


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
004.42
оптимизация загрузки сервера базы данных на основе алгоритма обработки очереди сообщений
,
Большинство современных приложений баз данных реализованы на основе клиент-серверной архитектуры, состоящих из следующих трех компонент: пользовательский интерфейс; бизнес-логика; управление данными.
На сегодняшний день наиболее распространенными являются двухуровневая и трехуровневая технологические архитектуры приложений баз данных. В двухуровневом клиент-серверном приложении все функции по формированию пользовательского интерфейса реализуются на стороне клиента, все функции по управлению данными – на сервере, а вот бизнес-правила можно реализовать как на сервере, используя механизмы программирования сервера (хранимые процедуры, триггеры, представления и т. п.), так и на стороне клиента. В трехуровневом приложении появляется промежуточный уровень, реализующий бизнес-правила, которые являются наиболее часто изменяемыми компонентами приложения.
Сервер приложений по работе с базой данных должен обрабатывать большое количество транзакций и поддерживать множество одновременно подключенных клиентов, при этом скорость обмена данными должна оставаться высокой. Для решения данной проблемы мы предлагаем оптимизировать загрузку сервера баз данных на основе применения алгоритма организация очереди клиентов, которая представлена на рисунке 1.
При данном подходе прирост числа клиентов увеличивает время ответа сервера. Данную проблему можно решить распараллеливанием процесса проверки. Для этого программно создаются потоки обработки очереди, которым в качестве входного параметра задаются начальный и конечный диапазон обрабатываемых клиентов.
Расчет количества потоков Ct осуществляется по формуле 1.
Ct = Cc / oCc | (1) |
где: | Ct – количество потоков; |
Cc – количество подключенных к серверу приложений клиентов; | |
oCc – оптимальное количество клиентов, которые может обрабатывать сервер приложений без потери производительности. | |
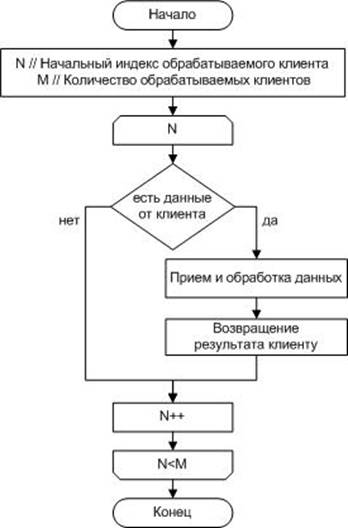
Рисунок 1 – Упрощенный алгоритм обработки очереди сообщений
В ходе тестирования приложения базы данных было установлено, что oCc составляет приблизительно 500 клиентов на поток.
Диапазон распределения клиентов Dc рассчитывается по формуле 2.
Dc = Cc / Ct | (2) |
где: | Dc – диапазон распределения клиентов; |
Cc – количество подключенных к серверу комплекса клиентов; | |
Ct – количество потоков. | |
Таким образом, осуществляется динамическое распределение нагрузки в процессе выполнения программы, что существенно повышает скорость отклика сервера.
Хранить информацию о подключенных клиентах в виде массива данных нерационально. Размер занимаемой при этом памяти Sd можно рассчитать по формуле 3.
Sd = Si ´ maxCc | (3) |
где: | Sd – размер памяти занимаемой массивом данных; |
Si – размер структуры информации о клиенте системы (как минимум 4 байта на описатель сокета); | |
maxCc – максимальное количество поддерживаемых клиентов (для операционных систем Microsoft Windows ограничение равно 0x7FFFFFFF). | |
Рассмотрим ситуацию, когда в определенный момент времени к серверу подключено 2 клиента, для обработки очереди по алгоритму, представленному на рисунке 1, программе придется каждый раз обходить весь массив, к тому же размер занимаемой памяти будет не сопоставим с размером полезной информации.
Для решения данной проблемы было принято решение использовать динамические массивы данных, организованные в виде линейного двусвязного списка (рисунок 2). По списку можно передвигаться в разных направлениях, и быстро удалять ненужные элементы, не заботясь об индексации и сортировке данных. Таким образом, по списку можно передвигаться в разных направлениях, и быстро удалять ненужные элементы, не заботясь об индексации и сортировке данных.
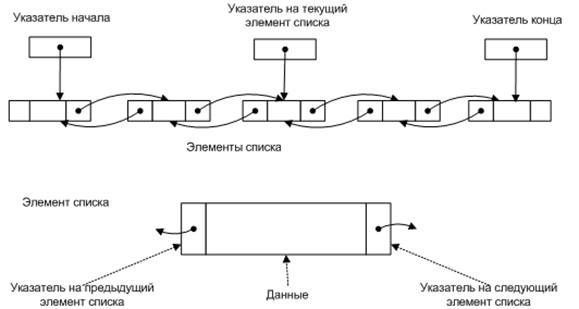
Рисунок 2 – Линейный двусвязный список
При таком подходе изменяется и алгоритм обработки очереди сообщений. Новый алгоритм показан на рисунке 2.
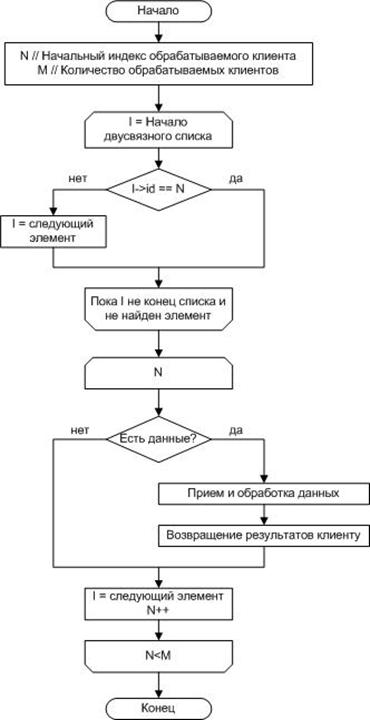
Рисунок 2 – Алгоритм обработки очереди сообщений
Для того чтобы сервер приложения баз данных имел возможность быстро обрабатывать запросы, поступающие от большого количества клиентов, необходимо реализовать представленный алгоритм обработки данных, в основе которого заложен метод выбора обрабатываемого клиента. Для достижения наибольшего быстродействия этот процесс необходимо распараллелить. В результате такого подхода нагрузка на сервер распределяется динамически в ходе работы приложения.
