
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Генетические алгоритмы
Автор:
11 А класс, Смоленский Педагогический Лицей.
г. Смоленск, e-mail *****@***ru
История
Теория эволюции Дарвина не могла не подвигнуть программистов на создание систем, действующих по тем же принципам, что и биологические. Сначала это делалось лишь для того, чтобы посмотреть, что получится при моделировании естественной жизни на компьютере, этот раздел программирования развивался и сейчас мы его называем Artificial Life (Искусственная Жизнь). Конкретного применения в данный момент ему не найдено, но в будущем видятся невообразимые высоты.
Но кроме Искусственной жизни существуют другие компьютерно-биологические системы, которые уже сейчас применяются для решения различных задач. К ним можно отнести Генетическое Программирование (Genetic Programming), Эволюционные Стратегии (Evolutionary Strategies), ну и Генетические Алгоритмы (Genetic Algorithms, далее ГА), о которых пойдёт речь в данной статье.
Автор поставил себе цель объяснить читателю, что ГА – это не какие-то заоблачные дали, о которых имеют право говорить только профессора, это вполне применимый метод решения задач, которые становятся на тернистом пути написания программ! Для понятности в ходе статьи мы рассмотрим решение известной задачи о коммивояжере с помощью ГА. Да, её можно решить лишь полным перебором, но ГА и не дают точных решений (обычно ошибаются на 5-10%), зато вполне сносный ответ для двадцати городов наша программа будет выдавать за пару секунд, а стандартному алгоритму придется помучаться, перебирая 20! вариантов.
Теория
Прежде чем приступить к решению нашей задачи, нужно изучить немного теории, поэтому настройтесь на соответствующий лад.
В общих чертах работу ГА можно описать так: он создает популяцию особей, каждая из которых является решением задачи, а затем эти особи эволюционируют по принципу «выживает сильнейший», то есть остаются лишь самые оптимальные решения.
Теперь разберемся поподробнее. Каждую особь описывает хромосома (в нашем случае это будет массив из номеров городов, которые по очереди проходит коммивояжер), хромосома состоит из генов (номера городов), которые располагаются в определенных позициях (локусах) хромосомы. Вообще, в большинстве случаев хромосома представляет собой битовую строку, где каждый бит – ген, но программист волен выбирать ту форму, которая удобнее для решения его задачи. Итак, вся наследственная информация, или генотип, хранится в хромосомах.
Работа ГА имитирует естественную жизнь, только сильно упрощенную. На рис1 представлена блок-схема стандартного ГА. Рассмотрим каждый из операторов ГА:
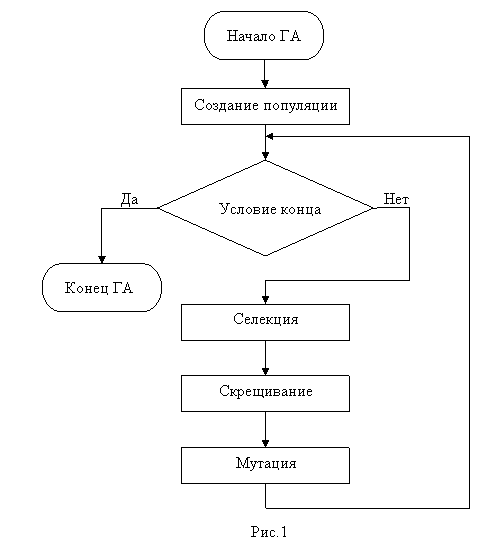 |
1)Создание популяции.
На этом этапе с помощью счетчика случайных чисел мы создаем начальную или стартовую популяцию особей.
2)Селекция.
Здесь алгоритм выбирает особей в следующее поколение. При этом большие шансы имеют более приспособленные (в нашем случае это особи с наименьшей длинной пути коммивояжера).
Существует несколько методов селекции, но наиболее распространен метод рулетки(roulette-wheel selection), которым мы и будем пользоваться. Заключается он в том, что для каждой особи вычисляется функция приспособленности и шансы выжить она получает пропорциональные значению этой функции. То есть колесо рулетки делится на секторы особей, пропорциональные приспособленности, и, запустив рулетку столько раз, сколько у нас особей, мы получаем новое поколение (в него переходят те особи, напротив сектора которых остановился волчок).
Также нельзя не упомянуть о таком методе отбора, как элитизм – при нем самая приспособленная особь всегда переходит в следующее поколение. Элитизм обычно внедряют в другие методы отбора – сохраняют «элитную» особь вне зависимости от других условий селекции.
3)Скрещивание или кроссовер (crossover)
В этой части ГА случайным образом выбираются две особи, которые затем по определенным правилам обмениваются генами.
Самым простым и, в то же время, по мнению автора, самым эффективным, методом скрещивания является одноточечный кроссовер. Он работает так: генерируется случайное натуральное число n, меньшее длины хромосомы, и каждая родительская хромосома делится на две части, первая из которых содержит первые n генов, а вторая – оставшийся генотип. Каждая дочерняя особь состоит из первой части одной родительской особи и второй части другой, то есть родители как бы обмениваются частями. Рис.2 – иллюстрация одноточечного кроссовера для хромосом–битовых строк.
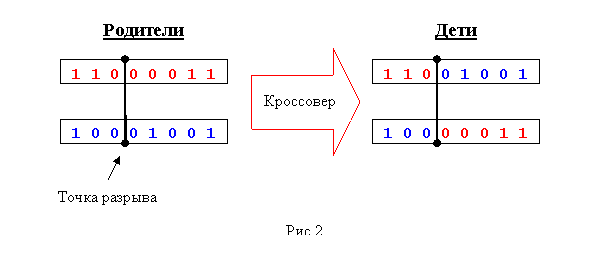

Также довольно распространен двухточечный кроссовер. При нем выбираются две точки разрыва и родители обмениваются участком хромосом между ними. Равномерный кроссовер реализует наследование детьми каждого из генов родителей с заданной вероятностью.
4)Мутация(mutation)
Этот оператор ГА с заданной (обычно очень маленькой) вероятностью случайным образом изменяет случайный ген особи (для битовых строк – инвертирует). Это, пожалуй, простейшая часть ГА, и другие комментарии к ней излишни.
Практика
Ну вот, с основами теории ГА вроде бы разобрались – пора переходить к практике. Для начала четко поставим задачу: коммивояжер решил объехать 20 городов по кратчайшему пути. Он начинает свой путь в любом из них и заканчивает в каком-то другом, при этом ни в одном городе он не должен побывать дважды. Абсолютно все города соединены дорогами и их длины генерируются счетчиком случайных чисел. Нам необходимо за короткое время найти путь, близкий к кратчайшему.
В качестве компилятора будем использовать Borland Delphi. Создаем консольное приложение: File->New->Console Application. Сначала объявим необходимые глобальные константы, типы и переменные:
const n_t=20; //кол-во городов
n_os=50; //кол-во особей
v_mut=1; //вероятность мутации для каждой особи(в %)
v_cross=60;//вероятность скрещивания для каждой пары
//особей(в %)
max=10; //максимальное расстояние между городами
type TTowns=array[1..n_t,1..n_t]of byte;
//массив, описывающий расстояния между городами
TOsobi=array[1..n_os+1,1..n_t]of byte;
//массив хромосом
var towns:TTowns;//переменная городов
i, j,k, p,n:word;//переменные для циклов и т. д. и т. п.
osobi, new_osobi, pr:TOsobi;//переменные особей
c:char;//просто символьная переменная
Некоторые замечания по листингу: towns[i, j] – расстояние между i-м и j-м городом. Естественно, должны выполняться равенства: towns[i, j]=towns[j, i] и towns[i, i]=0 (последнее скорее для приличия – оно нам не понадобится). Для массива особей osobi[i, j] – номер j-го города в пути коммивояжера, описываемого i-й хромосомой. Автор взял (n_os+1)особей для удобства – последнюю не будут касаться скрещивание и мутация, она всегда будет переходить в следующее поколение – это та самая элитная особь. Объявлено три переменных особей для процедуры селекции.
Теперь напишем процедуру, которая, согласно условию, генерирует towns (расстояние между городами от 1 до max включительно):
procedure gen_towns;
begin
for i:=1 to n_t do
begin
for k:=i+1 to n_t do
begin
towns[i, k]:=random(max)+1;
towns[k, i]:=towns[i, k];
end;
towns[i, i]:=0;
end;
end;
Т. к. комментарии к предыдущему листингу излишни, перейдем к процедуре создания популяции, она немного посложнее, все пояснения приведены прямо в листинге:
procedure gen_pop;
begin
for i:=1 to n_os+1 do
begin
//заполняем особь городами 1,2,3...20
for k:=1 to n_t do osobi[i, k]:=k;
{меняем местами первый ген и случайный,
затем второй и другой случайный и т. д.
В результате каждый город встретится в
хромосоме лишь один раз}
for k:=1 to n_t do
begin
j:=osobi[i, k];
p:=random(n_t)+1;
osobi[i, k]:=osobi[i, p];
osobi[i, p]:=j;
end;
end;
end;
Теперь дошла очередь до оператора селекции, это самая сложная процедура в нашей программе, так что сконцентрируйтесь:
procedure selection;
var best:byte;//номер лучшей особи
prisp:array[0..n_os+1]of word;
//массив приспособленностей особей
begin
prisp[0]:=0;
p:=200;
best:=0;
//цикл заполнения массива prisp
for i:=1 to n_os+1 do
begin
j:=0;
for k:=2 to n_t do
j:=j+towns[osobi[i, k-1],osobi[i, k]];
prisp[i]:=prisp[i-1]+10000 div j;
if p>j then begin
p:=j;
best:=i;
end;
end;
//копирование лучшей особи на (n_os+1)-е элитное место
for i:=1 to n_t do new_osobi[n_os+1,i]:=osobi[best, i];
//реализация рулетки
for i:=1 to n_os do
begin
j:=random(prisp[n_os]);
for k:=1 to n_os do
if prisp[k]>j then
begin
j:=k;
break;
end;
for k:=1 to n_t do new_osobi[i, k]:=osobi[j, k];
end;
//обмен переменных osobi и new_osobi через pr
pr:=osobi;
osobi:=new_osobi;
new_osobi:=pr;
//выводим наименьший путь для каждого 250-го поколения
//n-счетчик поколений (в основной функции)
if n mod 250=0 then writeln(p);
end;
Разберем этот листинг. Сначала обнуляем переменные best и prisp[0] – последняя служит лишь для простой организации цикла. Переменной p, в которой будет храниться кратчайший путь присваиваем значение 200, которое больше максимального.
Далее в цикле для каждой особи вычисляем длину пути j, если она меньшая из вычисленных до этого, присваиваем p ее значение. Массив prisp заполняем так: prisp[n]=prisp[n-1]+f(n) ,где f(n) – функция приспособленности особи (чем больше приспособленность, тем больше f(n)). Т. к. мы решаем задачу минимизации, то приходится брать f(n)=10000 div j. Зачем массив prisp заполняется именно так, Вы узнаете чуть позже, а пока заметьте, что «элитная» особь тоже участвует в вычислении приспособленности – а вдруг найдется особь с меньшей длиной пути.
В следующем цикле мы просто копируем лучшую особь на (n_os+1)-е место и больше не трогаем ее до следующего вычисления приспособленностей.
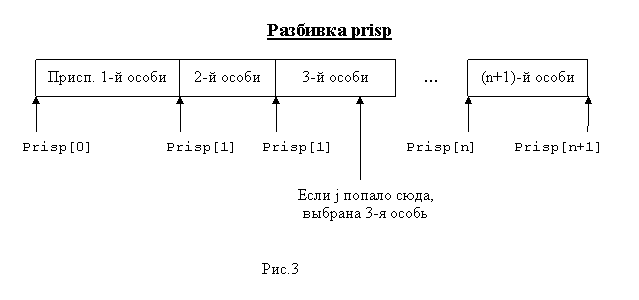

Массив prisp как бы разбивает множество целых неотрицательных чисел, меньших prisp[n_os], на промежутки особей, длина каждого из которых – это приспособленность особи, то есть мы «размечаем» ту самую рулетку(см. рис.3). С помощью функции random генерируем 0≤j<prisp[n_os] – место, на котором остановилось колесо рулетки, а затем ищем, в каком полуинтервале содержится j, то есть напротив какого сектора остановилась рулетка. Особь, соответствующая этому полуинтервалу-сектору, переходит в следующее поколение. Так проводим n_os запусков рулетки.
В последней части процедуры мы просто меняем старое(osobi) и новое(new_osobi) поколения через переменную pr.
Теперь пора подумать об алгоритме скрещивания. Стандартный одноточечный кроссовер не подойдет – в хромосомах потомков один город может встретиться два раза, а другой – ни разу, поэтому придется придумывать что-то свое. Автор разработал алгоритм на базе одноточечного кроссовера, но сохраняющий состав городов, его мы и применим.
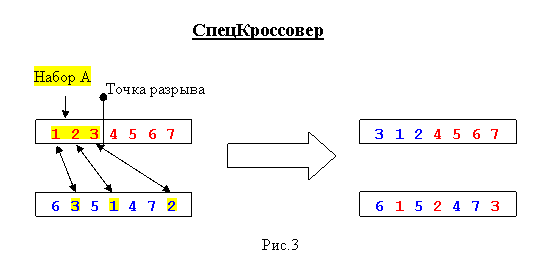

Сначала мы делим первую родительскую хромосому точкой разрыва на две части, длина каждой из которых не меньше двух. Назовем набор генов из первой части А. Теперь начинаем искать во второй родительской хромосоме гены (то есть номера городов) из набора А. Первый найденный меняем местами с первым геном первой хромосомы, второй – со вторым и так далее. Чтобы стало понятнее, взгляните на рис.4, он неплохо иллюстрирует данный алгоритм. Конечно, лучше было бы опираться на двухточечный кроссовер – «отщеплять» произвольную часть хромосомы, а не обязательно лежащую у левого края, но, цель примера к статье – понятность, а не эффективность.
Итак, пишем процедуру:
procedure crossover;
var prom:array[1..n_t]of byte;
//промежуточный массив для записи генов
u:integer;//счетчик для prom
begin
for i:=1 to n_os div 2 do
//решаем, призводить ли скрещивание
if random(100)<v_cross then
begin
//устанавливаем точку разрыва
p:=random(n_t-2)+2;
//устанавливаем счетчик для prom
u:=1;
//сканирование «второй» хромосомы
for k:=1 to n_t do
//проверяем, содержится ли k-й ген в А
for j:=1 to p do
//если ген содержится в наборе А
if osobi[i*2-1,k]=osobi[i*2,j] then
begin
//копируем его в prom
prom[u]:=osobi[i*2-1,k];
//на его место - ген из набора А
osobi[i*2-1,k]:=osobi[i*2,u];
//увеличиваем счетчик для prom на 1
inc(u);
//выходим из цикла по j
break;
end;
//заменяем гены набора А на гены из prom
for j:=1 to p do osobi[i*2,j]:=prom[j];
end;
end;
Эта процедура полностью реализует описанный выше алгоритм. Т. к. особи в следующее поколение переходят в произвольном порядке, не зависящем от их порядка в предыдущем поколении, то автор позволил себе скрещивать не особи с произвольными номерами, а первую со второй, третью с четвертой и так далее.
Для каждой такой пары вероятность скрещивания v_cross и мы решаем, производить ли скрещивание, с помощью функции random. Если бы мы меняли гены сразу же, как это описано выше, набор генов А не сохранился бы и процедура работала бы некорректно, поэтому гены, предназначенные для записи в «первую» хромосому, мы пишем в промежуточный массив prom, а после завершения сканирования «второй» хромосомы переписываем из prom в «первую».
Перейдем к созданию процедуры мутации. Здесь, как и при скрещивании, возникают сложности из-за того, что в каждой особи каждый город должен встречаться один, и только один раз, а если произвольно изменить какой-то ген это условие нарушится. Однако преодолеть эту загвоздку легко: будем менять местами два произвольных гена в хромосоме! Этот оператор самый простой в нашей программе, думаю, что разобраться с листингом вам будет не сложно:
procedure mut;
var b:byte;//переменная, через которую
//будем производить обмен
begin
//перебираем всех особей
for i:=1 to n_os do
//решаем, производить ли мутацию
if random(100)<v_mut then
begin
//k-номер первого произвольного гена
k:=random(n_t)+1;
//j-номер второго
j:=random(n_t)+1;
//обмен
b:=osobi[i, k];
osobi[i, k]:=osobi[i, j];
osobi[i, j]:=b;
end;
end;
Итак, нам осталось написать основную функцию программы, а после проделанной работы это пара пустяков:
begin
//инициализируем счетчик случайных чисел
randomize;
//генерируем города
gen_towns;
//генерируем начальную популяцию
gen_pop;
//запускаем 5000 поколений
for n:=0 to 5000 do
begin
//селекция
selection;
//кроссовер
crossover;
//и мутация
mut;
end;
read(c);
end.
Ну что ж, Ваша первая программа на основе ГА создана, поздравляю! Теперь можно ее протестировать. Запустим ее несколько раз и проследим за выдаваемыми результатами.
Во-первых, значение наименьшего пути в самом первом поколении сильно отличается от этого же значения в 250-м. Это еще раз доказывает, как быстро работают ГА.
Во - вторых, конечный результат выдается через пару секунд. Попытаемся оценить его точность. Обычно он лежит в границах от 30 до 40, иногда выходит из них в ту или другую сторону, и это при том, что наименьшее возможное значение длины пути 19, а наибольшее 190!!! Думаю, очевидно, что, если ответ не точный, то уж точно близок к нему. На этом примере работа ГА просто потрясает!
Ну а чтоб она потрясала еще больше, оценим время, за которое с данной задачей справился бы точный алгоритм перебора всех вариантов. Предположим, что в компьютере гигагерцовый процессор, который проводит необходимые вычисления для каждого варианта за 1 такт (не слабая абстракция). Всего вариантов 20! вариантов, значит суперпроцессору понадобится 20!/1.000.000.000 секунд, а чтобы перевести время в года нужно число секунд разделить на (60*60*24*365). Запускаем MS Калькулятор и получаем примерно 77 лет. Думаю, комментарии излишни.
Снова теория
В этой главе автор попытается вкратце ответить на вопрос «А почему это работает?» Те, кто не очень любит чистую математику, могут сразу переходить к рекомендациям по использованию.
Одним из базовых понятий теории ГА является шима (schema). Шима – это шаблон для хромосом, от которых она отличается лишь тем, что в ее локусах (позициях, если кто не помнит) могут стоять не только гены, но и *-ки (неопределенные гены). Если в качестве примера хромосом рассматривать битовые строки длины 5, то шимы могут быть такими: **10*1, **110, 1***0 и так далее.
У каждой шимы есть два важных параметра: порядок и определенная длина. Порядок – это количество определенных генов в шиме, а определенная длина – расстояние между крайними значащими генами. Например, шима *1*00 имеет порядок 3 и определенную длину 4.
«Ну и зачем нужны эти шимы?» - спросите Вы. А затем, что ГА обрабатывают вовсе не хромосомы, а шимы – неявно, и именно в это кроется секрет работы ГА. Из поколения в поколение переходят только лучшие шимы, которые называют строящими блоками.
Строящие блоки – это шимы, обладающие тремя признаками:
1. Высокая приспособленность (вычисляется как среднее приспособленностей задаваемых шимой хромосом)
2. Низкий порядок
3. Короткая определенная длина
Первый признак позволяет пройти селекцию (чем выше приспособленность, тем больше шансы выжить), второй – мутацию (меньше значащих генов – меньше вероятность их изменения), третий – кроссовер (меньше определенная длина – меньше вероятность того, что точка разрыва попадет между значащими генами и уничтожит шиму).
Рассмотрим простой ГА, он выполняет селекцию пропорционально приспособленности, скрещивание одноточечным кроссовером и мутацию случайным изменением случайного гена. Для такого ГА справедливо утверждение: он экспоненциально увеличивает число строящих блоков. Доказательством этого является теорема шим.
Пусть шима X имеет в k-м поколении n(X, k) представителей или примеров. Нужно оценить значение n(X, k+1). Так как у простого ГА вероятность выживания особи пропорциональна ее приспособленности, то ожидаемое число представителей X после селекции n(X, k)*(prisp(X)/prispср), где prispср – средняя приспособленность всех членов популяции, а prisp(X) – тех, что являются представителями X.
Вероятность успешного прохода через кроссовер не меньше, чем вероятность того, что точка разрыва попадет между значащими генами, то есть 1-v_cross*(d(X)/(l-1)), где d(X) – определенная длина шимы, а l – длина хромосомы. «Не меньше» здесь потому, что в скрещивании могут участвовать два примера одной шимы, и тогда она сохранится. В поздних поколениях, кстати, так происходит довольно часто.
Вероятность того, что мутация не изменит значащего гена (1-v_mut)p(X), p(X) – порядок шимы. Тогда вероятность сохранения шимы после прохода ее представителя через скрещивание и мутацию не меньше (1-v_cross*(d(X)/(l-1)))* (1-v_mut)p(X),но так как p(X) и v_mut малы, то это приближенно 1-v_cross*(d(X)/(l-1))-v_mut*p(X), и тогда для n(X, k+1) получим:
n(X, k+1)≥n(X, k)*(prisp(X)/prispср)*(1-v_cross*(d(X)/(l-1))-v_mut*p(X)))
Это утверждение и называют теоремой шим.
Это теорема довольно проста, однако, не смотря на это, она дает понятие о том, как работает простой ГА, да и просто ГА. Из формулы видно, что число примеров строящих блоков растет из поколения в поколение по экспоненте, в то время как число представителей «бесполезных» шим убывает по экспоненте.
Из сказанного в этой главе можно сделать важный практический вывод: если увеличить v_cross и v_ mut, то популяция быстрее сойдется к результату, но не все строящие блоки будут использованы, поэтому результат может оказаться лишь локальным экстремумом. Если же уменьшить v_cross и v_ mut, то результат будет искаться медленнее, но будет более близок к точному.
Рекомендации по использованию
ГА показывают себя с лучшей стороны при решении далеко не всех задач, и в этой главе пойдет речь о том, когда же следует применять ГА. Четкий ответ на этот вопрос не найден, да и вряд ли может быть найден, ведь задачи столь разнообразны, поэтому здесь будут приведены лишь общие рекомендации.
Наибольшее применение ГА нашли в задачах оптимизации многопараметрических функций, множество решений которых столь велико, что его нельзя перебрать. Для этого случая можно сделать решение универсальным и полученный алгоритм сможет с одинаковым успехом решать чисто математические задачи и проектировать железнодорожный мост! Также здесь используется то, что ГА оптимизирует сразу все параметры, а не по отдельности.
Так как ГА работают с популяцией решений, а не с одним в каждый момент, то они имеют меньше шансов сойтись на локальном экстремуме и выдать его в качестве ответа. Поэтому если функция приспособленности с шумами, то ГА – один из самых оптимальных методов решения задачи.
Ну а теперь о грустном – о том, когда ГА работают не очень эффективно. Если пространство поиска не очень большое, его лучше перебрать, даже если на это потребуется несколько большее время, чем на выполнение ГА, зато вы будете на сто процентов знать, что найденное решение абсолютно точное.
Если существует какой-то специальный для данной задачи метод, учитывающий специфические свойства пространства поиска, то он почти наверняка будет работать лучше, чем ГА. Поэтому придется либо совсем отказаться от применения ГА, либо «скрестить» его со специальным методом, что мы, кстати, и сделали при решении задачи-примера к статье. Вряд ли наша программа показывала бы такие результаты, если бы не учитывала тот факт, что каждый город в пути коммивояжера должен встречаться ровно один раз.
Конечно, сказанное выше не является строгим правилом, но, возможно, это однажды подскажет Вам: «Здесь нужно применить ГА!», и, одновременно, не позволит «совать их во все дырки». Если Вы заинтересовались этой темой, посетите следующие ссылки:
1. http://www. chat. ru/~saisa – один из лучших русских ресурсов о ГА. Есть серьезные научные статьи. Множество ссылок, правда, на англоязычные сайты.
2. http://www. genetic-programming. org – пожалуй, самый известный в мире ресурс по ГА и им подобным. Море информации, но, конечно, все на английском.
