


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Стек занимает один сегмент памяти, называемый сегментом стека, с сегментным регистром SS, указывающим на начало, т. е. базу стека. Для работы со стеком обычно используют косвенную адресацию через регистр SP – указатель стека, указывающий на текущую ячейку стека, называемую вершиной стека.
В начале работы с SP указывают на последнюю ячейку сегмента стека. При загрузке числа автоматически производится декремент SP := SP–2.
Считывание числа из стека сопровождается автоматическим инкрементом: SP := SP+2, причем считается, что ячейка стека свободна и готова для последующего использования, но ее содержимое после считывания не изменяется.
Для дополнительного обращения к элементам стека (не через вершину) можно использовать регистр ВР, называемый дополнительным указателем стека. Доступ к элементам стека через BP осуществляется на основе определённого расстояния о нужного слова до вершины стека и базовой адресацией:
mov BP, SP ; настройка на вершину стека
mov AX,[BP+4] ; эквивалентно mov AX, SS:[BP+4]
BP по умолчанию относится к сегменту стека, а не к сегменту данных!!!Если в программе нет явного использования стека, то необходимо его зарезервировать в объеме 128Б для автоматического использования.
Стековые команды
а) PUSH op; запись слова в стек, флаги не модифицируются
ор – может быть в регистре (в том числе и в сегментном) или в ячейке памяти, но не непосредственный операнд.
Алгоритм выполнения:
- декремент значения SP:=SP–2;
- пересылка содержимого ор на сводную ячейку стека с адресом [SS:SP] (в польской инверсной записи).
Пример:
PUSH AX
Примечания:
- SP используется по умолчанию
- Записать можно только слово
- Если организуется стековый сегмент в максимальном объеме (64КБ), то при полном заполнении, происходит разрушение ранее записанной информации

- Если стек имеет меньший размер, то при полном его заполнении каждое новое обращение разрушает область памяти вне стекового сегмента
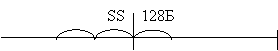 |
б) РОР ор ; чтение слова из стека
ор – аналогично PUSH.
Алгоритм выполнения:
- слово из ячейки стека пересылается в ор (порядок байтов восстанавливается),
- инкремент SP := SP +2
Пример:
POP CX
Примечание: Если пытаться считывать из пустого стека, то ошибка не фиксируется, а считывается слово, следующее за сегментом стека.
в) PUSHF ; копирование слова из регистра FLAGS в стек
POPF ; копирование слова из стека в регистр FLAGS
ор отсутствует, флаги не изменяются.
Эти команды позволяют модифицировать флаг TF. Т. к. другого пути воздействия на TF нет, то нужно выполнить засылку флага в стек, затем изменить 8-й бит и записать новое значение из стека в регистр FLAGS.
Доступ к элементам стека с помощью регистра ВР
Доступ к любому слову, хранящемуся в стеке, осуществляется на основе определения расстояния от нужного слова до вершины стека и базовой адресации.
Например:
MOV BP, SP ; BP := SP
MOV AX,[BP+4] ; эквивалентно MOV AХ, SS:[BP+4]
ВР по умолчанию относится к сегменту стека, а не к сегменту данных!!!
Конструкции языка Ассемблера
Любой язык программирования имеет стандартную структуру, которая позволяет осуществлять структурированное изучение языка.
Все конструкции языка делятся на 4 уровня:
- алфавит;
- элементарные конструкции (лексемы);
- предложения;
- программные единицы.
1. Алфавит
Алфавит языка программирования – это набор символов, который используется в конструкциях языка, а не только в комментариях. Алфавит ЯА будем изучать постепенно, рассматривая лексемы.
2. Лексемы
Лексемы – это элементарные конструкции языка, т. е. слова. В ЯА лексемы представлены пятью классами:
![]()
![]()
![]()
![]() Элементарные конструкции
Элементарные конструкции
Идентификаторы Целые числа Ключевые слова Символьные данные
 | ||||
![]() Метки Имена
Метки Имена
ВЫРАЖЕНИЯ
1. Идентификаторы – это последовательность латинских букв, цифр и символов. ? @ _ $
Особенности применения имен в ЯА:
- длина идентификатора не ограничена, но значащими являются только первые 31 символ;
- идентификатор не может начинаться с цифры;
- точка может быть только первым символом идентификатора; например, возможен идентификатор
.ABR
- в идентификаторе одноименные заглавные и строчные буквы считаются эквивалентными;
- идентификаторы не могут совпадать с зарезервированными (ключевыми) словами.
Идентификаторы делятся на два вида:
а) Имя – ссылка на адрес первого байта, содержащего данные (константы или переменные). Имена описываются директивой декларации.
Пример:
FATAL DB 13
Это имя имеет атрибут (тип) BYTE, WORD и т. д.
б) Метка – идентификатор инструкций или директивы, которая используется для передачи управления.
Метки сегментов и процедур:
LAD SEGMENT
………………….
ENDS
FUN PROC
……………
ENDP.
Метки команд (инструкции) располагаются в начале строки и отличаются от МНК двоеточием. Метка имеет атрибут NEAR или FAR.
В языке ассемблера допускается только одна метка на строке, но можно поместить метку на отдельной строке, что позволяет пометить инструкцию, расположенную на следующей строке. Запрещены метки, состоящие из одного? или $.
Одну и ту же инструкцию можно выполнять дважды:
NACHALO:
LAB:ADD AX, DX
…………………..
JMM NACHALO
………………….
JMP LAB.
2. Ключевые (зарезервированные) слова – это сочетания символов, которые имеют определенный смысл и соответственно воспринимаются Ассемблером.
Например,
.286 – директива, позволяющая использовать в программе команды МП i80286;
AND – мнемоника команды;
AX – имя регистра;
.ERR – директива генерации кода ошибки.
3. Целые числа могут быть записаны в десятичной, восьмеричной или 16-ричной системах счисления, на это указывает буква в конце числа, называемая спецификатором
Основание ПСС | Спецификатор | Примеры |
10 | D или ничего | 25, -387, +4d |
2 | B | 101b, -1001B |
8 | O или Q | 74q, -22Q |
16 | H | 1A3h, -0B4H |
Примечания:
- для 16-чной ПСС, если число начинается с цифры от A до F, то перед ней записывается ноль,
- в числах можно использовать заглавные или строчные латинские буквы.
4. Символьные данные заключаются в одинарные либо двойные кавычки, но левый и правый ограничители должны быть одинаковыми.
Примечания:
- в качестве символов можно использовать любые изображаемые символы и буквы;
- заглавные и строчные буквы различаются;
- если внутри строки символов нужно использовать кавычки, то есть 2 возможности:
или удвоить символ, например, ‘Don’’t’;
или использовать другой вариант ограничителя строки,
например, «Don’t» или ‘кафе «МИР»’
5. Выражения в языке ассемблера состоят из чисел и\или символов, обозначающих числа. Выражение определяет операнд или его адрес.
Например, в декларациях Alpha EQU 10/4 ; константа Alpha равна 2.
Возможные операции в выражениях: + - * / mod () not k (подразумевается инверсия k)
High n – старший байт числа n
Low n – младший байт числа n и т. д.
Выражением считается список констант в декларациях, например:
Area DB 2, -8, 7.
В инструкциях выражения используются только для вычисления адресов операндов, при этом возможны виды адресации:
- Косвенная
- Индексная
- Базовая
- Базово – индексная
В программе можно записать эти адресации разными записями:
Название адреса | Обозначение операнда в инструкции | Формирование адреса |
Косвенная | [Рг B] [Рг U] | [Рг B] [Рг U] |
Индексная | disp [Рг U] [Рг B]+ disp | disp + [Рг U] |
Базовая | disp [Рг B] [Рг B] + disp | disp + [Рг B] |
Базово-индексная | disp [Рг B] [Рг U] disp [Рг B] + [Рг U] disp [Рг B + Рг U] | disp + [Рг B] + [Рг U] |
Где disp – смещение в байтах, которое может быть константой или выражением.
[Рг B] – содержимое базового регистра (BP или BX).
[Рг U] – содержимое индексного регистра (C или D)
Между индексными или базовыми регистрами (способами адресации) разницы нет, но они выделены, т. к. в базово-индексной адресации можно использовать только пары из разных групп, например:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
