
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
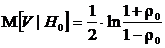 ,
,
центрирование статистики V в формуле (6.8) осуществляется на эту величину.
Пример 6.4. Проведены парные измерения производительности труда Y в зависимости от уровня механизации работ X для 28 промышленных предприятий Московской области. В результате получен выборочный коэффициент корреляции ![]() . Решить следующие две задачи.
. Решить следующие две задачи.
1) В условиях двусторонней альтернативы ![]() найти критическое значение уровня значимости
найти критическое значение уровня значимости ![]() , такое, что при
, такое, что при ![]() гипотеза
гипотеза ![]() будет приниматься для полученного в данной выборке коэффициента корреляции.
будет приниматься для полученного в данной выборке коэффициента корреляции.
2) Для 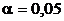 и правосторонней альтернативы
и правосторонней альтернативы ![]() найти критическое значение
найти критическое значение ![]() такое, что при
такое, что при ![]() гипотеза
гипотеза ![]() будет отвергаться в пользу
будет отвергаться в пользу ![]() .
.
![]() 1) Воспользуемся статистикой Фишера (6.8). Так как
1) Воспользуемся статистикой Фишера (6.8). Так как ![]() (проверяется значимость коэффициента корреляции), то
(проверяется значимость коэффициента корреляции), то ![]() , поэтому статистика U принимает вид:
, поэтому статистика U принимает вид:
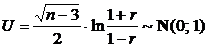 .
.
Вычислим
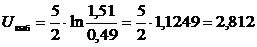 .
.
Примем полученное значение за критическую точку, определяемую как квантиль ![]() из нормального распределения. Из таблицы нормального распределения, полагая
из нормального распределения. Из таблицы нормального распределения, полагая 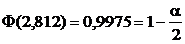 , находим:
, находим: 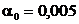 .
.
Таким образом, при ![]() гипотеза
гипотеза ![]() для данного значения
для данного значения ![]() будет приниматься.
будет приниматься.
2) Пусть ![]() . По таблице нормального распределения находим квантиль
. По таблице нормального распределения находим квантиль 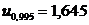 . Отсюда следует, что при
. Отсюда следует, что при ![]() гипотеза
гипотеза ![]() будет отклонена.
будет отклонена.
Решая неравенство ![]() относительно r, получим условие отклонения гипотезы
относительно r, получим условие отклонения гипотезы ![]() в пользу гипотезы
в пользу гипотезы ![]() :
: 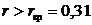 .
. ![]()
6.2. Регрессионный анализ
Зависимость между случайными величинами X и Y называется стохастической, если с изменением одной их них (например, Х) меняется закон распределения другой (Y). В качестве примеров такой зависимости приведем зависимость веса человека (Y) от его роста (Х), предела прочности стали (Y) от ее твердости (Х) и т. д.
В теории вероятностей стохастическую зависимость Y от Х описывают условным математическим ожиданием:
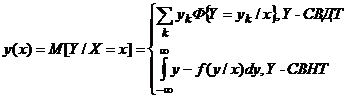
которое, как видно из записи, является функцией от независимой переменной х , имеющей смысл возможного значения случайной величины Х.
Уравнение ![]() называется уравнением регрессии Y на x. Переменная х называется регрессионной переменной или регрессором. График функции
называется уравнением регрессии Y на x. Переменная х называется регрессионной переменной или регрессором. График функции 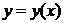 называется линией или кривой регрессии. Кривые регрессии обладают следующим свойством: среди всех действительных функций
называется линией или кривой регрессии. Кривые регрессии обладают следующим свойством: среди всех действительных функций ![]() минимум
минимум 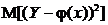 достигается для функции
достигается для функции
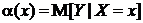 ,
,
т. е. регрессия Y на x дает наилучшее в среднеквадратическом смысле предсказание величины Y по заданному значению ![]() . На практике это используется для прогноза Y по Х: если непосредственно наблюдаемой величиной является лишь компонента Х случайного вектора
. На практике это используется для прогноза Y по Х: если непосредственно наблюдаемой величиной является лишь компонента Х случайного вектора ![]() (например, Х – диаметр сосны), то в качестве прогнозируемого значения Y (высота сосны) берется условное математическое ожидание
(например, Х – диаметр сосны), то в качестве прогнозируемого значения Y (высота сосны) берется условное математическое ожидание ![]() . Наиболее простым является случай, когда регрессия Y на x линейна:
. Наиболее простым является случай, когда регрессия Y на x линейна:
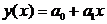 .
.
Если ![]() – случайный вектор, распределенный по двумерному нормальному закону, то коэффициенты
– случайный вектор, распределенный по двумерному нормальному закону, то коэффициенты ![]() и
и ![]() определяются равенствами:
определяются равенствами:
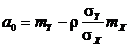 ,
, 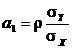 ,
,
уравнением регрессии в этом случае является прямая линия
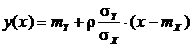 ,
,
проходящая через центр рассеивания ![]() с угловым коэффициентом
с угловым коэффициентом ![]() , называемым коэффициентом регрессии Y на x.
, называемым коэффициентом регрессии Y на x.
В реальных экспериментах, связанных со статической обработкой опытных данных, условный закон распределения случайной величины Y при условии ![]() обычно заранее неизвестен. В таком случае, речь может идти лишь о каком либо приближении к теоретической кривой регрессии, построенном на основе выборочных данных. Другими словами, задача заключается в подборе подходящей функциональной зависимости, наилучшим образом (в некотором статистическом смысле) приближающей стохастическую зависимость.
обычно заранее неизвестен. В таком случае, речь может идти лишь о каком либо приближении к теоретической кривой регрессии, построенном на основе выборочных данных. Другими словами, задача заключается в подборе подходящей функциональной зависимости, наилучшим образом (в некотором статистическом смысле) приближающей стохастическую зависимость.
Во многих случаях можно считать, что «независимая» переменная Х находится под контролем экспериментатора, и может бать измерена с любой заданной точностью, в то время как измеряемые значения Y как функции от Х (выборочные значения ![]() при фиксированных
при фиксированных ![]() ) определяются с ошибкой (содержат шум измерения). Если вид функциональной зависимости зафиксирован, то статистическую модель регрессии можно записать следующим образом:
) определяются с ошибкой (содержат шум измерения). Если вид функциональной зависимости зафиксирован, то статистическую модель регрессии можно записать следующим образом:
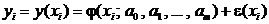 (1)
(1)
где 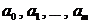 – набор неизвестных параметров, определяющих функциональную зависимость (параметры регрессии);
– набор неизвестных параметров, определяющих функциональную зависимость (параметры регрессии); ![]() – случайные величины, складывающиеся при каждом фиксированном
– случайные величины, складывающиеся при каждом фиксированном ![]() из шума измерений и ошибки модели. При исследовании качества построения модели важно уметь разделять эти ошибки.
из шума измерений и ошибки модели. При исследовании качества построения модели важно уметь разделять эти ошибки.
Следует иметь в виду, что наличие шума измерения делает невозможной задачу интерполяции, т. е. график искомой зависимости не должен проходить через все выборочные точки, а должен проходить таким образом, чтобы «сгладить» шум. Поскольку уровень шума определяется дисперсией ![]() , то задача состоит в подборе параметров
, то задача состоит в подборе параметров ![]() , которые минимизируют
, которые минимизируют ![]() . В действительности минимизируется не сама дисперсия (она неизвестна), а ее выборочная оценка, которая, как будет показано ниже, пропорциональна сумме квадратов отклонений (по оси Оу) кривой регрессии от соответствующих выборочных значений
. В действительности минимизируется не сама дисперсия (она неизвестна), а ее выборочная оценка, которая, как будет показано ниже, пропорциональна сумме квадратов отклонений (по оси Оу) кривой регрессии от соответствующих выборочных значений ![]() , т. е. пропорциональна величине
, т. е. пропорциональна величине

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
