

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Кеширование данных при операциях поиска
Поиск — одна из самых распространенных операций в интеграционном решении. Такие операции выполняются особенно часто в информационных хранилищах, поиск данных применяется при преобразовании бизнес-ключей в соответствующие суррогаты (заменители). Службы интеграции SQL Server 2008 ускоряют операции поиска и позволяют эффективно выполнять их даже в самых больших таблицах.
Вы можете настроить преобразования поиска на кеширование некоторых или всех справочных данных до обработки входного столбца. Службы интеграции SQL Server 2008 позволяют загружать полный кеш из любого источника, а размер кеша может превышать 4 Гб даже в 32-разрядной операционной системе. Используя частичный кеш, службы интеграции SQL Server 2008 заранее загружают данные, необходимые для поиска. Частичный кеш поддерживает OLEDB, и ODBC для поиска в базах данных, и отслеживает попадания и промахи в процессе поиска. В случае отказа от предварительного кеширования справочных данных службы интеграции SQL Server 2008 поддерживают пакетные обращения к базе данных и поиск совпадений с игнорированием регистра букв.
Варианты интеграции
Применение SSIS для передачи данных
Хотя службы интеграции SQL Server 2005 были гораздо более функциональным и эффективным продуктом, чем предыдущие версии, многие пользователи находили, что простые операции передачи данных, выполняемые с применением мастера, излишне усложнялись, а ряд настроек был недоступен. В службы интеграции SQL Server 2008 включен усовершенствованный мастер, работающий с , пользовательский интерфейс улучшен; кроме того, эти службы умеют выполнять автоматическое преобразование типов данных и обладают более высокой масштабируемостью по сравнению с предыдущими версиями.
Рис. 2
Применение SSIS для загрузки данных в информационное хранилище
В своей основе SSIS — комплексный полнофункциональный ETL-инструмент. Функционалньость, масштабируемость и производительность этих служб очень выгодно отличается от аналогичных конкурирующих продуктов при значительно меньшей стоимости. Конвейерная архитектура позволяет SSIS получать данные из множества источников одновременно, выполнять несколько сложных преобразований, а затем передавать данные нескольким приемникам параллельно. Эта архитектура дает возможность применять SSIS не только для больших наборов данных, но и для множественных потоков данных. Когда данные передаются из источника (источников) приемнику (приемникам), вы можете разделять, объединять и комбинировать поток данных с данными из других потоков данных или как-то иначе манипулировать информацией. На рис. 3 показан пример такого потока.

Рис. 3
SQL Server 2008 поддерживает средство Change Data Capture (CDC), с помощью которого можно регистрировать любые операции вставки, обновления и удаления в таблицах SQL Server, а детальную информацию об изменениях сделать доступной в простом для использования реляционном формате. Задействовав преимущества CDC при реализации ETL-решения в сочетании со службами интеграции SQL Server 2008, вы сможете гарантировать, что в процесс выборки будут включаться только измененные данные, что исключит издержки, связанные с выполнением полного обновления данных в каждой ETL-операции, в том числе неизмененных.
Благодаря специализированному набору компонентов, называемых адаптерами, SSIS могут использовать данные из самых разнообразных источников (а также загружать их), включая , OLE DB, ODBC, плоские файлы, Microsoft Office Excel® и XML. SSIS может работать даже с пользовательскими адаптерами данных (разработанными для внутреннего применения или третьими сторонами). Это позволяет обернуть унаследованную логику загрузки данных в источник данных, который потом можно «бесшовно» интегрировать в SSIS-поток данных. SSIS предоставляет набор мощных компонентов для преобразования данных, обеспечивающих операции, крайне важные при создании информационных хранилищ. К таким компонентам относятся следующие.
· Aggregate. Выполняет несколько операций агрегации за один проход.
· Sort. Сортирует данные в потоке.
· Lookup. Выполняет гибкие операции поиска с кешированием с использованием наборов справочных данных.
· Pivot и UnPivot. Два преобразования, для выполнения поворота (pivot) и обратного поворота (unpivot) данных в потоке.
· Merge, Merge Join и UnionAll. Позволяют выполнять операции присоединения (join) и объединения (union).
· Derived Column. Выполняет операции на уровне столбцов, например манипуляции над строками и числами, датой и временем, а также преобразование кодовых страниц. Этот компонент заключает в себе всю функциональность, которую другие поставщики могут разбивать на множество компонентов, выполняющих отдельные преобразования.
· Data Conversion. Конвертирует данные между разными типами данных (например, между числовыми и строковыми).
· Audit. Добавляет столбцы с необходимыми метаданными и другие данные аудита.
Помимо этих базовых преобразований, относящихся к информационным хранилищам, SSIS поддерживает дополнительные, более сложные преобразования, такие как Slowly Changing Dimensions (SCD). Мастер SCD в SSIS помогает пользователям задавать свои параметры управления медленно меняющимся измерениям (slowly changing dimensions) и на основе этих параметров генерирует полный поток данных с соответствующими преобразованиями. Также предоставляется поддержка стандартных типов SCD (Type 1 и Type 2) наряду с новыми типами SCD (Fixed Attributes и Inferred Members). На рис. 4 показано одно из окон мастера SCD.
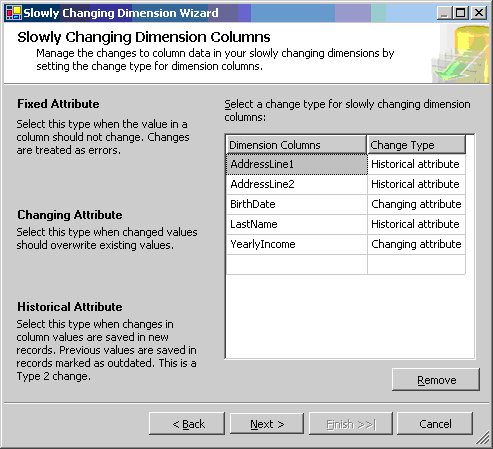
Рис. 4
На рис. 5 показан поток данных, сгенерированный этим мастером.
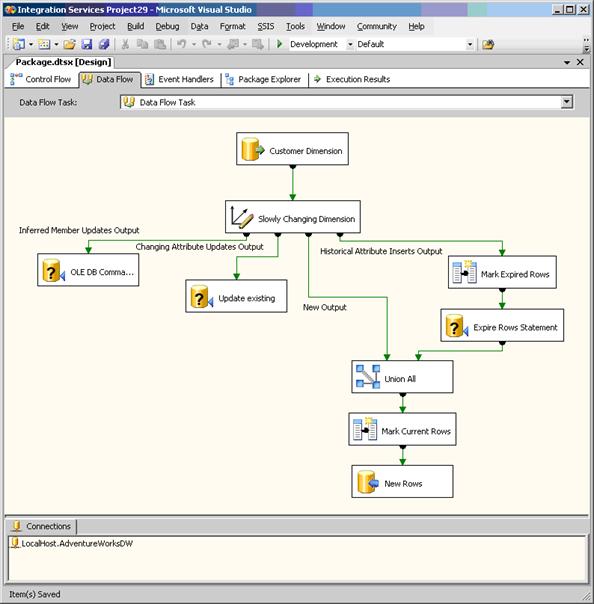
Рис. 5
С помощью SSIS вы можете заставить службы анализа загружать кеши многомерных OLAP-кубов (MOLAP) непосредственно из конвейера потока данных. То есть SSIS можно использовать не только для создания реляционных информационных хранилищ, но и для загрузки многомерных кубов для аналитических приложений.
SSIS и качество данных
Одна из важнейших особенностей SSIS — возможность интеграции не только данных, но и различных технологий манипуляций над данными. Это позволило включить в SSIS инновационные компоненты очистки данных с нечеткой логикой. Эти компоненты разработаны в Microsoft Research Labs, и они отражают новейшие научные достижения в этой области. В них заложена независимость от конкретной предметной области, т. е. они могут работать с данным независимо от специфики предметной области, например со справочными данными «адрес-почтовый индекс». Это позволяет использовать преобразования, поддерживаемые такими компонентами, для очистки данных большинства типов — не только данных, относящихся к адресам.
SSIS тесно интегрируется с функциональностью «просеивания» данных в службах анализа. Поддержка анализа данных обеспечивает абстрагирование от закономерностей в наборе данных и инкапсулирует их в модели анализа. Вы можете применять эту модель анализа, чтобы предсказывать, какие данные относятся к набору, а какие из них, возможно, являются аномальными. А значит, это позволяет использовать анализ данных как инструмент, обеспечивающий качество данных.
Поддержка сложного распределения данных в SSIS помогает не только выявлять аномальные данные, но и автоматически корректировать или заменять их. Это делает возможным варианты очистки по принципу «замкнутого цикла» («closed loop»). Пример такого варианта очистки потока данных представлен на рис. 6.
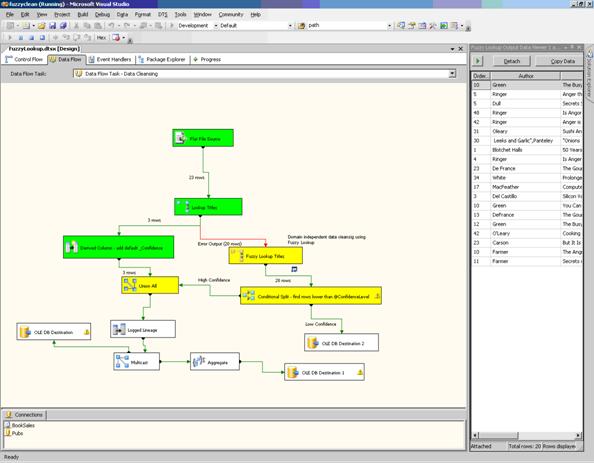
Рис. 6
Кроме встроенных средств, обеспечивающих качество данных, SSIS можно расширять, чтобы эти службы тесно взаимодействовали со сторонними решениями в области очистки данных.
Применение SSIS за рамками традиционных ETL-операций
Способность конвейера манипулировать почти любыми данными, глубокая интеграция со службами анализа, поддержка расширения с применением широкого спектра технологий для манипуляций над данными и включение полнофункционального механизма поддержки рабочих процессов — все это позволяет использовать SSIS во многих ситуациях, которые обычно рассматривают как выходящие за рамки традиционных ETL-операций.
Архитектура, ориентированная на сервисы
SSIS поддерживает выбор источников (sourcing) XML-данных в конвейере потока данных, в том числе файлов на диске и источников, указываемых URL-адресами по протоколу HTTP. XML-данные преобразуются в табличные, которыми легко манипулировать в потоке данных. Такая поддержка XML работает в сочетании с поддержкой веб-служб. SSIS может взаимодействовать с веб-службами для захвата XML-данных.
Вы можете получать XML из файлов, Microsoft Message Queuing (MSMQ) и из Интернета по протоколу HTTP. SSIS обеспечивает операции над XML с помощью XSLT, XPATH, diff/merge и других технологий и может направлять XML в поток данных.
Вся эта функциональность позволяет включать SSIS как элемент гибкой архитектуры, ориентированной на сервисы (Service Oriented Architectures, SOA).
Анализ данных и текста
SSIS не только тесно интегрируется со средствами «просеивания» данных в службах анализа, но и содержит компоненты анализа текста. Анализ текста (также называемый как классификация текста) включает выявление связей между бизнес-категориями и текстовыми данными (словами и фразами). Это позволяет распознавать ключевые термины в текстовых данных и на основе этого автоматически идентифицировать текст как «интересный» или «неинтересный». Такая функциональность в свою очередь облегчает операции «замкнутого цикла» («closed loop») для достижения бизнес-целей, например для увеличения степени удовлетворенности клиентов и повышения качества продуктов и услуг.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
