

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Масштабируемость и производительность становятся еще более важными факторами, если потребности бинеса не терпят никаких простоев.
Без подходящей технологии системы требуют промежуточного хранения практически на каждом этапе процесса размещения данных в хранилище и интеграции. Поскольку в процесс выборки, преобразования и загрузки (Extract, Transform, and Load — ETL) нужно включать разные (особенно нестандартные) источники данных и над данными приходится выполнять более сложные операции (например «просеивание» данных и анализ текста), потребность в промежуточном хранении возрастает. Как показано на рис. 1, с увеличением точек промежуточного хранения растет и время, затрачиваемое на «закрытие цикла» (например, для анализа и выполнения действий над новыми данными). Такие традиционные ETL-архитектуры (в противоположность более совершенным ETL-процессам, выполняемым до загрузки) жестко ограничивают способность систем реагировать на новые требования бизнеса.

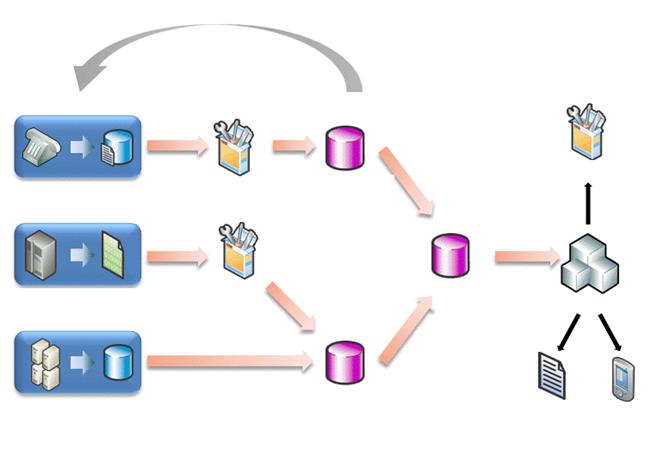
Рис. 1
Наконец, способ увязки интеграции данных с общей архитектурой интеграции в организации становится еще важнее, когда для решения бизнес-задач нужна как интеграция приложений с технологией выполнения транзакций в реальном времени, так и технология интеграции данных, ориенированная на пакетную обработку огромных объемов информации.
Организационные проблемы
При интеграции данных в крупных организациях сталкиваются с двумя основательными проблемами: «эффективности» («power») и «комфортной зоны» («comfort zone»).
Проблема эффективности
Данные — источник эффективности, но обычно очень трудно убедить людей думать о данных в терминах по-настоящему ценных общих активов компании. Чтобы интеграция данных на предприятии была успешной, все владельцы разнообразных источников данных должны согласиться с целями и направлением проекта. Недостаточная координация участвующих сторон — одна из основных причин провала проектов по интеграции данных. Содействие со стороны руководителей, достижение консенсуса и сильная группа, отвечающая за интеграцию данных и состоящая из множества заинтересованных лиц, — вот лишь некоторые из критически важных факторов, которые помогают добиться успеха в решении проблем.
Проблема комфортной зоны
Вы можете справиться с проблемами интеграции данных, если анализировать их в контексте какого-либо одного требования, несколькими способами. Кодирование вручную решает примерно 60% задачи интеграции данных. Технологии, применяемые для решения аналогичных проблем, могут варьироваться от репликации, ETL, SQL до Enterprise Application Integration (EAI). Люди тяготеют к той технологии, с которой они знакомы. Хотя возможности этих подходов перекрываются и способны дать нужный результат в изолированных случаях, такие технологии оптимизируются для решения разных наборов проблем. Попытка справиться с задачей интеграции данных на предприятии в отсутствие здравой архитектуры вкупе с неправильно выбранной технологией обречена на неудачу.
Экономические проблемы
Организационные и технологические проблемы, кратко обрисованные в предыдущих разделах, приводят к тому, что интеграция данных становится самой дорогостоящей частью любого проекта по бизнес-анализу или информационному хранилищу. Основные факторы, вносящие свой вклад в удорожание интеграции данных:
• получение данных в формате, необходимом для интеграции, в итоге превращается в медленный и мучительный процесс, осложняемый играми в перетягивание одеяла между подразделениями организации;
• очистка и преобразование данных, получаемых из множества источников, в нужный формат — задачи крайне трудные;
• нередко стандартные средства интеграции данных не обеспечивают достаточную функциональность или расширяемость, которая удовлетворяла бы требованиям проекта, относящимся к преобразованию данных. Это может привести к расходованию значительных денежных сумм на консалтинговые услуги с целью последующей разработки специального ETL-кода для выполнения нужной работы;
• в разных подразделениях организации свой взгляд на проблему интеграции данных.
Когда возникает необходимость объединить все воедино, приходится тратить дополнительные средства на интеграцию усилий разных подразделений в единую для всего предприятия архитектуру интеграции данных.
С появлением потребностей в бизнес-анализе и создании информационных хранилищ значительно усложняется поддержка неправильно выбранной архитектуры интеграции данных, и показатель совокупной стоимости владения подскакивает до небес.
Службы интеграции SQL Server 2008
Традиционный ETL-ориенированный способ интеграции данных из стандартных источников по-прежнему лежит в основе большинства информационных хранилищ. Однако потребность во включении большего числа разнообразных источников данных, новое законодательство, глобальные и онлайновые операции быстро трансформируют традиционные требования к интеграции данных. На фоне этого быстро меняющегося ландшафта потребность в извлечении выгоды из собранных данных и их достоверности обострилась как никогда раньше. Эффективная интеграция данных стала основой эффективного процесса принятия решений. Службы интеграции SQL Server (SQL Server Integration Services, SSIS) предоставляют гибкую и масштабируемую архитектуру, обеспечивающую эффективную интеграцию данных в современных бизнес-средах.
В этой статье мы обсудим, почему службы интеграции SQL Server являются эффективным набором инструментов как для традиционных ETL-операций, так и для универсальной интеграции данных, потребность в которой постоянно растет. Мы также рассмотрим, чем SSIS фундаментально отличаются от других инструментов и решений, предлагаемых основными поставщиками ETL, и как эти отличия идеально удовлетворяют меняющимся потребностям глобального бизнеса, будь то крупная компания или малое предприятие.
Архитектура SSIS
Ядро поддержки потока задач и потока данных
SSIS состоит из ядра поддержки потока задач, ориентированных на операции, и масштабируемого и быстрого ядра поддержки потока данных. Поток данных существует в контексте общего потока задач. Первое ядро предоставляет ресурсы и поддержку операций для второго ядра. Такое сочетание потоков задач и данных обеспечивает эффективность SSIS как в традиционных решениях ETL или информационных хранилищ, так и во многих, более сложных ситуациях, например при поддержке операций в центрах обработки данных. В этой статье мы сосредоточимся в основном на примерах, имеющих отношение к потокам данных. Применение SSIS для поддержки рабочего процесса, ориентированного на центр обработки данных, само является отдельной темой.
Архитектура конвейера
В основе SSIS лежит конвейер преобразования данных. Архитектура конвейера поддерживает буферизацию, что позволяет этому конвейеру работать чрезвычайно быстро при манипуляциях над наборами данных после их загрузки в память. Суть подхода в выполнении всех этапов ETL-процесса преобразования данных в рамках одной операции без промежуточного хранения данных, хотя специфические требования к преобразованию, операциям или оборудованию могут стать помехой при реализации этого подхода. Тем не менее для максимальной производительности в архитектуре сделано все, чтобы уйти от промежуточного хранения данных. SSIS по возможности даже избегают копирования данных в памяти. Это принципиально отличается от традиционных ETL-средств, которые зачастую требуют промежуточного хранения данных почти на каждом этапе процесса обработки и интеграции данных. Поддержка манипуляций над данными без промежуточного хранения выходит далеко за рамки возможностей традиционных ETL-средств преобразования, а также поддержки реляционных и плоских данных. С помощью SSIS все типы данных (структурированные, неструктурированные, XML и т. д.) перед загрузкой в свои буферы преобразуются в табличную структуру (столбцы и строки). Любую операцию, возможную над табличными данными, допускается выполнять на любой стадии конвейера потока данных. Это означает, что единственный конвейер способен интегрировать разнообразные источники данных и выполнять над этими данными операции произвольной сложности без промежуточного хранения.
Однако, если промежуточное хранение необходимо по эксплуатационными причинам или бизнес-требованиям, SSIS предоставляет хорошую поддержку и для таких реализаций.
Эта архитектура позволяет использовать SSIS в самых разных сценариях интеграции данных — от традиционных ETL-решений до нетрадиционных технологий интеграции информации.
Поддержка подключений через
Важный аспект решения на основе служб интеграции — выборка или загрузка данных. А значит, важно, чтобы такое решение можно было бы без проблем подключать к широкому спектру источников данных; это позволит добиться максимальной производительности и надежности, обеспечиваемой комплексной платформой доступа к данным. Службы интеграции SQL Server 2008 оптимизировано для подключений через (предыдущие версии были оптимизированы для OLE DB или ODBC). Переход на упрощает интеграцию систем и поддержку третьими сторонами. Службы интеграции SQL Server 2005 использовали OLE DB для выполнения таких важных задач, как операции поиска (lookups), но теперь для любых задач, связанных с доступом к данным, можно применять .
Поддержка пула потоков
По мере масштабирования интеграционного решения зачастую производительность растет лишь до определенного предела, а потом выходит на плато, преодолеть которое очень трудно. Службы интеграции SQL Server 2008 снимают это ограничение за счет совместного использования потоков (threads) множеством компонентов, что увеличивает степень распараллеливания и уменьшает частоту блокирования; это способствует повышению производительности в крупномасштабных системах с высокой степенью распараллеливания на основе многопроцессорных и многоядерных аппаратных платформ.
Поддержка пула потоков не только повышает производительность большинства систем, но и сокращает потребность в ручной настройке SSIS-пакетов, что в свою очередь способствует увеличению параллелизма и эффективности труда разработчиков.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
