


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Кроме односвязных списков, можно строить также и двусвязные. В такой структуре данных каждый элемент имеет указатели на оба соседних. То есть в описании типа элемента добавляется еще одно поле. Например, описание может выглядеть следующим образом:
Type
list=^element;
element=record
inf:string[20];
ukl, ukr:list
end;
У первого элемента указатель ukl будет равен nil, а у последнего элемента значение nil будет иметь указатель ukr.
Эту структуру даны можно применить, например, к решению задачи «Считалка-маятник».
Стеки и очереди
Стек и очередь являются структурами данных, широко применяемыми в стандартных алгоритмах, а также для построения моделей. Эти структуры также как списки являются линейными и определения типов данных для них также совпадают с теми, что применяются для односвязных списков.
Стек или магазин – линейная структура данных, имеющая одно «окно», применяемое для включения в него данных или «вталкивания» и для извлечения данных или «выталкивания». Устройство стека похоже на устройство патронного магазина для пистолета или автомата. Патроны (данные) вталкиваются в магазин при его снаряжении и выталкиваются при перезарядке оружия. При этом первым извлекается патрон, который был вставлен в магазин последним. Таким образом, стек или магазин представляет собой такую структуру, в которой для данных применяется правило «Последний вошел – первый вышел». По-английски это же будет звучать «Last In – Fist Out» или LIFO.
В отличие от стека, очередь следует понимать в обычном бытовом смысле. Очередь – это такая структура, в которой для данных применяется правило «Первый вошел – первый вышел» или по-английски «First In – Fist Out», сокращенно FIFO. Элемент добавляется в хвост очереди, а извлекается из начала.
Рассмотрим простой пример, иллюстрирующий применение стека для вычислений. Пусть нужно вычислить N! – факториал числа N. По определению ![]() . Для выполнения вычислений сначала поместим все значения N>0 в стек, а потом вычислим каждое промежуточное значение факториала, умножая предыдущее значение на извлекаемый из стека множитель.
. Для выполнения вычислений сначала поместим все значения N>0 в стек, а потом вычислим каждое промежуточное значение факториала, умножая предыдущее значение на извлекаемый из стека множитель.
Для работы с данными используем процедуры push – для проталкивания значения в стек и pop – для выталкивания из стека.
Программа | Комментарии |
program stekfactorial; | |
type | |
stek=^element; | Описание типа указателя на элемент стека |
element=record | Описание типа элемента стека |
fn:real; | Информационное поле |
down:stek | Указатель на предыдущий элемент |
end; | |
Var | |
b, c:stek; | Описание статических указателей, b – вершина стека |
n, i:integer; | |
nf, g:real; | |
procedure pop(var x:real); | Процедура выталкивания значения из стека в переменную x |
Begin | |
c:=b; | Запомнили позицию верхнего элемента |
x:=b^.fn; | Считали значение из стека |
b:=b^.down; | Сместили указатель на следующий элемент в стеке |
dispose(c); | Уничтожили извлеченный элемент |
end; | |
procedure push(x:real); | Процедура помещения в стек значения x |
Begin | |
new(c); | Создали новую переменную |
c^.fn:=x; | Записали значение в новый элемент стека |
c^.down:=b; | Установили указатель на предшествующий элемент |
b:=c | Сдвинули указатель вершины стека |
end; | |
Begin | |
readln(n); | Ввод значения переменной |
i:=n; | |
b:=nil; | |
while i>=0 do | Цикл «пока» для помещения значений в стек. |
Begin | |
if i=0 then push(1) | Поместить в стек 0! |
else push(i); | Проталкивание значения множителя |
i:=i-1; | Переход к следующему значению |
end; | |
pop(nf); | Выталкивание значения 0! в переменную nf |
while b<>nil do | Пока стек не пуст |
Begin | |
pop(g); | Выталкиваем значение множителя в переменную g |
nf:=nf*g | Находим следующее значение факториала |
end; | |
writeln(nf) | Печатаем значение результата |
end. |
Двоичные деревья
Двоичные деревья – это структуры данных, которые также как и списки, стеки и очереди широко применяются в практике решения задач программирования. Строго говоря, двоичные деревья являются одним из типов ориентированных графов, не имеющих циклов, узлы которых связываются двумя ребрами с двумя другими узлами графа.
Типичным примером двоичного дерева является генеалогическое дерево, в котором узлом является человек, а ветви связывают его с его собственными родителями. Получается структура: человек, затем его отец и мать, родители отца и родители матери, родители родителей и так далее. Пример такого дерева приведен на рисунке.
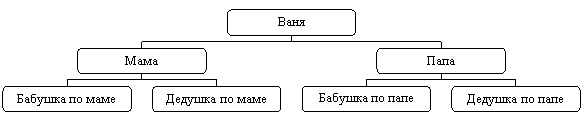

Первый узел двоичного дерева называется корнем, а последние узлы, те из которых нет ребер к следующим, называются вершинами двоичного дерева.
Применение двоичных деревьев, не ограничивается генеалогией. К примеру, рассмотрим арифметическое выражение 2*2+11/2. Это выражение определяет, какие действия надо выполнить с операндами, а правила арифметики устанавливают порядок их выполнения. Каждой операции соответствует два операнда, а результат выполнения операции будет использован в качестве операнда в следующем вычислении или окажется окончательным – равным значению выражения. Для нашего выражения можно построить двоичное дерево аналогичное генеалогическому:
 |
По мере вычислений происходит преобразование (сокращение) дерева.
 |
В скобках указан порядковый номер действия.
Описание данных для построения двоичного дерева практически совпадает со случаем двусвязного списка. Рассмотрим следующую задачу.
Задача 3. Строкой задано арифметическое выражение, в записи которого используются только операции сложения и умножения. Написать программу вычисления значения этого выражения.
Решение. Задачу следует разбить на две части. Сначала построим двоичное дерево, соответствующее выражению, затем произведем вычисление значения.
Для решения первой части опишем процедуру с параметрами – указателем на узел и строкой, содержащей часть обрабатываемого выражения. В этой процедуре будем выяснять, есть ли в обрабатываемом выражении символы операций. Если операций нет, то значением узла станет строка, соответствующая числу-операнду и узел станет вершиной дерева. Если в строке присутствуют знаки операций, то один из них будет помещен в информационное поле узла. Затем будет создана пара новых узлов. Потом произойдет два рекурсивных вызова процедуры параметрами которых будут правая и левая часть строки от знака операции и соответствующие указатели на следующие левый и правый узел.
Для решения второй части задачи определим функцию, параметр которой указатель на узел двоичного дерева. Если узел является вершиной, то в его информационном поле хранится символьная запись числа, которое и станет значение функции. Если же узел является промежуточным, то в его информационном поле хранится символ операции. В этом случае значение функции будет вычисляться рекурсивно как сумма или разность функций, вызванных с параметрами-указателями на следующие правый и левый узлы.
Программа, реализующая этот алгоритм, приведена ниже.
Программа | Комментарии |
program plusminus; | |
type | |
ukaz=^uzel; | Описание типа указателя на узел дерева |
uzel=record | Описание типа узла дерева |
inf:string[16]; | Информационное поле |
ukl, ukr:ukaz | Указатели на левый и правый следующие узлы |
end; | |
var | |
a:ukaz; | Статическая переменная – указатель на корень |
s:string; | Входная строка |
i:integer; | |
y:real; | |
procedure stroim(st:string; var u:ukaz); | Процедура построения дерева |
var | |
i:integer; | |
begin | |
if (pos('-',st)=0)and(pos('+',st)=0) then | Если в строке нет символов операций |
begin | |
u^.inf:=st; | Информационное поле равно параметру st |
u^.ukl:=nil; | Указатель на следующий nil – узел является |
u^.ukr:=nil | вершиной дерева |
end | |
else | |
begin | |
i:=length(st); | Начиная с последнего символа |
while (st[i]<>'+')and(st[i]<>'-') do | ищем знак операции |
i:=i-1; | |
u^.inf:=st[i]; | Знак операции в информационное поле |
new(u^.ukl); | Новый левый узел |
new(u^.ukr); | Новый правый узел |
stroim(copy(st,1,i-1),u^.ukl); | Строим левую ветвь |
stroim(copy(st, i+1,length(st)-i),u^.ukr) | Строим правую ветвь |
end | |
end; | |
function shet(u:ukaz):real; | Функция вычисления результата |
begin | |
if u^.ukl=nil then | Если узел является вершиной |
begin | |
val(u^.inf, y,i); | Преобразуем строку в число |
shet:=y | Результат число |
end | |
else | Иначе |
case u^.inf[1] of | Если операция |
'+': shet:=shet(u^.ukl)+shet(u^.ukr); | +, то результат сумма левого и правого |
'-': shet:=shet(u^.ukl)-shet(u^.ukr) | -, то результат разность левого и правого |
end | |
end; | |
begin | |
readln(s); | Вводим строку |
new(a); | Создаем корень дерева |
stroim(s, a); | Строим дерева |
writeln(shet(a):15:5) | Печать значения функции |
end. |
Файлы

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
