
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 5. Регрессионный анализ
Что такое регрессионный анализ и что такое регрессия? Формальное, математическое определение регрессии – это зависимость среднего значения случайной величины от некоторой другой величины или нескольких величин.
В самом общем смысле, регрессионный анализ – это статистический метод исследования взаимосвязи переменных. В статистике это один из методов, позволяющий устанавливать причинно-следственные отношения.
Итак, регрессионный анализ – группа методов статистического анализа данных, предназначенных для исследования причинных связей между количественными переменными.
Если расчёт корреляции характеризует силу связи между двумя переменными, то регрессионный анализ служит для определения вида этой связи и дает возможность для прогнозирования значения одной (зависимой) переменной отталкиваясь от значения другой (независимой) переменной.
Посмотрим и рассмотрим, какие виды регрессии бывают.
5.1. Простая линейная регрессия
Нередко, имея информацию о какой-то одной характеристике, параметре, показателе и т. д., мы хотим или вынуждены делать выводы о значении другой характеристике, параметре и т. д., связанной некоторым образом с первой. Например, если исключить явно аномальные случай, можно по одному росту более или менее точно предсказывать вес человека.
Простая регрессия не может дать абсолютно достоверного результата, однако с ее помощью можно ответить на вопрос о связи переменных и по заданному значению одной, определяющей переменной рассчитать наиболее вероятное значение другой, зависимой перемнной.
Простая линейная регрессия или линейная регрессия с одной независимой переменной является простейшим видом регрессии и применяется чаще всех остальных видов.
Для проведения линейного регрессионного анализа зависимая переменная должна иметь интервальную (или порядковую) шкалу.
Этот вид регрессии лучше всего подходит для того, чтобы продемонстрировать основополагающие принципы регрессионного анализа. Вспомним диаграмму рассеяния из предыдущих занятий, которая иллюстрирует зависимость показателя холестерина спустя один месяц после начала лечения от исходного показателя, полученную при исследовании гипертонии.
· Загрузите файл:
hyper. sav
· Выберите в меню команду:
Graphs (Графики)
Interactive (Интерактивные)
Scatterplot... (Диаграмма рассеяния)
Откроется диалоговое окно Create Scatterplot (Создание диаграммы рассеяния).
· Перенесите переменные chol0 и chol1 в соответствующие поля открывшегося диалогового окна.
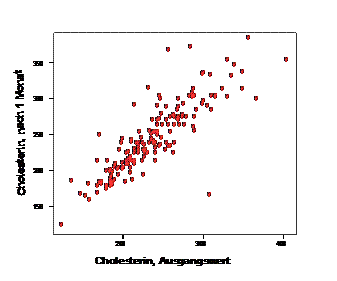
Мы уже отмечали очевидную зависимость одной переменной от другой (а логически это зависимость переменной chol0 от переменной chol1) и говорили, что это прямая зависимость («чем больше, тем больше») и фактически линейная по своему характеру.
Можно легко заметить очевидную связь: обе переменные развиваются в одном направлении и множество точек, соответствующих наблюдаемым значениям показателей, явно концентрируется (за некоторыми исключениями) вблизи прямой (прямой регрессии). В таком случае говорят о линейной связи. Общая формула подобной зависимости известна из математики:
у = k*х + const
При проведении простой линейной регрессии основной задачей является определение параметров k и c. Оптимальным решением этой задачи является такая прямая, для которой сумма квадратов вертикальных расстояний до отдельных точек данных является минимальной.
В нашем примере, выбрав в качестве независимой переменной (т. е. аргумент x) исходный уровень холестерина (переменная chol0), а в качестве зависимой переменной (т. е. функцию у) – показатель холестерина через один месяц (переменная chol1), получим исходной выражение для проведения регрессионного анализа:
chol1 = k*chol0 + c
После определения параметров k и c, зная исходный показатель холестерина, можно прогнозировать показатель, который будет через один месяц. Т. е., говоря в терминах мат. анализа, нам нужно вывести «формулу» функции.
5.1.1. Расчёт уравнения регрессии
Итак…
· Загрузите файл:
hyper. sav
· Выберите в меню команду:
Analyze (Анализ)
Regression (Регрессия)
Linear... (Линейная)
Откроется диалоговое окно Linear Regression (Линейная регрессия).
· Перенесите переменную chol0 в поле для независимых переменных, а переменную chol1 в поле для зависимой переменной.
· Запустите расчёт нажатием кнопки ОК.
В окне просмотра появятся следующие результаты:
Сводка для модели
Модель | R | R квадрат | Скорректированный R квадрат | Стд. ошибка оценки |
1 | ,861a | ,741 | ,740 | 25,258 |
a Предикторы: (константа) Cholesterin, Ausgangswert (Влияющие переменные: (константы), холестерин, исходная величина)
Дисперсионный анализb
Модель | Сумма квадратов | ст. св. | Средний квадрат | F | Знч. | |
1 | Регрессия | 314337,948 | 1 | 314337,948 | 492,722 | ,000(a) |
| Остаток | 109729,408 | 172 | 637,962 | |||
| Итого | 424067,356 | 173 |
a Предикторы: (константа) Cholesterin, Ausgangswert (Влияющие переменные: (константа), холестерин, исходная величина)
b Зависимая переменная: Cholesterin, nach 1 Monat (Зависимая переменная холестерин через 1 месяц)
Коэффициентыa
Модель | Нестандартизованные коэффициенты | Стандартизованные коэффициенты | t | Знч. | ||
B | Стд. ошибка | Бета | ||||
1 | (Константа) | 34,546 | 9,416 | 3,669 | ,000 | |
| Cholesterin, Ausgangswert | ,863 | ,039 | ,861 | 22,197 | ,000 |
a Зависимая переменная: Cholesterin, nach 1 Monat (Зависимая переменная)
По сути, нас реально интересует лишь последняя таблица. В первой таблице обратите внимание на показатель R. Это коэффициент, характеризующий связь между значениями зависимой и независимой переменных и представляет собой уже знакомый нам коэффициент корреляции. Вторая таблица связана с дисперсией.
Что интересного в третьей таблице? В столбце нестандартизованных коэффициентов (столбец с именем B) раз имеем так называемые B-величины:
k = 0,863
c = 34,546
Это значит, что уравнение регрессии имеет следующее формульное выражение:
chol1 = 0,863*chol0 + 34,546
Проверим «функциональную адекватность» полученного выражения. Берем произвольное значение для переменной chol0, например, 300. В соответствии с полученной зависимостью, через один месяц оно должно быть, точнее – можно ожидать его равным, округленно, 293,5 (ожидаемое значение переменной chol1).
Соответствующие уровни значимости свидетельствуют, что искомые коэффициенты действительно существуют, ненулевые и неслучайные.
5.1.2. Сохранение новых переменных
Многочисленные вспомогательные значения, рассчитываемые в ходе построения уравнения регрессии, можно сохранить как переменные и использовать в дальнейших расчётах.
Для этого, при определении параметров расчета линейной регрессии:
· В диалоговом окне Linear Regression (Линейная регрессия) нажмите кнопку Save (Сохранить).
Откроется диалоговое окно Linear Regression: Save (Линейная регрессия: Сохранение).
· Поставьте флажок в поле Predicted values (Прогнозируемые значения) на опции Unstandardized (Нестандартизированные значения)
· Нажмите кнопку Continue (Далее)
· Запустите расчет линейной регрессии кнопкой ОК
Вернитесь в основное окно (редакторе данных) SPSS. Вы увидите, что в наборе переменных появилась новая переменная с именем PRE_1, которая добавлена в конец списка переменных в файле. Эта переменная содержит предсказанные значения на основе исходных значений. Например, посмотрим уже упоминавшийся случай для chol0 = 300. Найдите этот случай с помощью команды Sort. Таких пациентов двое. Для обоих прогнозируемая величина PRE_1 = 293,3. Видно, что это прогнозируемое значение отличается от реальных показателей содержания холестерина, взятых через один месяц (chol1), причем отличается и в большую, и в меньшую стороны.
А небольшое отклонение ранее вычисленного значения (293,5) от значения, хранящегося в переменной PRE_1 объясняется тем, что SPSS использует в расчётах более точные значения, чем те, которые выводятся в окне просмотра результатов (т. е. более точные значения коэффициентов – не 0,863, а…).
Понятно, что регрессию можно использовать для прогнозирования, если нет реальных данных (например, не известны значения показателя холестерина через месяц после начала лечения какого-либо пациента).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
