


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Распределенная обработка может быть самой разнообразной.
Самый простой способ распределенной обработки данных представлен на схеме:
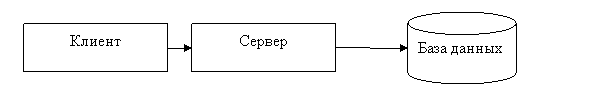

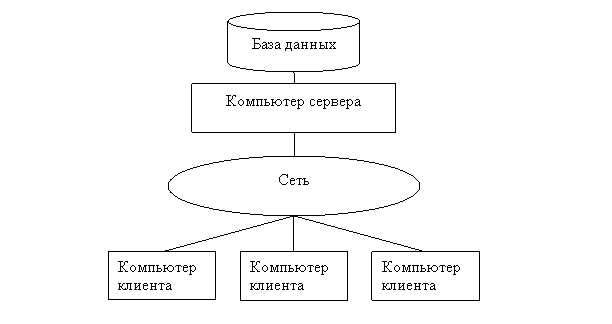
Чаще всего используется система, где к одному серверу обращаются несколько пользователей.

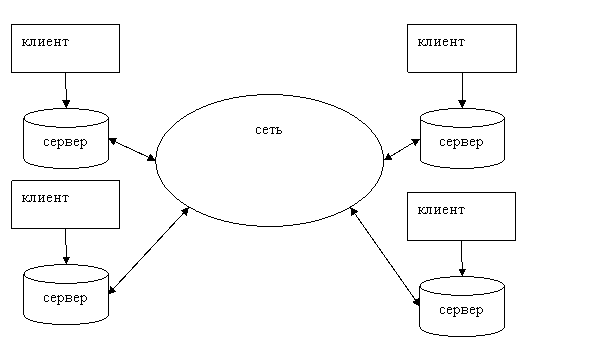 Возможна организация БД таким образом, что каждая машина будет и клиентом и сервером
Возможна организация БД таким образом, что каждая машина будет и клиентом и сервером
Итак: Полная поддержка для распределенных баз данных означает, что отдельное приложение может прозрачно обрабатывать данные, распределенные на множестве различных баз данных, управление которыми осуществляют разные СУБД, работающие на многочисленных машинах с различными операционными системами, соединенными вместе коммуникационными системами.
3.Процесс прохождения пользовательского запроса.
Иллюстрация взаимодействия СУБД, ОС и пользователя при обработке запроса 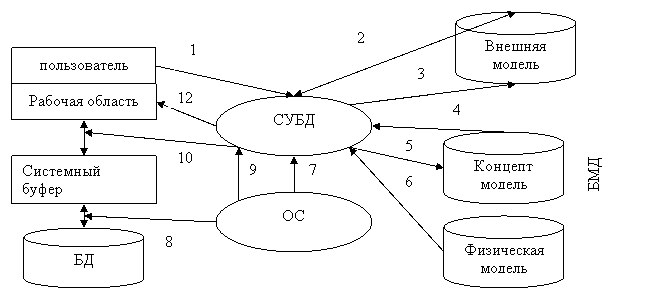

В базе метаданных хранится вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных.
Для управления БМД существует специальное программное обеспечение для администрирования баз данных. Оно предназначено для корректного использования информации всеми пользователями.
Последовательность взаимодействия:
1. Пользователь посылает СУБД запрос на получение данных из БД.
2. СУБД проверяет права пользователя, достаточно ли их для использования именно этих данных.
3. Если прав нет, т. е. произошел запрет на использование информации, СУБД сообщает об этом пользователю, если прав достаточно, СУБД определяет часть концептуальной модели затрагиваемой пользователем.
4. СУБД получает информацию о запрошенной части концептуальной модели.
5. СУБД запрашивает информацию о местоположении данных на физическом уровне (файлы или физические адреса).
6. В СУБД возвращается информация о местоположении данных в терминах операционной системы.
7. СУБД просит ОС предоставить необходимые данные, используя средства ОС.
8. ОС осуществляет перекачку информации из устройства хранения и пересылает её в системный буфер.
9. ОС оповещает СУБД об окончании пересылки.
10. СУБД выбирает из доставленной информации, находящейся в системном буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя.
Лекция 12.
Тема: “Физическая организация удаленных баз данных”
План лекции:
1. Физическая организация данных и структура хранения данных в SQL Server 7.0
2. Доступ к базе данных
3. Технология com
1. Физическая организация и структура хранения данных в SQL Server
Физическая организация современных баз данных является наиболее закрытой, она определяется как коммерческая тайна для большинства поставщиков СУБД. И здесь не существует никаких стандартов, поэтому каждый поставщик создает свою уникальную структуру и пытается обосновать её наилучшие качества по сравнению со своими конкурентами.
Физическая организация является в настоящий момент наиболее динамичной частью СУБД.
При распределении дискового пространства рассматриваются две схемы структуризации:
- физическая (определяет хранимые данные);
- логическая (определяет концептуальную модель данных).
SQL Server организует следующую иерархию хранения:
База данных – объем физического пространства, на котором размещаются данные.
Файл – каждая база данных имеет не менее 2-х файлов. Один непосредственно данный и журнал транзакций.
Страница. Файлы делятся на страницы по 8 Кбайт
Блоки – некоторая область для оперативной памяти.
Различают 7 типов страниц:
– Страница данных (Data page)
– Индексные страницы (Index Page)
– Страницы журнала транзакций (Log page)
– Текстовые страницы (Text / image page)
– Карты распределения блоков
– Карты свободного пространства
– Индексные карты размещения
2. Доступ к базе данных
Поиск и предоставление данных пользователю осуществляется с помощью программ доступа к данным – диспетчера файлов и диспетчера дисков. В целом работа СУБД построена стандартным образом и включает 3 основных этапа:
1. Сначала в СУБД определяется искомая запись, а затем для её извлечения запрашивается диспетчер файлов.
2. Диспетчер файлов определяет страницу, на которой находится искомая запись, а затем для извлечения этой страницы запрашивается диспетчер дисков.
3. Диспетчер дисков определяет физическое положение искомой страницы на диске и посылает соответствующий запрос на ввод-вывод данных.
Итак, с точки зрения СУБД база данных выглядит как набор записей, которые могут просматриваться с помощью диспетчера файлов.
С точки зрения диспетчера файлов БД выглядит как набор страниц, которые могут просматриваться с помощью диспетчера дисков.
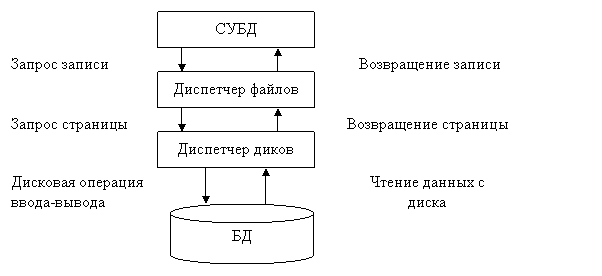

Диспетчер дисков является компонентом ОС, с помощью которого выполняются все дисковые операции ввода-вывода. Если диспетчер файлов запрашивает некоторую страницу p, для её извлечения диспетчеру дисков необходимо знать, где конкретно находится страница p на физическом диске, но диспетчеру файлов необязательно знать физические адреса.
Диспетчер файлов рассматривает диск как набор страниц фиксированного размера, с уникальным номером набора страниц. Соответствие физических адресов на диске и номеров страниц достигается с помощью диспетчера дисков.
Итак, операции, выполняемые диспетчером дисков с набором страниц, следующие:
– Извлечение страницы p из набора страниц s;
– Замена страницы p из набора страниц s;
– Добавление новой страницы p в набор страниц s;
– Удаление страницы p из набора страниц s.
Первые две операции являются базовыми операциями ввода-вывода на уровне страниц, а две другие позволяют увеличивать или уменьшать наборы страниц по мере необходимости.
Диспетчер файлов может содержаться либо в составе ОС, либо входить в состав СУБД.
Каждый хранимый файл имеет имя (file name) и идентификационный номер (ID).
Основные операции с файлами, выполняемые диспетчером файлов, т. е. операции, на выполнение которых поступил запрос со стороны СУБД, следующие:
– Извлечение хранимой записи z из хранимого файла f;
– Запоминание хранимой записи z в хранимом файле f;
– Добавление записи;
– Удаление записи;
– Создание нового файла f;
– Удаление хранимого файла.
С помощью этих простых операций с файлами в СУБД можно создавать структуры хранения и управления данными.
3.Технология com
Сom – Component Object Model (компонентная модель объектов)
Эта технология разработана корпорацией Microsoft. Она выполняет важную задачу, а именно передачу данных от одной программы (клиента) в другую (сервер) независимо, где она находится (возможно в другой части света).
Клиент является инициатором общения, он обращается к одной из служб сервиса сервера с требованием получить некоторые данные.
COM-технология - это объектная модель компонентов. Технология СОМ применяется при описании API и двоичного стандарта для связи объектов различных языков и сред программирования. СОМ предоставляет модель взаимодействия между компонентами и приложениями.
Технология СОМ работает с так называемыми СОМ-объектами. СОМ-объекты похожи на обычные объекты визуальной библиотеки компонентов Delphi. СОМ-объекты содержат свойства, методы и интерфейсы.
Обычный СОМ-объект включает в себя один или несколько интерфейсов. Каждый из этих интерфейсов имеет собственный указатель.
Технология СОМ имеет два явных плюса:
- создание СОМ-объектов не зависит от языка программирования. Таким образом, СОМ-объекты могут быть написаны на различных языках;
- СОМ-объекты могут быть использованы в любой среде программирования под Windows. В число этих сред входят Delphi, Visual C++, C++Builder, Visual Basic, и многие другие.
Лекция 13
Тема: ”База данных — хранилище объектов“
1.Основные принципы физического проектирования базы данных.
Прежде всего, необходимо сформулировать основные принципы, на которых будет строиться проектируемая БД.
1. Каждая сущность, информация о которой хранится в БД, — это объект.
2. Каждый объект уникален в пределах БД и имеет уникальный идентификатор.
3. Объект имеет свойства (строковые, числовые, временные, перечислимые), которые описывают атрибуты сущности.
4. Объекты могут быть связаны между собой произвольным образом. Связь характеризуется связанными объектами и типом связи. Например, сотрудник фирмы может быть связан с отделом, в котором он работает, связью типа «сотрудник в отделе» и т. п. Связь в определенном смысле аналогична понятию ссылки на таблицу-справочник в традиционной модели БД.
5. Объект может быть хранилищем. В этом случае допускается хранение в нем других объектов (например, товара на складе).
6. Такая БД не привязана ни к какой бизнес-модели и позволяет реализовать «над собой» практически любую бизнес-логику. Логика выделяется в отдельный программный слой и, как правило, реализуется на сервере приложений, где по запросу клиента создаются объекты, загружающие информацию о себе из БД и реализующие «поведение» объектов реального мира. В то же время, в силу однообразности модели хранения, эти объекты довольно легко создаются на основе базовых классов, инкапсулирующих функциональность по загрузке и сохранению свойств и связей в БД.
Объекты
Объект в нашей БД — понятие скорее логическое, его основное назначение — предоставить уникальный идентификатор, по которому его можно будет отличить. Кроме того, каждый объект обладает типом. Типы описываются при создании структуры базы данных.
Свойства
Свойства объектов отражают реальные атрибуты описываемых ими сущностей. Все они принадлежат к какому-то объекту и содержат некую информацию об атрибуте и его величине, причем список атрибутов является общим для всех объектов одного и того же типа.
Величина же может выражаться данными различного типа. Будем хранить в БД атрибуты следующих типов:
- Строковые Числовые. Различия между целыми и вещественными числами делать не будем, полагая целые подмножеством вещественных. Если задача диктует невозможность применения данного подхода — придется выделять эти атрибуты в различные типы Исторические (дата и время) Перечислимые (например, форма собственности фирмы)
Контрольные вопросы.
1.Поясните основные концепции технологии проектирования баз данных.
2.Чем характеризуется современное состояние технологии баз данных?
3. Какими возможностями обладает современная СУБД?
ИСПОЛЬЗУЕМЫЕ ИСТОЧНИКИ:
1. Голицына, О. Л. и др. Базы данных; Форум; Инфра-М, 2013. - 399 c.
2. Гринченко, Н. Н. и др. Проектирование баз данных. СУБД Microsoft Access; Горячая Линия Телеком, 2012. - 613 c.
3. Дейт, К. Дж. Введение в системы баз данных; К.: Диалектика; Издание 6-е, 2012. - 360 c.
4. Дэвидсон, Луис проектирование баз данных на SQL Server 2000; Бином, 2009. - 631 c.
5. Дюваль, епрерывная интеграция. Улучшение качества программного обеспечения и снижение риска; М.: Вильямс, 2008. - 497 c.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
