

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ДОВЕРИТ(альфа; станд. откл; размер)
Здесь альфа – допустимая вероятность ошибки, т. н. уровень значимости: a=1-g;
станд. откл. – генералное среднее квадратическое отклонение, предполагающееся известным, или его оценка ![]() ; размер – текущий объем выборки n.
; размер – текущий объем выборки n.
При помощи формулы предельной ошибки выборки решают следующие задачи:
· Определение доверительного интервала с заданной доверительной вероятностью g для генерального среднего ![]() :
: 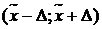 . При этом
. При этом ![]()
· Определение доверительного интервала с заданной доверительной вероятностью g для генеральной доли р: 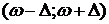
· Определение необходимого объема выборки n для определения доверительного интервала с заданной точностью D и заданной доверительной вероятностью g. Формулы объема выборки приведены в таблице:
Таблица 2.3. Расчет необходимого объема выборки
Повторный отбор (или n<<N, или N=¥) | Бесповторный отбор | |
Для генеральной средней |
|
|
Для генеральной доли |
|
|
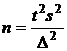
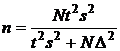
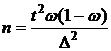
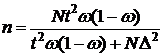
В случае малой выборки (n<30) при отсутствии данных о нормальности распределения признака предельная ошибка для генеральной средней определяется по формуле:
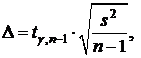
![]() - табличное значение критерия Стьюдента для вероятности g при числе степеней свободы n-1. В Excel коэффициент доверия для малой выборки рассчитывается при помощи функции СТЬЮДРАСПОБР(вероятность;степени свободы), где за аргумент вероятность принимается уровень значимости a=1-g.
- табличное значение критерия Стьюдента для вероятности g при числе степеней свободы n-1. В Excel коэффициент доверия для малой выборки рассчитывается при помощи функции СТЬЮДРАСПОБР(вероятность;степени свободы), где за аргумент вероятность принимается уровень значимости a=1-g.
Для 30<n<100 причисление выборки к категории «большой» или «малой» индивидуально, зависит от постановки задачи и от дисперсии выборки. Четкой границы между большой и малой выборками в общем случае указать невозможно. Выборка, сделанная из совокупности с небольшим разбросом признака, может считаться большой, тогда как выборка такого же объема, произведенная из более разнородной совокупности, окажется малой.
Пример 2.1.
Имеются данные по уровню безработицы в России в 2006 году:
Центральный фед. окр. | 4,5 | Респ. Мордовия | 4,7 | Респ. Хакасия | 9,1 | ||
4,1 | 5,9 | Респ. Татарстан | 5,6 | 8,8 | |||
5,6 | 6,7 | Удмуртская респ. | 8,4 | 9,9 | |||
6,8 | 5,5 | Чувашская респ. | 8,6 | Таймырский АО | 10,0 | ||
10,9 | 7,4 | Пермский край | 6,9 | Эвенкийский АО | 3,9 | ||
5,5 | Г. Санкт-Петербург | 2,4 | 7,9 | 8,9 | |||
4,2 | Южный фед. округ | 5,3 | Усть-Ордынский АО | 12,6 | |||
5,6 | Респ. Адыгея | 13,7 | 6,5 | 7,3 | |||
5,0 | Респ. Дагестан | 22,3 | 6,5 | 7,4 | |||
7,3 | Респ. Ингушетия | 58,5 | 4,3 | 9,3 | |||
4,9 | Кабардино-балк. респ. | 20,7 | 8,2 | 9 | |||
3,0 | Респ. Калмыкия | 16,7 | 6,9 | Агинский АО | 0,9 | ||
6,0 | Карачаево-Черк. респ. | 19,4 | Уральский фед. округ | Дальневост. фед. округ | |||
5,2 | Респ. Сев. Осетия | 8,5 | 12,4 | Респ. Саха | 9,5 | ||
8,0 | Чеченская респ. | 66,9 | 7,0 | 8,0 | |||
8,7 | 7,4 | 6,8 | 6,0 | ||||
4,5 | Ставроп. край | 8,9 | Ханты-Манс. АО | 6,1 | 8,2 | ||
2,7 | 7,9 | Ямало-НенецкийАО | 5,4 | 9,1 | |||
Г. Москва | 3,0 | 8,6 | 5,1 | Корякский АО | 6,4 | ||
Северо-зап. фед. округ | 8,0 | Сибирский фед. окр | 5,4 | ||||
Респ. Карелия | 3,6 | Приволжский фед. окр | Респ. Алтай | 11,6 | Сахалинская обл. | 4,6 | |
Респ. Коми | 12,4 | Респ. Башкортостан | 6,5 | Респ. Бурятия | 13,4 | Еврейская АО | 9,8 |
Архангельская обл. | 5,9 | Респ. Марий Эл | 10,2 | Респ. Тыва | 20,5 | 3,7 | |
5,6 |
Определить доверительный интервал с надежностью 0,9 для средней безработицы: 1)считая выборку большой; 2) считая выборку малой
Решение.
1) Откроем таблицы Excel. Внесем выборочные данные по всем округам в столбец А (диапазон А2:А87). В ячейках D2:D5 вычислим характеристики выборки: объем выборки n (функция СЧЁТ), среднее значение х ср (функция СРЗНАЧ), выборочную дисперсию s2 (функция ДИСПР), исправленную выборочную дисперсию s2испр (функция ДИСП). Внесем также значение доверительной вероятности Р=0,9
Поскольку объем генеральной совокупности неизвестен, а выборка считается большой, мы должны использовать формулу стандартной ошибки для среднего большой выборки с повторным отбором. Однако в этом случае проще сразу вычислить предельную ошибку при помощи функции ДОВЕРИТ:
Рисунок 2.1. Пример. Расчет предельной ошибки среднего большой выборки

Полученное значение D=1,63835. Таким образом, доверительный интервал для среднего уровня безработицы 9,08±1,64.
2) Применим теперь формулу ошибки для малой выборки. Вычислим коэффициент доверия t, введя в ячейку G8 формулу
=СТЬЮДРАСПОБР(1-D6;D2-1).
Предельную ошибку вычисляем в ячейке G9:
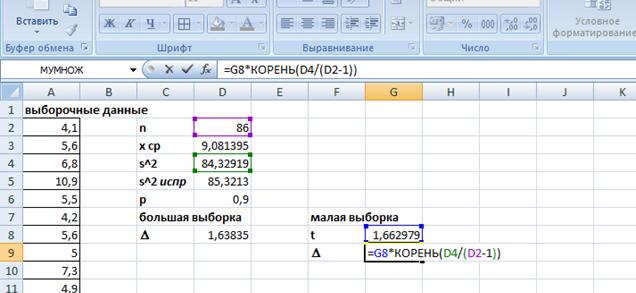
Полученное значение D=1,656403. Таким образом, доверительный интервал для среднего уровня безработицы 9,08±1,656.
Видим, что предельная ошибка, вычисленная по формуле для малой выборки несколько больше, чем по формуле для большой выборки, но различие в данном случае невелико. С ростом объема выборки это различие уменьшается.
Задание 2
1. Рассчитать таблицы:
- доверительных вероятностей по коэффициентам доверия 1; 1,5; 2; 2,5; 3; 3,5 для большой выборки
- коэффициентов доверия для доверительных вероятностей 0,9 и 0,95 для малых выборок объемом 20-30 единиц
2. Найти необходимый объем выборки для определения среднего уровня безработицы в России с точностью, рассчитанной в примере, и с доверительной вероятностью 0,99
Лабораторная работа №3. Проверка статистических гипотез.
Решение многих практических (геологических, экологических и т. п.) задач основано на принципе аналогии, когда для объяснения особенностей строения слабо изученных объектов используют закономерности, установленные при изучении аналогичных объектов. Для правильного выбора объекта-аналога необходимо оценить степень его сходства с исследуемым объектом.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
