
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 2
2
Указанный критерий минимизации суммы квадратов отклонений носит название метода наименьших квадратов (сокращенно МНК), а полученные в результате решения этой задачи оценки ![]() параметров называются МНК-оценками. Основанием для выбора критерия МНК служит следующая теорема.
параметров называются МНК-оценками. Основанием для выбора критерия МНК служит следующая теорема.
Теорема. Пусть в модели регрессии (1) случайные величины ![]() ,
, ![]() , независимы в совокупности и одинаково распределены по закону
, независимы в совокупности и одинаково распределены по закону 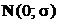 (физически условие
(физически условие ![]() ,
, 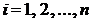 , означает, что измерения проводятся с одинаковой точностью). Тогда МНК-оценки
, означает, что измерения проводятся с одинаковой точностью). Тогда МНК-оценки 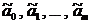 параметров регрессии совпадают с оценками максимального правдоподобия.
параметров регрессии совпадают с оценками максимального правдоподобия.
![]() Заметим, что по условию теоремы
Заметим, что по условию теоремы
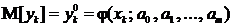 ,
, ![]() ,
,
поэтому наблюдаемые значения ![]() одинаково распределены по закону
одинаково распределены по закону ![]() . Так как
. Так как ![]() независимы в совокупности, то функция правдоподобия выборки запишется в виде
независимы в совокупности, то функция правдоподобия выборки запишется в виде
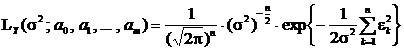 .
.
Из этого выражения следует, что
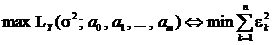 ,
,
что и требовалось доказать. ![]()
Замечание. На практике ошибки измерений часто удовлетворяют поставленным в теореме условиям в силу центральной предельной теоремы.
Регрессионный анализ проводится в три этапа.
На первом этапе по характеру корреляционного поля выдвигают гипотезу о виде функциональной зависимости ![]() . Довольно часто используют следующее представление для функции
. Довольно часто используют следующее представление для функции ![]() :
:
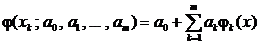 ,
,
где ![]() – известные координатные функции. Такая модель регрессии называется линейной по параметрам. В частном случае, когда
– известные координатные функции. Такая модель регрессии называется линейной по параметрам. В частном случае, когда ![]() , модель называется полиномиальной.
, модель называется полиномиальной.
На втором этапе по имеющимся выборочным данным осуществляют подгонку модели, т. е. находят МНК-оценки неизвестных параметров регрессии ![]() .
.
На третьем этапе анализируют качество построения модели: проверяются так называемые корректность и адекватность модели. Этот этап осуществляется средствами проверки статистических гипотез.
Пример 1. Построение прямой регрессии Y на x.
Пусть получена выборка ![]() ,
, ![]() , из двумерного распределения
, из двумерного распределения ![]() . Корреляционный анализ показал, что корреляционная связь Y на x значима на некотором уровне
. Корреляционный анализ показал, что корреляционная связь Y на x значима на некотором уровне ![]() . Выдвигается гипотеза о том, что уравнение прямой регрессии
. Выдвигается гипотеза о том, что уравнение прямой регрессии
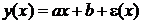
должно хорошо аппроксимировать стохастическую зависимость Y на x. Найти МНК-оценки параметров а и b.
![]() Пусть задан план эксперимента, т. е. совокупность точек
Пусть задан план эксперимента, т. е. совокупность точек ![]() . Выбор этих точек – отдельная задача, решаемая в рамках теории оптимального планирования эксперимента и на данном этапе не обсуждается. Часто точки
. Выбор этих точек – отдельная задача, решаемая в рамках теории оптимального планирования эксперимента и на данном этапе не обсуждается. Часто точки ![]() распределяют эквидистантно, перекрывая интересующий нас интервал на оси Ох.
распределяют эквидистантно, перекрывая интересующий нас интервал на оси Ох.
Искомые оценки являются решениями следующей задачи минимизации:
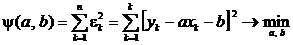 .
.
Применим классический метод поиска безусловного экстремума дифференцируемой функции 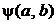 . Запишем необходимые условия экстремума:
. Запишем необходимые условия экстремума:
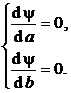
Получаем следующую систему линейных алгебраических уравнений для неизвестных значений а и b:
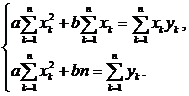
Деля обе части на n и вводя обычные обозначения для выборочных характеристик случайного вектора ![]() , приводим данную систему к виду
, приводим данную систему к виду
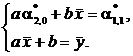 (2)
(2)
где 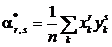 – начальный выборочный момент порядка
– начальный выборочный момент порядка ![]() , и
, и ![]() – средние значения соответствующих переменных.
– средние значения соответствующих переменных.
Решение системы (2), как нетрудно убедиться, имеет вид:
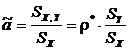 ,
, 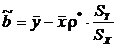 ,
,
где ![]() – выборочный коэффициент корреляции,
– выборочный коэффициент корреляции, ![]() и
и ![]() – выборочные среднеквадратические отклонения.
– выборочные среднеквадратические отклонения.
Уравнение линейной регрессии приобретает вид:
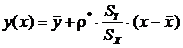 (3)
(3)
Заметим, что полученное уравнение аналогично теоретическому уравнению регрессии, если заметить все входящие в него вероятностные моменты соответствующими выборочными оценками в соответствии с методом подстановки. ![]()
6.3 Однофакторный дисперсионный анализ
Пусть имеется l независимых нормальных совокупностей 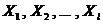 с одной и той же, хотя и неизвестной, дисперсией
с одной и той же, хотя и неизвестной, дисперсией ![]() . Математические ожидания
. Математические ожидания 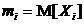 также неизвестны, но имеются основания предполагать, что они равны. Требуется поверить основную гипотезу
также неизвестны, но имеются основания предполагать, что они равны. Требуется поверить основную гипотезу ![]() против альтернативы
против альтернативы ![]() . Для этого из каждой совокупности (подпопуляции)
. Для этого из каждой совокупности (подпопуляции) ![]() взята выборка объема
взята выборка объема ![]() :
:
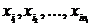 ,
, 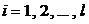 .
.
Формулируется следующая линейная модель дисперсионного анализа:
![]() – j-е наблюдение из i-ой подпопуляции,
– j-е наблюдение из i-ой подпопуляции,
![]() – среднее i-ой подпуляции,
– среднее i-ой подпуляции,
![]() – генеральное (тотальное) среднее всей популяции X,
– генеральное (тотальное) среднее всей популяции X,
![]() – дифференциальный эффект, определяющий различие средних.
– дифференциальный эффект, определяющий различие средних.
Интерпретация. Можно считать, что существует некоторый фактор A, имеющий l уровней, воздействие которого приводит к расщеплению всей популяции X на l подпопуляций ![]() ,
, ![]() . Например, если измерения проводятся на l различных приборах, то можно исследовать влияние фактора «прибор» на результаты измерений. Термин «дисперсионный анализ» был первоначально предложен Р. Фишером (1925) для обработки результатов агрономических опытов, целью которых было выявление условий, позволяющих максимизировать урожай. Современные приложения дисперсионного анализа охватывают широкий круг задач техники, экономики, социологии, биологии, медицины и трактуются в терминах статистической теории проверки гипотез.
. Например, если измерения проводятся на l различных приборах, то можно исследовать влияние фактора «прибор» на результаты измерений. Термин «дисперсионный анализ» был первоначально предложен Р. Фишером (1925) для обработки результатов агрономических опытов, целью которых было выявление условий, позволяющих максимизировать урожай. Современные приложения дисперсионного анализа охватывают широкий круг задач техники, экономики, социологии, биологии, медицины и трактуются в терминах статистической теории проверки гипотез.
Заметим, что если дифференциальные эффекты ![]() малы, то отклонение средних значений отдельных подпопуляций от тотального среднего можно рассматривать как случайное отклонение, и гипотеза
малы, то отклонение средних значений отдельных подпопуляций от тотального среднего можно рассматривать как случайное отклонение, и гипотеза ![]() с большой вероятностью будет принята. Если
с большой вероятностью будет принята. Если ![]() , то получается уже известная нам задача проверки гипотезы о равенстве средних двух независимых нормальных совокупностей.
, то получается уже известная нам задача проверки гипотезы о равенстве средних двух независимых нормальных совокупностей.
Напомним, что для проверки этой гипотезы использовалась статистика Стъюдента W, основанная на нормированной разности выборочных средних. Фишером доказано, что при ![]() подходящей статистикой для проверки указанной гипотезы является фишеровское отношение дисперсий, сконструированных специальным образом.
подходящей статистикой для проверки указанной гипотезы является фишеровское отношение дисперсий, сконструированных специальным образом.
Обозначим выборочное среднее i-ой выборки:
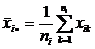 ; (1)
; (1)
общее среднее объединенной выборки:
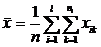 ;
;
объем объединенной выборки:
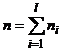 .
.
Легко видеть, что
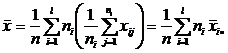 , (2)
, (2)
т. е. тотальное среднее равно среднему арифметическому внутригрупповых средних.
Обозначим через сумму квадратов отклонений результатов наблюдений от общего среднего
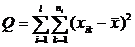 .
.
Очевидно, что
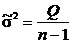
является несмещенной оценкой неизвестной дисперсии ![]() , и кроме того,
, и кроме того, ![]() являются несмещенными и состоятельными оценками математического ожидания
являются несмещенными и состоятельными оценками математического ожидания ![]() .
.
Если гипотеза ![]() верна, то
верна, то ![]() не должны сильно отличаться от общего среднего
не должны сильно отличаться от общего среднего ![]() , но для точного решения задачи нужна подходящая статистика. Идея ее построения основана на разбиении суммы квадратов:
, но для точного решения задачи нужна подходящая статистика. Идея ее построения основана на разбиении суммы квадратов:
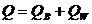 ,
,
где
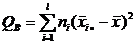 (3)
(3)
– сумма квадратов отклонений «внутри групп»,
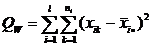 (4)
(4)
– сумма квадратов отклонений «внутри групп».
Покажем, как получается это разбиение. Преобразуем разность:
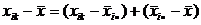 .
.
Возведем в квадрат:
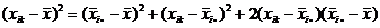 .
.
Далее обе части равенства необходимо просуммировать сначала по k от 1 до , затем по i от 1 до l. Учтем, что согласно (1):
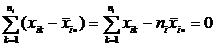 .
.
Поэтому
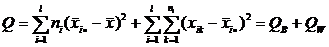 .
.
Выражение для этих сумм можно преобразовать к виду более удобному для вычислений:
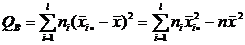 ,
,
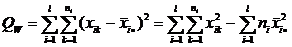 .
.
Теорема. Если ![]() независимы в совокупности,
независимы в совокупности, ![]() , и справедлива гипотеза
, и справедлива гипотеза ![]() , то
, то ![]() и
и ![]() независимы, причем
независимы, причем ![]() распределена по закону
распределена по закону ![]() , а
, а ![]() – по закону
– по закону ![]() .
.
Из этой теоремы и теоремы Фишера следует, что статистика
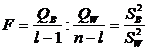
распределена по закону Фишера ![]() . Нетрудно убедиться, что F является подходящей статистикой для проверки гипотезы
. Нетрудно убедиться, что F является подходящей статистикой для проверки гипотезы ![]() . Действительно, если гипотеза
. Действительно, если гипотеза ![]() верна, то величины
верна, то величины ![]() и
и ![]() являются независимыми несмещенными оценками одного и того же параметра
являются независимыми несмещенными оценками одного и того же параметра ![]() . Поэтому
. Поэтому ![]() , что приводит к событию
, что приводит к событию ![]() . Если же верна
. Если же верна ![]() , то разброс между группами будет значительно больше, чем разброс внутри групп, т. е.
, то разброс между группами будет значительно больше, чем разброс внутри групп, т. е. ![]() , что приведет к попаданию
, что приведет к попаданию ![]() в критическую область, и основная гипотеза
в критическую область, и основная гипотеза ![]() будет с большой вероятностью отвергнута.
будет с большой вероятностью отвергнута.
Пример 1. Три группы водителей обучались по различным методикам. По окончанию срока обучения был произведен тестовый контроль над случайно отобранными водителями из каждой группы. Результаты контроля сведены в следующую таблицу:
номер группы,
| число ошибок, допущенных водителями,
| среднее группы,
| число контролируемых водителей,
|
1 | 1 3 2 1 0 2 1 | 1,43 | 7 |
2 | 2 3 2 1 4 | 2,4 | 5 |
3 | 4 5 3 | 4,0 | 3 |
На уровне значимости ![]() проверить гипотезу об отсутствии различий в результатах, получаемых по различным методикам.
проверить гипотезу об отсутствии различий в результатах, получаемых по различным методикам.
![]() В данном случае фактор А – «методика обучения» имеет 3 уровня:
В данном случае фактор А – «методика обучения» имеет 3 уровня:
![]() ,
, 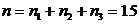 .
.
По формуле (2) вычисляем тотальное среднее выборки: 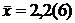 . Далее по формулам (3) и (4) находим
. Далее по формулам (3) и (4) находим ![]() ,
, ![]() .
.
Отсюда
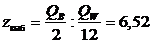 .
.
По таблице квантилей распределения Фишера находим критическую область 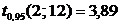 . Отсюда
. Отсюда 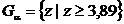 .
.
Поскольку ![]() , то гипотеза
, то гипотеза ![]() отклоняется в пользу
отклоняется в пользу ![]() . Фактор «методика обучения» приводит к значимым результатам в практике вождения автомобиля.
. Фактор «методика обучения» приводит к значимым результатам в практике вождения автомобиля. ![]()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
