

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
7. СЛОВАРЬ ОСНОВНЫХ ТЕРМИНОВ
ARIMA-процесс Бокса-Дженкинса – линейная статистическая модель, основанная на нормальном распределении и позволяющая имитировать поведение множества различных временных рядов, комбинирую процессы авторегрессии (AR), интегрированные процессы (I) и процессы скользящего среднего (MA).
Анализ и методы – раздел отчета, в котором интерпретируются данные путем предоставления графиков, выводов и результатов с соответствующими комментариями и пояснениями.
Анализ сезонных тенденций – непосредственный, интуитивный подход к оценке четырех базовых компонентов месячного или квартального временного ряда (долгосрочная тенденция, сезонные особенности, циклическая вариация и нерегулярный компонент).
Данные временного ряда – значения данных, которые фиксируются в определенной, имеющей содержательный смысл, последовательности.
Исследование данных – изучение имеющейся совокупности данных с различных точек зрения, описание данных и их обобщение.
Линейная модель – модель, исходящая из того, что наблюдаемое значение Y определяется линейными соотношениями в генеральной совокупности плюс нормально распределенная случайная ошибка.
Мультиколлинеарность – проблема возникающая в случае, когда некоторые из объясняющих переменных (X) слишком подобны между собой. В таком случае трудно получить качественные оценки отдельных коэффициентов регрессии по причине нехватки информации для принятия решения относительно того, какую (или какие) из этих переменных необходимо использовать для объяснения.
Прогноз для временных рядов – среднее значение характеристики будущего поведения оцениваемой модели.
Регрессионный анализ – прогнозирование одной Y-переменной по одной или нескольким X-переменным.
Статистика – наука и искусство сбора и анализа данных.
Статистически значимый – результат, являющийся значимым на уровне 5% (p < 0,05).
Статистический показатель – какой-либо показатель, вычисленный на основе рассматриваемой выборки данных.
ПРИЛОЖЕНИЕ 1
Примерный вариант письменной работы для итогового контроля
1. Оценки метода наименьших квадратов коэффициентов регрессии : ![]() останутся несмещенными при нарушении следующих условий теоремы Гаусса – Маркова
останутся несмещенными при нарушении следующих условий теоремы Гаусса – Маркова
1) ![]() при всех i
при всех i
2) ![]() ; i ¹ j,
; i ¹ j,
3) состоящих во включении в модель лишнего объясняющего фактора Z
2. При исключении из регрессии со свободным членом переменной, t – статистика коэффициента при которой меньше 1,
Коэффициент множественной детерминации R2
1) не увеличится
2) не уменьшится
3) может как увеличиться, так и уменьшиться,
а коэффициент множественной детерминации, скорректированный на число степеней свободы
а) не увеличится
б) не уменьшится
в) может как увеличиться, так и уменьшиться
3. По 30 наблюдениям были найдены оценки регрессии ![]()
Затем была оценена регрессия 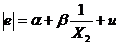 , причем
, причем ![]() ,
, ![]() .
.
При 5% уровне значимости гипотеза об отсутствии гетероскедастичности согласно тесту
1) Глейзера отвергается
2) Глейзера не отвергается
3) Бройша – Пагана отвергается
4) Бройша – Пагана не отвергается
5) Голдфелда – Квандта отвергается
6) Голдфелда – Квандта не отвергается
4. Признаками наличия мультиколлинеарности являются
1) высокий ![]() при низких t-статистиках
при низких t-статистиках
2) высокий ![]() при низкой F-статистике
при низкой F-статистике
3) неадекватные знаки коэффициентов
4) неустойчивость оценок коэффициентов по отношению к изменению размера выборки 5) низкие значения VIF
5. При диагностике автокорреляции бесполезно использовать
1) VIF
2) cтатистику Дарбина-Уотсона
3) график остатков
6. Для проверки какой гипотезы используется тест Бокса-Кокса? Опишите этот тест.
7. По 150 наблюдениям оценили зависимость почасовой заработной платы от пола (переменная MALE равно 1 для мужчин и 0 для женщин), длительности обучения S и возраста AGE.
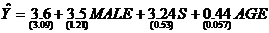 ,
, 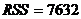
Используя результаты двух вспомогательных регрессий, приведенных ниже, проведите RESET – тест и ответьте, надо ли включать в уравнение нелинейные переменные.
![]() ,
,![]()
![]() ,
, ![]()
8. После оценки модели 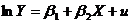
было установлено, что 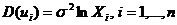 .
.
Как преобразовать модель, чтобы решить проблему гетероскедастичности?
9. По данным для 20 стран были оценены коэффициенты уравнения регрессии
![]()
где Y – младенческая смертность (в расчете на тысячу рожденных),
X2 – GNP в расчете на душу населения,
X3 – процент имеющих начальное образование в определенной возрастной группе.
При проведении теста Уайта была оценена регрессия
![]()
![]()
Проведя тест Уайта, проверьте гипотезу об отсутствии гетероскедастичности.
10. Используя ежегодные данные об агрегированных расходах на покупку автомобилей Y, располагаемом душевом доходе X (обе величины измеряются в миллиардах долларов), а также об индексе относительных цен на автомобили для США в период 1959-1994 г. г., исследователь получил следующее уравнение регрессии:
![]() (1)
(1)
Не удовлетворенный полученным результатом, исследователь использовал процедуру Кокрена – Оркутта и получил:
![]() (2)
(2)
Затем исследователь включил в число объясняющих переменных индекс относительных цен на бензин G, что дало следующий результат:
![]() (3)
(3)
Объясните, почему исследователю не понравились первая и вторая регрессии. Дайте экономическую интерпретацию третьего уравнения регрессии.
ПРИЛОЖЕНИЕ 2
Тренинг 1 «Ранжирование факторов, описывающих деятельность компании, по силе их воздействия на результат, оценивание статистической значимости присутствия каждого фактора в модели».
Описание: Слушатели разбиваются на группы 3-4 чел. Каждой группе предоставляется информация о некоторой условной компании (за которой стоит реальная ситуация с реальной компанией). Группа выполняет ранжирование факторов, описывающих деятельность компании, по силе их воздействия на результат, оценивание статистической значимости присутствия каждого фактора в модели, определение тесноты связи между результатом и соответствующим фактором при неизменном уровне других факторов, включенных в уравнение регрессии.
Каждая группа защищает свои результаты перед остальными группами. (4 часа)
Тренинг 2 «Поиск, отбор важнейших переменных, описывающих деятельность компании, и установление взаимосвязи между ними».
Описание: Слушатели разбиваются на группы 3-4 чел. Каждой группе предоставляется информация о некоторой условной компании (за которой стоит реальная ситуация с реальной компанией). Группа выполняет поиск и отбор переменных, характеризующих деятельность компании, и исследует их структуру. Выбирает зависимую и потенциально независимые переменные. Строит регрессионную модель зависимости, проверяет её адекватность. По модели делается прогноз зависимой переменной. Прогноз сравнивается с реальными (изначально для слушателей неизвестными данными).
Каждая группа защищает предложенную модель перед остальными группами. (4 часа)
Тренинг 3 «Исследование структуры и построение моделей временного ряда по самостоятельно подобранным данным».
Описание: Слушатели разбиваются на группы 3-4 чел. Каждая группа самостоятельно подбирает данные о некоторой условной компании (за которой стоит реальная ситуация с реальной компанией). Группа исследует структуру выбранного временного ряда и при необходимости преобразовывает ряд к стационарному виду. Строит аддитивную и мультипликативную модели временного ряда, проверяет их на адекватность и выбирает из них лучшую модель. С помощью построенной модели прогнозирует значения фактора на несколько периодов вперёд. Прогнозирует экономический временной ряд методом Бокса-Дженкинса. Сравнивает полученные результаты.
Каждая группа защищает предложенную модель перед остальными группами. (4 часа)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
