


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 4.1.
Исходная строка | Вывод |
paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb | S PX PaXb PaaXbb PaaaXbbb Paaaxbbb |
4.1. LL(1)-грамматики
Если возможно написать детерминированный анализатор, осуществляющий разбор сверху вниз, для языка, генерируемого s-грамматикой, то такой анализатор принято называть LL(1)-грамматикой.
Определение.
Обозначения в написании LL(1)-грамматики означают:
L – строки разбираются слева направо;
L – используются самые левые выводы;
1 – варианты порождающего правила выбираются с помощью одного предварительного просмотра символа.
Т. е. грамматику называют LL(1)-грамматикой, если для каждого нетерминала, появляющегося в левой части более одного порождающего правила, множество направляющих символов, соответствующих правым частям альтернативных порождающих правил, – непересекающиеся.
Определение.
Множество терминальных символов предшественников определяется следующим образом.
![]() ,
,
где А – нетерминал;
a - строка терминалов и/или нетерминалов;
- множество символов предшественников А.
Пример.
P®Ac P®Bd A®a | A®Aa B®b B®bB |
символы а и b – символы предшественники для Р.
Определение.
Если А – нетерминал, то его направляющими символами (DS) будут +(все символы, следующие за А, если А может генерировать пустую строку).
В общем случае для заданного варианта a и нетерминала Р (P®a) имеем
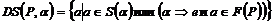 ,
,
где F(P) есть множество символов, которые могут следовать за Р.
Пример.
T®AB A®PQ A®BC P®pP P®e Q®qQ | Q®e B®bB B®d C®cC C®f |
Эта грамматика дает ![]() ,
, ![]() ,
, ![]() и
и ![]() .
.
Из определения LL(1)-грамматики следует, что эти грамматики можно разбирать детерминирован сверху вниз.
Алгоритм. Принадлежит ли данная грамматика LL (1)-грамматике?
Вход. Некоторая произвольная грамматика.
Выход. «ДА» если данная грамматика является LL(1)-грамматикой, «НЕТ» в - противном случае.
Метод.
Прежде всего, нужно установить, какие нетерминалы могут генерировать пустую строку. Для этого создадим одномерный массив, где каждому нетерминалу соответствует один элемент. Любой элемент массива может принимать одно из трех значений: YES, NO, UNDECIDED. Вначале все элементы имеют значение UNDECIDED. Мы будем просматривать грамматику столько раз, сколько потребуется для того, чтобы каждый элемент принял значение YES или NO.
При первом просмотре исключаются все порождающие правила, содержащие терминалы. Если это приведет к исключению всех порождающих правил для какого-либо нетерминала, соответствующему элементу массива присваивается значение NO. Затем для каждого порождающего правила с е в правой части тому элементу массива, который соответствует нетерминалу в левой части, присваивается значение YES, и все порождающие правила для этого нетерминала исключаются из грамматики.
Если требуются дополнительные просмотры (т. е. значения некоторых элементов массива все еще имеют значение UNDECIDED), выполняются следующие действия.
1) Каждое порождающее правило, имеющее такой символ в правой части, который не может генерировать пустую цепочку (о чем свидетельствует значение соответствующего элемента массива), исключается из грамматики. В том случае, когда для нетерминала в левой части исключенного правила не существует других порождающих правил, значение элемента массива, соответствующего этому нетерминалу, устанавливается на NO.
2) Каждый нетерминал в правой части порождающего правила, который может генерировать пустую строку, стирается из правила. В том случае, когда правая часть правила становится пустой, элементу массива, соответствующему нетерминалу в левой части, присваивается значение YES, и все порождающие правила для этого нетерминала исключаются из грамматики.
Этот процесс продолжается до тех пор, пока за полный просмотр грамматики не изменится ни одно из значений элементов массива.
Рассмотрим этот процесс на примере грамматики
1. 2. 3. 4. 5. 6. | A®XYZ X®PQ Y®RS R®TU P®e P®a | 7. 8 9. 10. 11. 12. | Q®aa Q®e S®c T®dd U®ff Z®e |
После первого прохода массив будет таким, как показано в табл.4.2, а грамматика сведется к следующей:
1. 2. 3. 4. | A®XYZ X®PQ Y®RS R®TU |
Таблица 4.2.
A | X | Y | R | P | Q | S | T | U | Z |
U | U | U | U | Y | Y | N | N | N | Y |
U – UNDECIDED (нерешенный)
Y – YES (да)
N – NO (нет)
После второго прохода массив будет таким, как показано в табл.4.3, а грамматика примет вид:
1. | A®XYZ |
Таблица 4.3.
A | X | Y | R | P | Q | S | T | U | Z |
U | Y | N | N | Y | Y | N | N | N | Y |
Третий проход завершает заполнение массива (табл. 4.4).
Таблица 4.4.
A | X | Y | R | P | Q | S | T | U | Z |
N | Y | N | N | Y | Y | N | N | N | Y |
Далее формируется матрица, показывающая всех непосредственных предшественников каждого нетерминала. Этот термин используется для обозначения тех символов, которые из одного порождающего правила уже видны как предшественники. Например, на основании правил
P®QR
Q®qR
можно заключить, что Q есть непосредственный предшественник P, а q – непосредственный предшественник Q. В матрице предшественников для каждого нетерминала отводится строка, а для каждого терминала и нетерминала – столбец. Если нетерминал А, например, имеет в качестве непосредственных предшественников В и С, то в А-ю строку в В-м и С-м столбцах помещаются единицы (табл. 4.5).
Таблица 4.5.
A | B | C | … | Z | a | b | c | … | z | |
A | 1 | 1 | ||||||||
B | ||||||||||
C | ||||||||||
D | ||||||||||
. . . | ||||||||||
Z |
Там, где правая часть правил начинается с нетерминала, необходимо проверить, может ли данный нетерминал генерировать пустую строку, для чего используется массив пустой строки. Если такая генерация возможна, символ, следующий за нетерминалом, является непосредственным предшественником нетерминала в левой части правила и т. д.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
