


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Известно несколько способов описания языков, удовлетворяющих этим требованиям. Один из способов состоит в использовании порождающей системы, называемой грамматикой.
Цепочки языка строятся точно определённым способом с применением правил грамматики. Одно из преимуществ определения языка с помощью грамматики состоит в том, что операции, проводимые в ходе синтаксического анализа и перевода, можно сделать проще, если воспользоваться структурой, которую грамматика приписывает цепочкам (предложениям).
Второй метод описания языка – частичный алгоритм, который для произвольной входной цепочки останавливается и отвечает «да» после конечного числа шагов, если эта цепочка принадлежит языку.
Мы будем представлять частичный алгоритм, определяющий языки, в виде схематизированного устройства, которое будем называть распознавателем.
3.2. Грамматики
Грамматики образуют наиболее важный класс генераторов языка. Грамматика – это математическая система, определяющая вид языка. Одновременно она является устройством, которое придаёт цепочкам (предложениям) языка полезную структуру. Мы будем пользоваться формализмом грамматик Хомского.
В грамматике, определяющей язык L, используются два конечных непересекающихся множества символов – множество нетерминальных символов, которое обычно обозначается буквой N, и множество терминальных символов, обозначаемое å. Из терминальных символов образуются слова (цепочки) определяемого языка. Нетерминальные символы служат для порождения слов языка L определённым способом.
Сердцевину грамматики составляет конечное множество Р правил образования, которое описывает процесс порождения цепочек языка. Правило – это просто пара цепочек или элемент множества, иначе говоря, (NÈå)* N (NÈå)* ´ (NÈå)*. Первой компонентой правила является любая цепочка, содержащая хотя бы один нетерминал, а второй компонентой – любая цепочка.
Пример.
Например, правилом может быть пара (AB, CDE). Если уже установлено, что некоторая цепочка a порождается грамматикой и a содержит AB, т. е. левую часть этого правила, в качестве своей подцепочки, то можно образовать новую цепочку b, заменив одно вхождение AB в a на CDE.
Язык, определяемый грамматикой, - это множество цепочек, которые строятся только из терминальных символов и выводятся, начиная с одной особой цепочки, состоящей из одного выделенного символа, обычно обозначаемого S.
Соглашение. Правило (a, b) будем записывать a®b.
Определение.
Грамматикой называется четвёрка G=(N, Σ, P, S),
где
N – конечное множество нетерминальных символов или нетерминалов (иногда называемых вспомогательными символами, синтаксическими переменными или понятиями);
å - непересекающееся с N конечное множество терминальных символов (терминалов);
P – конечное подмножество множества (NÈå)*N(NÈå)*´(NÈå)* , элемент (a, b) множества P называется правилом (или продукцией) и записывается a®b;
S – выделенный символ из N, называемый начальным (исходным) символом.
Примером грамматики служит четвёрка G1 = ({A, S}, {0, 1}, P, S), где P состоит из правил
S→0A1
0A→00A1
A→e.
Нетерминальными символами являются А и S, а терминальными - 1 и 0.
Грамматика определяет язык рекурсивным образом. Рекурсивность проявляется в задании особого рода цепочек, называемых вводимыми цепочками грамматики G=(N,Σ,P, S), где
1) S - вводимая цепочка;
2) если αβγ – выводимая цепочка и β→d содержится в Р, то adg – тоже выводимая цепочка.
Выводимая цепочка грамматики G, не содержащая нетерминальных символов, называется терминальной цепочкой, порождаемой грамматикой G.
Терминология.
Пусть G=(N, Σ, P, S) – грамматика. Отношение ÞG на множестве (NÈå)* (φÞGΨ означает Ψ, непосредственно выводимая из φ ) и практикуется: если αβγ – цепочка из (NÈå)* и β→δ – правило из Р, то αβγ ÞG αδγ.
Транзитивное замыкание отношения ÞG обозначим через ÞG+ и трактуется – Ψ, выводимая из φ нетривиальным образом.
Рефлексивное и транзитивное замыкание отношения ÞG (ÞG*) φÞG* Ψ, Ψ, выводимая из φ.
Далее, если ясно, о какой грамматике идёт речь, то индекс G будет опускаться.
Таким образом, L(G) = {w | wÎå*,SÞ*w} через ![]() будем обозначать k-ю степень отношения Þ. Иначе говоря a
будем обозначать k-ю степень отношения Þ. Иначе говоря a![]() b, если существует
b, если существует ![]() , состоящая из k+1 цепочек, для которых
, состоящая из k+1 цепочек, для которых ![]() при 1£ i £ к и
при 1£ i £ к и ![]() =b. Эта последовательность цепочек называется выводом длины k цепочки b из цепочки a в грамматике G.
=b. Эта последовательность цепочек называется выводом длины k цепочки b из цепочки a в грамматике G.
Отметим, что aÞ*b тогда и только тогда, когда a![]() b для некоторого i≥0, и aÞ+b тогда и только тогда, когда a
b для некоторого i≥0, и aÞ+b тогда и только тогда, когда a![]() b для некоторого i≥1.
b для некоторого i≥1.
Пример.
Рассмотрим грамматику G1 из ранее приведённого примера
SÞ0A1Þ00A11Þ0011.
На первом шаге S заменяется на А01 в соответствии с правилом S→A01.
На втором шаге 0A заменяется на 00A1.
На третьем шаге A заменяется на e.
Можно сказать, что SÞ30011
SÞ+0011
SÞ*0011,
и что 0011 принадлежит языку L(G1).
Соглашение: a®b1
a®b2
…….
a®bn
обозначим a®b1 ½b2 ½….½bn.
Кроме того, примем ещё следующие соглашения относительно символов и цепочек, связанных с грамматикой:
(1) a, b, c, d и цифры 0,1,2,..,9 обозначают терминальные символы;
(2) A, B, C, D, S обозначают нетерминалы, S – начальный символ;
(3) U, V,...,Z обозначают либо нетерминалы, либо терминалы;
(4) a, b,.. обозначают цепочки, которые могут содержать как терминалы, так и нетерминалы;
(5) u, v,...,z обозначают цепочки, состоящие только из терминалов.
Пример.
Пусть G0 = ({E, T, F},{a, +, * (, )}, P, E), где P состоит из правил:
E→E+T | T
T→T*F | F
F→(E) | a.
Пример вывода в этой грамматике:
EÞE+T
ÞT+T
ÞF+T
Þa+T
Þa+T*F
Þa+F*F
Þa+a*F
Þa+a*a,
т. е. язык G0 представляет собой множество арифметических выражений, построенных из символов a, +, *, (и).
3.3. Грамматики с ограничениями на правила
Грамматики можно классифицировать по виду их правил: пусть G=(N, Σ, P, S) – грамматика.
Определение. Грамматика G называется:
1) праволинейной, если каждое правило из Р имеет вид А®xB или А®x, где А, ВÎN;
2) контекстно-свободной (или бесконтекстной), если каждое правило из Р имеет вид А®a, где АÎN, aÎ (NÈS)*;
3) контекстно-зависимой (или неукорачивающей), если каждое правило из Р имеет вид a®b. |a|£|b|.
Грамматика, не удовлетворяющая ни одному из заданных ограничений, называется грамматикой общего вида (грамматика без ограничений).
Рассмотренный ранее пример – множество арифметических выражений, построенных из символов а + *, является примером контекстно–свободной грамматики.
Заметим, что согласно введённым определениям, каждая праволинейная грамматика – контекстно-свободная грамматика. Контекстно-зависимая грамматика запрещает правило А®е (е – правило).
Соглашение. Если язык L порождается грамматикой типа x, то L называется языком типа x. Это соглашение относится ко всем «типам x».
Определённые нами выше типы грамматик и языков называют иерархией Хомского.
3.4. Распознаватели
Второй распространённый метод, обеспечивающий задание языка конечными средствами, состоит в использовании распознавателей. В сущности, распознаватель – это схематизированный алгоритм, определяющий некоторое множество.
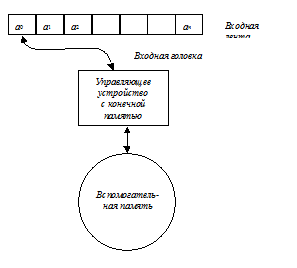
Распознаватель состоит из трёх частей (рис 3.1) - входной ленты, управляющего устройства с конечной памятью и вспомогательной или рабочей, памяти.
Входную ленту можно рассматривать как линейную последовательность клеток, каждая ячейка которой содержит один символ из некоторого конечного входного алфавита. Самую левую и самую правую ячейки обычно занимают (хотя и необязательно) маркеры.
Входная головка в каждый данный момент читает (обозревает) одну входную ячейку. За один шаг работы распознавателя входная головка может двигаться на одну ячейку влево, оставаться неподвижной, либо двигаться на одну ячейку вправо.
Памятью распознавателя может быть любого типа хранилище информации. Предполагается, что алфавит памяти конечен и хранящаяся в памяти информация построена только из символов этого алфавита. Предполагается также, что в любой момент времени можно конечными средствами описать содержимое и структуру памяти, хотя с течением времени память может становиться сколь угодно большой.
Поведение вспомогательной памяти для заданного класса распознавателей можно охарактеризовать с помощью двух функций: функции доступа и функция преобразования памяти.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
