

Эти параметры, во-первых, должны быть легко измеряемы и мало зависимы от мешающих факторов окружающей среды (шумов и помех); во-вторых, они должны характеризоваться стабильностью во времени и, в-третьих, не должны быть привязаны к индивидуальным особенностям говорящего (таким, как психофизиологические особенности диктора и диалектические особенности его речи). Создание системы признаков, удовлетворяющей всем этим требованиям, является трудно решаемой задачей, поэтому большинство исследователей, в первую очередь, производят их отбор по основному критерию, а именно, по их способности адекватно и эффективно производить описание отдельной голосовой команды, уделяя меньше внимания другим факторам.
Более целесообразным является построение такой системы распознавания, которая оперировала бы с речевым сигналом как с целым, анализируя его как с точки зрения смысловой, так и индивидуальной, интонационной и динамической. Такой анализ дал бы возможность представить полную картину каждого конкретного сообщения в виде системы отношений, учитывающей вклад и участие в ней всех многообразных компонентов данного сигнала. Соответствующий этому анализу автомат, помимо эффективности, будет характеризоваться и универсальностью, с одинаковым успехом решая как задачи распознавания смыслового содержания произнесенной фразы, так и задачи автоматического различения голосов, независимо от смыслового содержания сказанного.
Предлагаемый алгоритм распознавания изолированных устных команд построен на основе сравнения следующих параметров входного сигнала и эталонов: энергии Тэгера (Teager Energy), двухполюсного анализа на основе линейного предсказания и погрешности линейного предсказания. Алгоритм состоит из следующих функциональных блоков (рис.1):
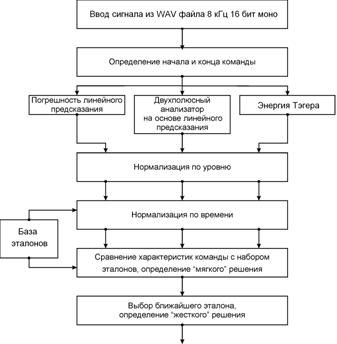
Рис. 1. Структурная схема алгоритма распознавания изолированных устных команд
1. Ввод речевого сигнала из файла. Следует отметить, что алгоритм работает с сигналами, имеющими достаточно низкую частоту дискретизации (8 кГц). Впоследствии предполагается уменьшить разрядность квантователя с 16 до 8 бит, чтобы сделать возможным распознавание команд, прошедших через канал тональной частоты (телефонный канал).
2. Определение границ команды осуществляется при рассмотрении динамики изменения абсолютной энергии сигнала и энергии Тэгера. Подробнее вопрос определения конечных точек фразы рассмотрен в [3].
3. Вычисление энергии Тэгера [3] производится по следующему алгоритму: Ei = Si – Si-1*Si+1. (1)
Преимущество энергии Тэгера по сравнению с абсолютной энергией (модулем сигнала) заключается в том, что значение этой величины отображает информацию не только об амплитуде сигнала, но и о его частоте. Энергия (равно как и коэффициенты и погрешность линейного предсказания) усредняется на промежутках времени в 160 отсчетов (20 мс) и вычисляется с перекрытиями в 40 отсчетов (5 мс). Это позволяет избавиться от случайных флуктуаций вычисляемых характеристик.
4. Коэффициенты линейного предсказания вычисляются на основе автокорреляционного метода [4]. Двухполюсная модель с приемлемой точностью характеризует распределение энергии в спектре сигнала, позволяя при этом абстрагироваться от расположения формант, значения частот которых являются индивидуальными особенностями голоса. Далее вычисляется погрешность линейного предсказания как разность между исходным речевым сигналом и его двухполюсной моделью.
5. Функции кратковременной энергии, коэффициентов и погрешности линейного предсказания нормируются под выбранное стандартное для всех эталонов и входных сигналов значение.
6. База эталонов представляет собой набор всех команд, которые могут поступать на вход алгоритма. Каждой команде ставится в соответствие некоторое число эталонов. Число эталонов у разных команд может различаться, но при этом оно не должно быть меньше единицы.
7. Выравнивание сигнала с эталоном по временной оси предназначено для ликвидации возможных различий скорости произнесения команды или отдельных ее частей (региональные и индивидуальные особенности говорящего). Выравнивание в предлагаемом алгоритме осуществляется с помощью метода динамического программирования [1].
8. Для сравнения сигнала с эталоном производится вычисление Евклидова расстояния в пятимерном пространстве. Выбранная метрика не является единственно возможной. Наряду с Евклидовой метрикой в подобных алгоритмах довольно часто применяют метрики Махаланобиса, Минковского и др. На выходе блока оценки степени близости имеется массив, состоящий из расстояний между параметрами входной команды и каждого из эталонов.
9. В алгоритме предусмотрены две возможные реализации блока принятия окончательного («жесткого») решения. Первый вариант заключается в том, что входной команде ставится в соответствие та команда из базы, которой принадлежит ближайший (с точки зрения выбранной метрики) к входному сигналу эталон. Второй вариант реализации алгоритма предполагает усреднение расстояний до эталонов в пределах каждой команды. После этой операции осуществляется выбор как результата распознавания той команды, которая имеет минимум усредненной оценки.
Алгоритм проверялся на словаре, состоящем из десяти цифр, произносимых дикторами на русском языке («ноль», «один», «два», «три», «четыре», «пять», «шесть», «семь», «восемь», «девять»). Для анализа надежности распознавания десяти дикторам-мужчинам в возрасте 20-45 лет было предложено произнести указанные команды в случайном порядке, но так, чтобы каждая была произнесена ровно три раза. Следует отметить, что дикторы являются совершенно незаинтересованными в результатах опыта людьми, т. е. исключается возможность намеренного изменения произнесения команд с целью увеличить либо уменьшить вероятность верного распознавания. Некоторые из дикторов имели ярко выраженные индивидуальные и национальные особенности речи (картавость, гнусавость и др.). Запись проводилась в условиях звукоизолированного помещения, фильтрация записанных речевых образцов не проводилась. В зависимости от конкретного диктора отношение сигнал/шум находится в пределах 30-45 дБ.
Проверка алгоритма проводилась в двух режимах:
1. Образцы команд каждого из дикторов заносятся в базу эталонов, т. е. в данном режиме заранее из-вестны все дикторы, которые могут произносить команды. Такая ситуация, например, может реа-лизовываться в системе голосового набора номера на мобильном телефоне, когда владелец (или владельцы) аппарата заранее определены. В среднем, вероятность распознавания в таком режиме работы колеблется в пределах 75-85% в зависимости от конкретного диктора. Отмечено, что алгоритм лучше работает при спокойном, размеренном произнесении команд. При малых паузах между ними слова начинают оказывать влияние друг на друга, поскольку артикуляторный аппарат человека перестраивается под произнесение сле-дующего звука не мгновенно. Это проявляется в виде смещения формантных частот и перераспределения энергии по спектру в конечных точках голосовой команды. Последнее (перераспределение энергии) для дан-ного алгоритма наиболее критично, т. к. при таких искажениях сигнала происходит значительное изменение модели на основе линейного предсказания.
2. В базу эталонов заносятся образцы команд нескольких дикторов из их полного набора, а распознаются ко-манды тех дикторов, которые в базу не попали. При таком анализе осуществляется проверка алгоритма на дикторонезависимость. В этом случае вероятности верного распознавания имеют значительный разброс в зависимости от конкретного диктора. Средний результат по окончании опытов составил примерно 60-75%. В отдельных случаях вероятность распознавания человека, не входящего в базу эталонов, доходила до 85%. Однако для людей, имеющих значительные региональные или индивидуальные особенности речи, ве-роятность верного результата не превышала 60%.
Представленный алгоритм при распознавании выполняет относительно небольшое количество вычислений. При нахождении параметров, необходимых для работы системы, не требуется мощной аппаратной части (скоростных процессоров и больших ресурсов памяти). Для хранения образцов команд не требуется записывать в память сам сигнал.
Таблица 1. Результаты работы программы: дикторозависимое распознавание
Исходное сообщение | |||||||||||
Результат распознавания | «0» | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9» | |
«0» | 70% | 10% | 5% | 25% | |||||||
«1» | 100% | ||||||||||
«2» | 30% | 90% | 5% | ||||||||
«3» | 65% | 5% | 10% | ||||||||
«4» | 100% | ||||||||||
«5» | 10% | 55% | 10% | ||||||||
«6» | 100% | ||||||||||
«7» | 10% | 95% | |||||||||
«8» | 5% | 100% | |||||||||
«9» | 20% | 80% |
Таблица 2. Результаты работы программы: дикторонезависимое распознавание

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
