

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Разработан эвристический метод для алгоритма ImpAA, который позволяет получить заметное ускорение для решения ряда абдуктивных задач. Данный эвристический метод использует выбор начального порядка литер в исходных дизъюнктах в целях уменьшения числа шагов алгоритма SOL-резолюции. Метод заключается в упорядочивании литер в дизъюнкте по возрастанию функции Rank(r, RuleBase), действующей на декартовом произведении множества литер и множества множеств дизъюнктов во множество целых чисел и определённой ниже, где r – литера, RuleBase – множество дизъюнктов. Ранг литеры r в RuleBase определяется следующим образом. Находятся дизъюнкты d1, … dn, содержащие Ør, "iÎ{1, …, n} di Î RuleBase. Тогда
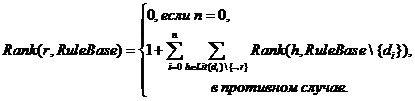
Таким образом, на первых местах (самых левых) в e оказываются литеры, которые, по предложенной функции, приведут к порождению наименьшего числа дизъюнктов. Ранг 0 имеет та литера, по которой резольвирование вообще не происходит. Алгоритмом ImpAA\H назовём модифицированный алгоритм ImpAA, который перед своим выполнением производит упорядочение литер в исходных дизъюнктах согласно предложенной эвристике.
Пусть d – формула ЛП1П. Будем говорить, что унификация s абдуктивно недопустима для d относительно T, если в результате её применения выводится формула g, такая что:
· g является минимальным абдуктивным объяснением sd относительно T и
· g не является минимальным абдуктивным объяснением d относительно T.
Разработаны модификации алгоритмов ImpAA и ImpAA\H – ImpAA\M и ImpAA\M\H соответственно. В данных модификациях разрешены абдуктивно недопустимые унификации, которые не разрешены в ImpAA и ImpAA\H. Данные модификации позволяют использовать разработанные алгоритмы в решении задачи составления расписания.
В третьей главе, исходя из выявленных достоинств и недостатков алгоритмов, рассмотренных ранее, предлагается новый алгоритм абдуктивного вывода, использующий систему поддержки истинности на основе предположений, предназначенный для обработки реальных массивов данных. При этом учитываются такие особенности информации, хранящейся в реальных массивах данных, как большой объем, а также неполнота и противоречивость данных.
Основной структурой данных ATMS является вершина (node), которая имеет формат <данное, метка, обоснования>. Возможны следующие типы вершин ATMS:
· предположение – обозначает допущение о некотором факте, принятое за истину, но которое может стать ложным, и отвергнуто из дальнейшего рассмотрения;
· выведенная вершина – некоторое утверждение, выведенное решающей системой;
· противоречие – используется решающей системой для обозначения обнаруженных противоречий: ATMS гарантирует, что никакая вершина не будет рассматриваться из множества предположений, если вершина противоречия также следует из этого множества предположений.
С каждым утверждением связывается обоснование, состоящее из трех частей: обосновываемой вершины, называемой заключением, списка обосновывающих вершин и описания обоснования решающей системой. Обоснования имеют следующий вид: ![]() , где
, где 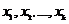 – родительские вершины, а
– родительские вершины, а ![]() – заключение. Данными вершин обоснования выступают атомы. Таким образом, обоснование представляет импликацию
– заключение. Данными вершин обоснования выступают атомы. Таким образом, обоснование представляет импликацию 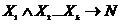 , где
, где ![]() – это данные вершин
– это данные вершин ![]() соответственно. Таким образом, обоснования – это хорновские дизъюнкты.
соответственно. Таким образом, обоснования – это хорновские дизъюнкты.
Множество предположений ATMS называется окружением. Также вводится противоречивое окружение, представляющее собой противоречивую конъюнкцию предположений.
Говорят, что вершина n содержится в окружении E, если n может быть получена из E и текущего множества обоснований J.
Окружение противоречиво, если из него выводима ложь (![]() ).
).
Меткой вершины называется минимальное множество окружений, из которых выводима данная вершина. Метка описывает предположения данных и в отличие от обоснований строится самой ATMS.
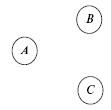
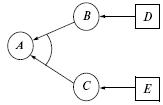
Есть три основные операции ATMS: создание вершины с информацией решающей системы, создание предположения и добавление обоснования к вершине. Эти операции проиллюстрированы на рис. 1 – 3. На рис. 1 создаются вершины с данными A, B и C, на рис. 2 – предположения D и E. На рис. 3 к вершине A добавляется обоснование B![]() C, к вершинам B и C – обоснования D и E соответственно. Здесь овалом (кругом) обозначается выведенная вершина, а прямоугольником (квадратом) – вершина-предположение.
C, к вершинам B и C – обоснования D и E соответственно. Здесь овалом (кругом) обозначается выведенная вершина, а прямоугольником (квадратом) – вершина-предположение.
Рис. 1 |
Рис. 2 |
Рис. 3 |
Также важна операция вычисления метки вершины, которая может быть описана с помощью операций над множествами или при помощи логических операций. В терминах множеств метка вершины n вычисляется как
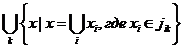 ,
,
здесь ![]() – метка i-й вершины k-го обоснования вершины n. Если метки рассматривать как пропозициональные выражения в дизъюнктивной нормальной форме, то метка вершины n вычисляется как
– метка i-й вершины k-го обоснования вершины n. Если метки рассматривать как пропозициональные выражения в дизъюнктивной нормальной форме, то метка вершины n вычисляется как 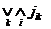 .
.
Ключевым достоинством систем поддержки истинности, основанных на предположениях, является сохранение промежуточных результатов, благодаря чему при организации абдуктивного вывода промежуточные результаты кэшируются, и нет необходимости в повторных вычислениях. Это определяет выбор ATMS в качестве системы поддержки истинности, используемой в организации абдуктивного вывода.
Далее представлены шаги разработанного алгоритма ABAA, использующего систему поддержки истинности на основе предположений.
Алгоритм 1. Алгоритм ABAA.
Исходные данные:
clauses – исходное множество дизъюнктов,
observed – наблюдаемый конъюнкт.
Выходные данные:
result – множество абдуктивных объяснений для observed (результирующее множество конъюнктов).
Начало.
Шаг 1. | Если все дизъюнкты из clauses – хорновские дизъюнкты, то переход к шагу 2. Иначе ОШИБКА, Сообщение “Все дизъюнкты должны быть хорновскими!”, Конец. |
Шаг 2. | Вычислить множество |
Шаг 3. | Пусть O1,O2... – это литеры observed. Создать вершину GOAL (операция добавления вершины в ATMS) и добавить к ней обоснование |
Шаг 4. | Выполнить процедуру Assume с параметрами nOi, Oi для i=1,2.. (операция добавления предположения в ATMS) |
Шаг 5. | Выполнить процедуру ProcessNode с параметрами GOAL, extendedClauses, GOAL, Æ. |
Шаг 6. | Вычислить метку на вершине GOAL: обращение к процедуре ComputeLabel с параметром GOAL. Найденная метка содержит результирующее множество конъюнктов. Запишем его в result. |
Конец.
Процедура Assume.
Исходные данные:
node – вершина,
litera – литера, по которой делается предположение.
Требуется:
создать предположение для текущей вершины.
Начало.
Шаг 1. | Создать вершину-предположение nLitera с литерой litera и добавить обоснование |
Конец.
Процедура ProcessNode.
Исходные данные:
node – текущая вершина,
clauses – множество дизъюнктов,
mainNode – целевая вершина,
unassumed – список литер, к вершинам которых запрещено добавлять обоснование-предположение.
Требуется:
добавить новые вершины через механизм обратной дедукции.
Начало.
Шаг 1. | Обозначим |
Шаг 2. | Если |
Шаг 3. | Присваиваем |
Конец.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
