


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для непрерывных случайных величин, ![]() и
и ![]() , заданных плотностями распределения вероятностей
, заданных плотностями распределения вероятностей ![]() ,
, ![]() и
и ![]() , аналогичная формула имеет вид
, аналогичная формула имеет вид
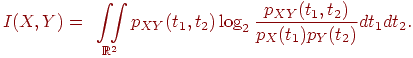
Очевидно, что
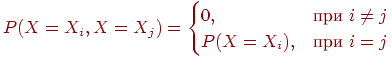
и, следовательно,
![]()
Энтропия дискретной случайной величины ![]() в теории информации определяется формулой
в теории информации определяется формулой
![]()
Свойства меры информации и энтропии:
![]() ,
, ![]() и
и ![]() независимы;
независимы;
![]() ;
;
![]() - константа;
- константа;
![]() , где
, где ![]() ;
;
![]() . Если
. Если ![]() , то
, то ![]() - функция от
- функция от ![]() . Если
. Если ![]() - инъективная функция1) от
- инъективная функция1) от ![]() , то
, то ![]() .
.
Смысл энтропии Шеннона
Вводится понятие энтропии. На нескольких примерах показывается, как вычисляется энтропия дискретной случайной величины. Вводится понятие префиксного кодирования. Задачи на самостоятельную работу улучшают восприятие материала. Также много различных математических исследований
Энтропия. дискретной случайной величины - это минимум среднего количества бит, которое нужно передавать по каналу связи о текущем значении данной д. с.в.
Рассмотрим пример (скачки). В заезде участвуют 4 лошади с равными шансами на победу, т. е. вероятность победы каждой лошади равна 1/4. Введем д. с.в. ![]() , равную номеру победившей лошади. Здесь
, равную номеру победившей лошади. Здесь 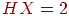 . После каждого заезда по каналам связи достаточно будет передавать два бита информации о номере победившей лошади. Кодируем номер лошади следующим образом: 1-00, 2-01, 3-10, 4-11. Если ввести функцию
. После каждого заезда по каналам связи достаточно будет передавать два бита информации о номере победившей лошади. Кодируем номер лошади следующим образом: 1-00, 2-01, 3-10, 4-11. Если ввести функцию ![]() , которая возвращает длину сообщения, кодирующего заданное значение
, которая возвращает длину сообщения, кодирующего заданное значение ![]() , то м. о.
, то м. о. ![]() - это средняя длина сообщения, кодирующего
- это средняя длина сообщения, кодирующего ![]() . Можно формально определить
. Можно формально определить ![]() через две функции
через две функции ![]() , где
, где  каждому значению
каждому значению ![]() ставит в соответствие некоторый битовый код, причем, взаимно однозначно, а
ставит в соответствие некоторый битовый код, причем, взаимно однозначно, а ![]() возвращает длину в битах для любого конкретного кода. В этом примере
возвращает длину в битах для любого конкретного кода. В этом примере 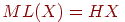 .
.
Пусть теперь д. с.в. ![]() имеет следующее распределение
имеет следующее распределение
![]()
т. е. лошадь с номером 1 - это фаворит. Тогда
![]()
Закодируем номера лошадей: 1-0, 2-10, 3-110, 4-111, - т. е. так, чтобы каждой код не был префиксом другого кода (подобное кодирование называют префиксным). В среднем в 16 заездах 1-я лошадь должна победить в 12 из них, 2-я - в 2-х, 3-я - в 1-м и 4-я - в 1-м. Таким образом, средняя длина сообщения о победителе равна ![]() бит/сим или м. о.
бит/сим или м. о. ![]() . Действительно,
. Действительно, ![]() сейчас задается следующим распределением вероятностей:
сейчас задается следующим распределением вероятностей: ![]() ,
, ![]() ,
, ![]() . Следовательно,
. Следовательно,
![]()
Итак, ![]() .
.
Можно доказать, что более эффективного кодирования для двух рассмотренных случаев не существует.
То, что энтропия Шеннона соответствует интуитивному представлению о мере информации, может быть продемонстрировано в опыте по определению среднего времени психических реакций. Опыт заключается в том, что перед испытуемым человеком зажигается одна из ![]() лампочек, которую он должен указать. Проводится большая серия испытаний, в которых каждая лампочка зажигается с определенной вероятностью
лампочек, которую он должен указать. Проводится большая серия испытаний, в которых каждая лампочка зажигается с определенной вероятностью ![]()
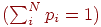 , где
, где ![]() - это номер лампочки. Оказывается, среднее время, необходимое для правильного ответа испытуемого, пропорционально величине энтропии
- это номер лампочки. Оказывается, среднее время, необходимое для правильного ответа испытуемого, пропорционально величине энтропии 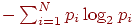 , а не числу лампочек
, а не числу лампочек ![]() , как можно было бы подумать. В этом опыте предполагается, что чем больше информации будет получено человеком, тем дольше будет время ее обработки и, соответственно, реакции на нее.
, как можно было бы подумать. В этом опыте предполагается, что чем больше информации будет получено человеком, тем дольше будет время ее обработки и, соответственно, реакции на нее.
Семантическая информация
В 50-х годах XX века появились первые попытки определения абсолютного информационного содержания предложений естественного языка. Стоит отметить, что сам Шеннон однажды заметил, что смысл сообщений не имеет никакого отношения к его теории информации, целиком построенной на положениях теории вероятностей. Но его способ точного измерения информации наводил на мысль о возможности существования способов точного измерения информации более общего вида, например, информации из предложений естественного языка. Примером одной из таких мер является функция 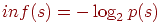 , где
, где ![]() - это предложение, смысловое содержание которого измеряется,
- это предложение, смысловое содержание которого измеряется, ![]() - вероятность истинности
- вероятность истинности ![]()
Вот некоторые свойства этой функции-меры:
если ![]() (из
(из ![]() следует
следует ![]() ) - истинно, то
) - истинно, то ![]() ;
;
![]() ;
;
если ![]() - истинно, то
- истинно, то ![]() ;
;
![]() , т. е. независимости
, т. е. независимости ![]() и
и ![]() .
.
Значение этой функция-меры больше для предложений, исключающих большее количество возможностей. Пример: из ![]() - "
- "![]() " и
" и ![]() - "
- "![]() " следует, что
" следует, что ![]() или
или  ; ясно, что
; ясно, что ![]() исключает больше возможностей, чем
исключает больше возможностей, чем ![]() .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
