
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Фи́льтр Ка́лмана — рекурсивный фильтр, оценивающий вектор состояния динамической системы, используя ряд неполных и зашумленных измерений. Назван в честь Рудольфа Калмана. Фильтр Калмана предназначен для рекурсивного дооценивания вектора состояния априорно известной динамической системы, то есть для расчёта текущего состояния системы необходимо знать текущее измерение, а также предыдущее состояние самого фильтра. Таким образом фильтр Калмана, как и множество других рекурсивных фильтров, реализован во временном представлении, а не в частотном.
Далее, запись вида ![]() соответствует оценке вектора состояния
соответствует оценке вектора состояния ![]() в момент времени (итерации) n, по данным на момент времени m.
в момент времени (итерации) n, по данным на момент времени m.
Состояние фильтра находится в двух переменных:
![]() — оценка вектора состояния динамической системы в момент времени k;
— оценка вектора состояния динамической системы в момент времени k;
![]() — ковариационная матрица ошибок (мера точности оценивания вектора состояния).
— ковариационная матрица ошибок (мера точности оценивания вектора состояния).
Работу каждого шага фильтра Калмана можно разделить на два этапа: прогноз и корректировка. Этап прогноза вычисляет вектор состояния, по его же значению на предыдущем шаге работы фильтра. На этапе корректировки в алгоритм поступают данные текущих измерений, которые используются для уточнения прогнозного значения вектора состояния, и вычисления собственно оценки вектора состояния динамической системы.
Этап прогноза
Вычисление прогнозного значения вектора состояния по априорно известной модели
Вычисление прогнозного значения ковариационной матрицы
Этап корректировки
Вычисление математической невязки прогнозного значения вектора состояния относительно измерений
Ковариационная матрица измерений
Оптимальный по Калману коэффициент усиления
Вычисление оценки вектора состояния через корректировку прогнозного вектора состояния
Обновление ковариационной матрицы ошибок.
Характеристика нейронных сетей, как инструмент ИИ.
Искусственные нейронные сети (ИНС) — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса. Впоследствии, после разработки алгоритмов обучения, получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи.
Модели искусственного нейрона.
Искусственный нейрон — узел искусственной нейронной сети, являющийся упрощённой моделью естественного нейрона.
Математически, искусственный нейрон обычно представляют как некоторую нелинейную функцию от единственного аргумента — линейной комбинации всех входных сигналов. Данную функцию называют функцией активации или функцией срабатывания, передаточной функцией. Полученный результат посылается на единственный выход. Такие искусственные нейроны объединяют в сети — соединяют выходы одних нейронов с входами других. Искусственные нейроны и сети являются основными элементами идеального нейрокомпьютера.
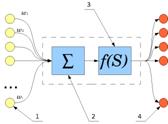
Схема искусственного нейрона:
1.Нейроны, выходные сигналы которых поступают на вход данному.
2.Сумматор входных сигналов
3.Вычислитель передаточной функции
4.Нейроны, на входы которых подаётся выходной сигнал данного
5.wi — веса входных сигналов
Классификация нейронов
В основном, нейроны классифицируют на основе их положения в топологии сети. Разделяют:
Входные нейроны — принимают исходный вектор, кодирующий входной сигнал. Как правило, эти нейроны не выполняют вычислительных операций, а просто передают полученный входной сигнал на выход, возможно, усилив или ослабив его;
Выходные нейроны — представляют из себя выходы сети. В выходных нейронах могут производиться какие-либо вычислительные операции;
Промежуточные нейроны — выполняют основные вычислительные операции.
Основные типы передаточных функций:
Линейная передаточная функция
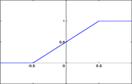 Сигнал на выходе нейрона линейно связан со взвешенной суммой сигналов на его входе.
Сигнал на выходе нейрона линейно связан со взвешенной суммой сигналов на его входе.
f(x) = tx, где t - параметр функции. В искусственных нейронных сетях со слоистой структурой нейроны с передаточными функциями такого типа, как правило, составляют входной слой. Кроме простой линейной функции могут быть использованы её модификации. Например полулинейная функция (если её аргумент меньше нуля, то она равна нулю, а в остальных случаях, ведет себя как линейная) или шаговая (линейная функция с насыщением), которую можно выразить формулой:
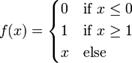 При этом возможен сдвиг функции по обеим осям (как изображено на рисунке).
При этом возможен сдвиг функции по обеим осям (как изображено на рисунке).
Недостатками шаговой и полулинейной активационных функций относительно линейной можно назвать то, что они не являются дифференцируемыми на всей числовой оси, а значит не могут быть использованы при обучении по некоторым алгоритмам.
Пороговая передаточная функция
 Другое название - Функция Хевисайда. Представляет собой перепад. До тех пор пока взвешенный сигнал на входе нейрона не достигает некоторого уровня T — сигнал на выходе равен нулю. Как только сигнал на входе нейрона превышает указанный уровень — выходной сигнал скачкообразно изменяется на единицу. Самый первый представитель слоистых искусственных нейронных сетей — перцептрон состоял исключительно из нейронов такого типа. Математическая запись этой функции выглядит так:
Другое название - Функция Хевисайда. Представляет собой перепад. До тех пор пока взвешенный сигнал на входе нейрона не достигает некоторого уровня T — сигнал на выходе равен нулю. Как только сигнал на входе нейрона превышает указанный уровень — выходной сигнал скачкообразно изменяется на единицу. Самый первый представитель слоистых искусственных нейронных сетей — перцептрон состоял исключительно из нейронов такого типа. Математическая запись этой функции выглядит так:
![]()
Здесь T = − w0x0 — сдвиг функции активации относительно горизонтальной оси, соответственно под x следует понимать взвешенную сумму сигналов на входах нейрона без учёта этого слагаемого. Ввиду того, что данная функция не является дифференцируемой на всей оси абсцисс, её нельзя использовать в сетях, обучающихся по алгоритму обратного распространения ошибки и другим алгоритмам, требующим дифференцируемости передаточной функции.
Сигмоидальная передаточная функция
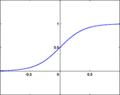 Один из самых часто используемых, на данный момент, типов передаточных функций. Введение функций сигмоидального типа было обусловлено ограниченностью нейронных сетей с пороговой функцией активации нейронов — при такой функции активации любой из выходов сети равен либо нулю, либо единице, что ограничивает использование сетей не в задачах классификации. Использование сигмоидальных функций позволило перейти от бинарных выходов нейрона к аналоговым. Функции передачи такого типа, как правило, присущи нейронам, находящимся во внутренних слоях нейронной сети.
Один из самых часто используемых, на данный момент, типов передаточных функций. Введение функций сигмоидального типа было обусловлено ограниченностью нейронных сетей с пороговой функцией активации нейронов — при такой функции активации любой из выходов сети равен либо нулю, либо единице, что ограничивает использование сетей не в задачах классификации. Использование сигмоидальных функций позволило перейти от бинарных выходов нейрона к аналоговым. Функции передачи такого типа, как правило, присущи нейронам, находящимся во внутренних слоях нейронной сети.
Логистическая функция
Математически эту функцию можно выразить так:
![]() Здесь t — это параметр функции, определяющий её крутизну. Когда t стремится к бесконечности, функция вырождается в пороговую. При t = 0 сигмоида вырождается в постоянную функцию со значением 0,5. Область значений данной функции находится в интервале (0,1). Важным достоинством этой функции является простота её производной:
Здесь t — это параметр функции, определяющий её крутизну. Когда t стремится к бесконечности, функция вырождается в пороговую. При t = 0 сигмоида вырождается в постоянную функцию со значением 0,5. Область значений данной функции находится в интервале (0,1). Важным достоинством этой функции является простота её производной:
![]() То, что производная этой функции может быть выражена через её значение облегчает использование этой функции при обучении сети по алгоритму обратного распространения. Особенностью нейронов с такой передаточной характеристикой является то, что они усиливают сильные сигналы существенно меньше, чем слабые, поскольку области сильных сигналов соответствуют пологим участкам характеристики. Это позволяет предотвратить насыщение от больших сигналов.
То, что производная этой функции может быть выражена через её значение облегчает использование этой функции при обучении сети по алгоритму обратного распространения. Особенностью нейронов с такой передаточной характеристикой является то, что они усиливают сильные сигналы существенно меньше, чем слабые, поскольку области сильных сигналов соответствуют пологим участкам характеристики. Это позволяет предотвратить насыщение от больших сигналов.
Типы обучения.
Корректировка ошибок. Обучение на основе памятиПункты обхода плана последовательно включаются в маршрут, причем, каждый очередной включаемый пункт должен быть ближайшим к последнему выбранному пункту среди всех остальных, ещё не включенных в состав маршрута.
Обучение ХеббаПравило Хебба. Самым старым обучающим правилом является постулат обучения Хебба. Хебб опирался на следующие нейрофизиологические наблюдения: если нейроны с обеих сторон синапса активизируются одновременно и регулярно, то сила синаптической связи возрастает. Важной особенностью этого правила является то, что изменение синаптического веса зависит только от активности нейронов, которые связаны данным синапсом. Это существенно упрощает цепи обучения в реализации VLSI.
Конкурентное обучениеОбучение методом соревнования. В отличие от обучения Хебба, в котором множество выходных нейронов могут возбуждаться одновременно, при соревновательном обучении выходные нейроны соревнуются между собой за активизацию. Это явление известно как правило «победитель берет все». Подобное обучение имеет место в биологических нейронных сетях. Обучение посредством соревнования позволяет кластеризовать входные данные: подобные примеры группируются сетью в соответствии с корреляциями и представляются одним элементом.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
