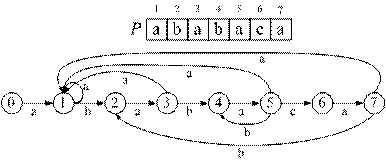
Рассмотрим подробнее некоторые этапы построения полученной таблицы:
1. Если КА находится в начальном состоянии (q = 0), то поступление любого символа, отличного от 'a' оставляет КА в исходном состоянии. Если получен символ 'a', то КА переходит в состояние 1, что означает, что в тексте найдены символы P[1 … 1].
2. Если КА находится в состоянии q = 1 (обнаружены символы P[1 … 1]) и поступает символ 'а', то КА остается в состоянии q = 1 (шаблон передвигается вправо на 1 позицию). Действительно, образец P = "ababaca", а прочитаны символы "aa", вхождение образца в текст возможно только со 2-й или более поздней позиции. Символ 'b' переводит КА в состояние 2, а символ 'c' – в состояние q = 0 (такие дуги не обозначены на рисунке для упрощения его чтения).
На рисунке показаны действия, предпринимаемые при обнаружении допустимых символов, если КА находится в состоянии q = 3 и 5, а также псевдокод алгоритма вычисления δ(q,a).
а |
б |
COMPUTE_TRANSITION_F(P, ∑) m ← len(P) for q ← 0 to m do k ← min(m+1, q+2) while не ( k ← k – 1 δ(q,a) ← k return δ в |
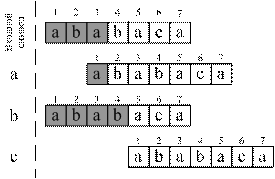
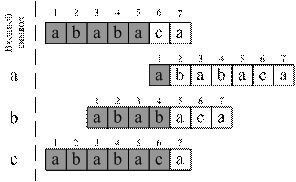
ВАРИАНТ 3.3 АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
