

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция «Введение в алгоритмы сжатия данных»
Сжатие информации является одной из форм обработки информации, можно сказать, что сжатие данных – тип информационного процесса. Целью использования алгоритмов сжатия – сокращение объема памяти, необходимого для хранения данных или передачи информацией по сетям связи. Сегодня мы остановимся на следующих моментах:
· Определение терминов, использующихся в теории сжатия данных
· Классификация алгоритмов сжатия информации
· Схема кодирования и декодирования данных в архиваторе
· Пример кодирования и оценок результатов кодирования (префиксные коды)
· Обоснование применения алгоритмов сжатия информации для различных типов данных (текста, графики, звука и видео).
Кодирование – одно из центральных понятий в теории информации и теории сжатия данных. Осуществляется преобразование потока символов в некотором алфавите, причем частоты символов различны (частота – сколько раз символ встретился во входном потоке). Целью кодирования является преобразование этого потока в поток битов минимальной длины. Это достигается путем учета частоты символов: длина кода должна быть пропорциональна информации, содержащейся во входном потоке.
Декодирование – обратное преобразование, то есть восстановление информации. Информация может быть восстановлена в первоначальном виде (если производилось преобразование без потери), либо с некоторыми искажениями (если были допущены потери информации). Также происходит и при использовании алгоритмов сжатия – есть алгоритмы сжатия с потерями и без потерь данных.
Обрабатываемое сообщение порождается дискретным источником данных. Приведем формальное определение источника данных.
Алфавитом сообщения называется множество A = {a1, … ,ak}, сообщением называется последовательность символов алфавита (букв) aij. Обозначим xi j подслово последовательности x, начиная с буквы с номером i и заканчивая буквой с номером j. ![]() , что означает: «элемент x порождает всевозможные варианты сообщений, символы которых являются элементами алфавита A». Примером сообщения является последовательность xn = x1x2… xn. Дискретным источником является случайный процесс со значениями в A. Источник задается распределением вероятностей Pr(Xn = xn) = P(xn) – задает вероятность появления того или иного символа. Сумма вероятностей равна единице. Если известно, распределение вероятностей частот (то есть известно, сколько раз встретился каждый символ и подсчитана его вероятность), то можно построить оптимальное кодирование. Задача усложняется в случае, если распределение частот символов неизвестно.
, что означает: «элемент x порождает всевозможные варианты сообщений, символы которых являются элементами алфавита A». Примером сообщения является последовательность xn = x1x2… xn. Дискретным источником является случайный процесс со значениями в A. Источник задается распределением вероятностей Pr(Xn = xn) = P(xn) – задает вероятность появления того или иного символа. Сумма вероятностей равна единице. Если известно, распределение вероятностей частот (то есть известно, сколько раз встретился каждый символ и подсчитана его вероятность), то можно построить оптимальное кодирование. Задача усложняется в случае, если распределение частот символов неизвестно.
В этом случае существует два различных подхода к кодированию сообщений.
Первый: просмотреть входной поток и построить кодирование на основе собранной статистики (при этом потребуется два прохода по файлу), что ограничивает сферу применения таких алгоритмов. В выходной поток должна быть записана схема использованного кодирования, то есть модель, которая затем будет использоваться декодером (при восстановлении сжатой информации). Примером алгоритмов этой группы как раз и является алгоритм Хаффмана, который мы рассмотрим позднее.
Второй: использует так называемый адаптивный кодер. Идея таких алгоритмов состоит в том, чтобы менять схему кодирования в зависимости от исходных данных. Такой алгоритм использует один проход и не требует передачи информации в явном виде. Вместо этого декодер, считывая кодированный поток данных, синхронно с кодером изменяет схему кодирования, начиная с некоторой предопределенной. при использовании которого постоянно необходимо корректировать коды в соответствии с изменяющейся статистикой входного потока.
Алгоритмы сжатия данных применяются в следующих случаях:
1. В программах-архиваторах (WinRAR, WinZip).
2. При передаче данных по сетям связи.
3. В программах резервного копирования (Acronis True Image).
4. В форматах файлов с мультимедиа данными (JPEG, GIF, MP3, AVI).
5. В системах безопасности и видеонаблюдения.
6. В системах телеконференций.
Приведем схему классификации алгоритмов сжатия данных и базовые подходы к сжатию информации.

Рис.1. Классификация алгоритмов сжатия данных
Приведем описание двух типов алгоритмов сжатия информации.
Сжатие данных без потерь
· Статистическое кодирование. Алгоритмы этой группы используются в различных методах сжатия мультимедиа данных с целью улучшения степени сжатия после применения основного алгоритма или преобразования. Также статистические алгоритмы используются для сжатия сигналов других типов после выполнения дискретизации сигналов (преобразования из аналогового представления в цифровую форму). Широко применяются алгоритмы Хаффмана и арифметического кодирования (в стандарте JPEG, например).
· Словарное кодирование. Эти алгоритмы используются в архиваторах (WinZip) и формате сжатия графических изображений GIF (основа – формат LZW).
· Специальные алгоритмы кодирования. Алгоритмы данной группы также могут применяться для сжатия графики и текста. Алгоритм сжатия RLE является самым простым в применении и сопоставляет серии битов значение счетчика – количества повторений. Во многих методах и алгоритмах сжатия мультимедиа данных после выполнения соответствующих преобразований формируется последовательность чисел; элементы этой последовательности содержат большое количество нулей. Это и создает возможности для сжатия.
Алгоритм JBIG разработан подразделением комитета JPEG – группой экспертов в сжатии бинарных изображений специально для сжатия однобитных черно-белых изображений. Например, факсов или отсканированных документов. В принципе, может применяться и к 2-х, и к 4-х битовым картинкам.
Алгоритм Lossless JPEG предназначен для сжатия полноцветных 24-битных безпалитровых (подробнее о типах изображений поговорим дальше) изображений. Он представляет собой специальную реализацию JPEG без потерь.
Алгоритм CCITT Group 3 предназначен для сжатия изображения при передаче по факсу и основан на использовании алгоритма Хаффмана с применением таблиц, построенных с помощью этого алгоритма (алгоритм разбивает изображение на подстроки и кодирует их с помощью двух типов таблиц).
Сжатие данных с потерями
· Сжатие звука – выделяются два типа алгоритмов – линейное предсказание и алгоритм сжатия в MPEG-1. Методы линейного предсказания позволяют предсказывать значение последующих отсчетов (результатов измерений значений сигнала в процессе оцифровки) на основе предыдущих, уже известных значений. Используются для сжатия изображений, речи и звука. В стандартах сжатия видео семейства MPEG помимо сжатия видеоизображений (кадров) отдельно применяется сжатие звука. Потом все результаты собираются вместе. Более подробно мы поговорим об этом, когда будем изучать алгоритмы сжатия звука и видео.
· Видеоизображения. В этой группе выделяются ДКП (дискретное косинусное преобразование с квантованием коэффициентов), вейвлетное и фрактальное преобразование. На эти типы преобразований и будет делаться упор в изучении раздела, посвященного сжатию графических изображений.
Суммируя описание приведенных алгоритмов, можно выделить три основных подхода к сжатию данных:
- Представить символы с высокой вероятностью меньшим числом бит (алгоритм Хаффмана, подход применяется в программе UNIX Compress).
- Закодировать последовательности символов с помощью указания на появление в специально организованной структуре данных – словаре (алгоритмы LZ77, LZ78, LZSS и LZW, а также многочисленные модификации. Подход используется в архиваторах PKZIP, ARC, а также графических форматах GIF и PNG, поддерживающих сжатие без потерь, а также в стандарте модемной связи v.42 bis).
-Сжатие данных с потерями (алгоритмы, лежащие в основе стандартов JPEG и MPEG).
Необходимо привести схему кодирования и декодирования в архиваторе.

Рис.2. Схема кодирования/декодирования в архиваторе
Компонент кодера «модель» строит распределение вероятностей сообщения, зная некоторые сведения о структуре сообщения (например, алфавит сообщения). Кодер затем исследует возможности полученного распределения вероятностей для построения кодов (в двоичной системе), используя результаты работы модели. Хотя существует много способов описания и построения моделей алгоритмов сжатия, разных по уровню сложности, способ построения кодера довольно простой – существует множество алгоритмов сжатия, основывающихся на алгоритме Хаффмана или алгоритме арифметического кодирования.
Важным вопросом в теории сжатия данных является оценки эффективности работы алгоритма. Для алгоритмов сжатия данных без потерь можно выделить несколько важных критериев: время компрессии, время, затраченное на восстановление исходных данных, размер сжатого сообщения, степень (коэффициент), фактор и качество сжатия. В случае с алгоритмами сжатия данных с потерями также необходимо оценивать степень влияния потерь информации (то есть оценивать отличие между исходными и восстановленными данными). Сначала приведем определения величин степени, фактора и качества сжатия, а затем рассмотрим один из примеров кодирования (использование префиксных кодов).
· Степень (коэффициент сжатия) – отношение размера выходного файла к размеру входного файла. Если значения коэффициента больше единицы, то сжатия не произошло, иначе величина показывает, насколько сжатый файл меньше исходного. Обозначим эту величину символом k. Если значение k =0.6, то можно сказать, что сжатые данные занимают 60% от исходного размера.
· Фактор сжатия (B) – обратное отношение (размера входного файла к размеру выходного файла). Чем больше фактор сжатия, тем эффективнее работает алгоритм.
· Качество сжатия (k1) – k = 100*(1 – k) – показывает, на сколько процентов сжатый файл меньше исходного.
Приведем теперь пример кодирования сообщения, порожденного источником данных с заданным распределением вероятностей. Использование префиксных кодов позволяет построить двоичный код для сообщения и посчитать характеристики полученного кода. Формально запишем определение процесса кодирования.
Определение 1. Пусть E = {0,1}, E* = ![]() – множество всех конечных наборов 0 и 1. Пусть A = {a1, a2, … ,ai, …} – алфавит сообщения. Кодированием называется отображение
– множество всех конечных наборов 0 и 1. Пусть A = {a1, a2, … ,ai, …} – алфавит сообщения. Кодированием называется отображение ![]() .
. ![]() называется кодовым словом или кодом символа ai. Длина кодового слова будет обозначаться L(ai) =
называется кодовым словом или кодом символа ai. Длина кодового слова будет обозначаться L(ai) = ![]() – количество бит в слове. Кодирование
– количество бит в слове. Кодирование ![]() называется дешифруемым, если произвольная последовательность кодовых слов
называется дешифруемым, если произвольная последовательность кодовых слов ![]() , записанных в единой последовательности битов, однозначно разделяется на кодовые слова.
, записанных в единой последовательности битов, однозначно разделяется на кодовые слова.
Определение 2. Кодирование называется префиксным, если никакой код ![]()
![]() не является префиксом (началом) другого кодового слова
не является префиксом (началом) другого кодового слова ![]() .
.
Определение 3. Кодирование называется дешифруемым, если произвольная последовательность кодовых слов ![]() , записанных слитно, однозначно разделяется на кодовые слова.
, записанных слитно, однозначно разделяется на кодовые слова.
Приведем пример. В таблице записаны кодовые последовательности для различных символов. Определить, какой из кодов является префиксным.
Таблица 1. Пример кодов
Символ | Код 1 | Код 2 | Код 3 | Код 4 |
A | 1000 | 10 | 00 | 10 |
B | 10 | 011 | 000 | 00 |
C | 110 | 111 | 111 | 101 |
D | 1 | 110101 | 1111 | 1010 |
Префиксным является второй код, поскольку для данного кода верно определение 2. Алфавит для всех кодов – A = {A, B,C, D}, кодовые последовательности f(ai) = {10, 011, 111, 110101}. Можно построить кодовое дерево:

Рис.3. Кодовое дерево для префиксного кода
Можно привести характеристики кодов, основными будут являться энтропия, средняя длина кода и избыточность. Этими оценками мы будем пользоваться в процессе изучения алгоритмов сжатия данных без потерь.
Энтропия распределения вероятностей F называется следующая величина:
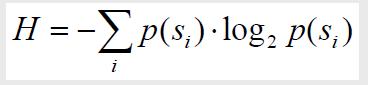
(1)
Оценка работает для алгоритмов сжатия источников данных без памяти (то есть, не учитывающих позиции символов при кодировании – алгоритмы Хаффмана и арифметического кодирования). Энтропия показывает наименьшее в среднем (среднее взвешенное) число бит, необходимых для кодирования поступившего на вход кодера сообщения. Хотя понятие об энтропии было введено раньше, но в аппарат теории информации было введено в 1948 году американским ученым Клодом Шенноном. Кодеры, работа которых основана на подсчете распределения вероятностей, называются энтропийными. Например, если с помощью рассмотренного префиксного кода выполнить кодирование сообщения S = ABBABC, то получим следующую строку (кодирование ![]() : 10 011 011 10 011 110101). Распределение вероятностей символов в этом сообщении p = {2/6, 3/6, 1/6},алфавит – A = {A, B,C}. Энтропия в этом случае равна H = 1.45918 бит/символ. То есть, если использовать такой вариант построения кода для данного сообщения, то мы потратим 1.45918 бит для кодирования предложенной строки. Можно привести код, который осуществляет подсчет энтропии введенной последовательности.
: 10 011 011 10 011 110101). Распределение вероятностей символов в этом сообщении p = {2/6, 3/6, 1/6},алфавит – A = {A, B,C}. Энтропия в этом случае равна H = 1.45918 бит/символ. То есть, если использовать такой вариант построения кода для данного сообщения, то мы потратим 1.45918 бит для кодирования предложенной строки. Можно привести код, который осуществляет подсчет энтропии введенной последовательности.
function [h] = entropy(x)
%Энтропия введенной последовательности
x = double(x);
x = x/sum(x(:)); %подсчет вероятностей символов
i = find(x);
h = -sum(x(i).*log2(x(i)));
end
Функция годится пока только для оценки числовых последовательностей. На практике мы изменим ее для обработки строк.
Также можно привести оценку средней длины кодового слова.![]()
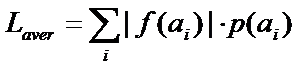
(2)
Измеряется также в бит/символ. Если рассматривать для сообщения, то введенная средняя длина кода рассматриваемого сообщения будет равна:
Laver = 2.667 бит. При подсчете мы также пользуемся распределением вероятности символов алфавита. Третьей важной величиной, использующейся при оценке результатов кодирования, является избыточность. Она рассчитывается как разность между средней длиной кодовых слов и энтропией. R = Laver – H. Результат всегда должен быть положительным. На практическом занятии изучим принцип кодирования по алгоритму Хаффмана; покажем, каким образом используются приведенные величины при сжатии информации. А также рассмотрим свойства структуры данных, использующихся при реализации алгоритма Хаффмана. Далее необходимо пояснить, почему возможно сжатие данных (не только текстовых, но и других типов информации – изображений, видео и звука).
Сжатие текстовых сообщений возможно потому, что большинство сообщений избыточны (например, есть повторы символов), поэтому их можно сжать такими алгоритмами, которые используют префиксные коды либо специализированные структуры данных, в которых учитываются предыдущие появления символов в строке. Это происходит из-за того, что в сообщениях присутствует кодовая избыточность; ее оценка позволяет понять, какие коды мы можем выбрать для эффективного кодирования текстовой информации. Текст представляет собой последовательность символов (одномерный массив), поэтому легче всего поддается обработке. Другое дело, если нам необходимо осуществлять обработку изображений. Сжатие изображений возможно в силу трех причин:
· Большой объем памяти, выделяемый под изображения (до нескольких мегабайт).
· При анализе изображения человеческое зрение работает с переходами цветов, контурами (границами определенных областей), сравнительно нечувствительно к малым изменениям в изображении, например – если в изображении есть область, в которой доминируют оттенки синего цветов (синее небо или вода).
· Изображения обладают избыточностью в двух направлениях (межпиксельная или визуальная избыточность). Соседние пиксели в большинстве случаев, как по горизонтали, так и по вертикали имеют близкие значения. Также можно использовать подобие между красной (R), синей (B) и зеленой (G) составляющей (каналом) изображения.
При разработке алгоритмов сжатии графических изображений мы используем особенности структуры изображения. Например, будет осуществляться хорошее сжатие изображения, если в изображении много полосок (высоких частот в разных направлениях) либо много тонких деталей и наклонных границ в разных направлениях (сжатие с потерями).
Сжатие видео применяется из-за следующих проблем:
· Некоторые данные занимают очень много места
· Каналы передачи и возможности хранения ограничены
Сжатие видеоданных возможно в силу следующих причин:
· Малое локальное изменение цвета
· Избыточность в цветовых плоскостях – яркость является наиболее важной характеристикой для восприятия
· Подобие между кадрами – на скорости 25 кадров в секунду соседние кадры обычно меняются незначительно
Также при сжатии видео устраняется избыточность: пространственная, временная и избыточность цветового пространства (при преобразованиях вносятся потери – кодируются не все пиксели, а только определенные кодировщиком). Если говорить о пространственной избыточности, то подразумевается, что цвет большинства точек одинаков (как и при сжатии изображений). Так как соседние кадры фильма очень похожи, то присутствует и временная избыточность. Сжатие видео необходимо также из-за возможных артефактов – ошибок в кадрах. Например, помехи (шум) и блочность (характерно для веб-камер) и эффекты дрожания кадра, появления мусора, царапин при оцифровке видеокассет.
Сжатие звука можно осуществить за счет анализа данных частотного спектра звуковой волны, применив затем к полученным распределениям базовые алгоритмы. Звук и изображения передаются по системам связи отдельно, затем приемник осуществляет компиляцию сигналов (если происходит передача видеофильмов или проводятся видеоконференции). При сжатии звука используется:
· Частотное маскирование (избыточность по частоте) – если нормально слышимый звук накрывается другим громким звуком с близкой частотой. Тогда нормальный звук маскируется более громким, меньшую частоту можно удалить
· Временное маскирование – громкому звуку частоты f предшествует (или следует за ним) менее громкий звук. Тогда можно удалить менее громкий звук
· Избыточность стерео-сигнала
Приведем вариант схемы алгоритма сжатия звука.

Рис.3. Вариант схемы сжатия звука
Мы рассмотрели основные понятия теории сжатия информации, классификацию алгоритмов сжатия данных, примеры построения префиксного кода и определение его характеристик и кратко перечислили основания для сжатия различных типов информации (текст, графика, видео и звук). На следующем занятии мы начнем изучение алгоритма сжатия Хаффмана. Помимо принципа работы алгоритмов кодирования и декодирования посмотрим способы оценки эффективности кодирования на различных примерах, а также свойства используемой при сжатии структуры данных – бинарного дерева.
