

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Исходное сообщение | |||||||||||
Результат распознавания | «0» | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9» | |
«0» | 60% | 10% | 5% | 25% | |||||||
«1» | 90% | 5% | |||||||||
«2» | 35% | 80% | 10% | 5% | |||||||
«3» | 65% | 15% | 10% | ||||||||
«4» | 95% | 10% | |||||||||
«5» | 5% | 10% | 15% | 55% | 5% | 15% | |||||
«6» | 90% | ||||||||||
«7» | 10% | 85% | |||||||||
«8» | 10% | 80% | |||||||||
«9» | 15% | 5% | 5% | 75% |
В качестве областей применения распознавателя можно предложить:
1. Голосовой набор номера телефона.
2. Автоматический выбор сотрудника по фамилии, т. е. при звонке в офис автоматическая система предлагает назвать фамилию сотрудника, с которым необходимо произвести соединение.
3. Голосовое управление бытовыми приборами в помещении: освещением, телевизором, радиоприемником, кондиционером и другими устройствами, управление которыми в настоящее время осуществляется с помощью пультов дистанционного управления.
Литература
1. Rabiner L., Juang B. Fundamentals of speech recognition. Prentice Hall, Englewood Cliffs, New Jersey, 1993.
2. Rabiner L., Sambur M. An algorithm for determining the endpoints of isolated utterances // Bell Syst. Tech. J., 1975. V. 54, P. 297-315.
3. Gu L., Zahorian S. A new robust algorithm for isolated word endpoint detection // Submitted to Proc. IEEE ICASSP-02, 2002. P. 185-259.
4. , Шафер обработка речевых сигналов: Пер. с англ. / Под ред. и . – М.: Радио и связь, 1981.
5. Flanagan J. Speech analysis, synthesis, and recognition. 2nd ed. New York: Springer-Verlag, 1972.
¾¾¾¾¾¨¾¾¾¾¾
aLGORYTHM OF COMMAND RECOGNITION WITH LIMITED DICTIONARY
Konovalov A., Novosyelov S.
Yaroslavl State University
14 Sovetskaya st., Yaroslavl, Russia 150000. Phone: 7-4852-797775. E-mail: *****@***ac. ru
The speech recognition system is a special case of automatic image recognition system which includes three basic stages: reception of the initial parametrical signal description; finding effective system of attributes; construction of a solving rule.
If the second and third stages more or less easily give into algorithmization, the first stage is rather difficult to formalize. Therefore the initial description is set only on the experience and intuition of its creator. It is especially brightly shown in problems where it’s difficult to specify exact signal characteristics which can be responsible for properties and displays of the given object. Speech signal research shows, that a plenty of various signal characteristics have differ self-descriptiveness. Usually these characteristics make large data file. Its efficiency, however, cannot be estimated in advance, until we define the quantity of redundant information. Therefore the choice of speech signal parameters capable to describe its semantic maintenance in the best way is, perhaps, the most important stage at construction of automatic speech recognition systems.
The offered algorithm of isolated verbal commands recognition is based on the comparison of input signal and templates: Teager Energy, the bipolar analysis on the basis of linear prediction and linear prediction error.
The algorithm was checked on the dictionary consisting of ten figures, pronounced in Russian. It was offered to say the specified commands to ten announcers-men in the age of 20-45 years to analyze the recognition mands were pronounced in the random order but so that each one has been said exactly three times.
Some of announcers had bright individual features of speech (burring, twanging, etc.). Record was carried in the soundproofed premise; without filtration of the recorded speech samples. The signal/noise rate was depended on the concrete announcer and was located within the limits of 30-45 dB.
The presented algorithm of recognition carries out small amount of calculations. To find the parameters for system functioning, we do not require high-end hardware (high-speed processors and great amount of memory). It is not required to save signal in memory to store templates.
We may offer several fields to use speech recognition systems:
1. A voice set of a phone number.
2. An automatic choice of the employee on a surname.
3. Voice management of household appliances.
¾¾¾¾¾¨¾¾¾¾¾
СУБПОЛОСНЫЙ АЛГОРИТМ ОЦЕНКИ ШУМА ДЛЯ ОДНОМИКРОФОННОЙ АДАПТИВНОЙ СИСТЕМЫ ФИЛЬТРАЦИИ ЗАШУМЛЕННОГО РЕЧЕВОГО СИГНАЛА
Московский государственный технический университет им.
1. Введение
В настоящее время существует множество подходов к построению одномикрофонных систем адаптивной фильтрации зашумленного речевого сигнала. Можно выделить следующие, получившие наибольшее практическое распространение, группы методов: методы, основанные на теории фильтров Винера и методы, основанные на теории Баесовских оценок.
Большое количество работ посвящено разработке алогритмов фильтрации зашумленного речевого сигнала в частотной области. Связано это с наличием эффективных алгоритмов быстрого преобразования Фурье.
Для систем фильтрации зашумленного речевого сигнала крайне важна задача оценки шума. Алгоритм оценки шума, использующейся в системе адаптивной фильтрации зашумленного речевого сигнала, оказывает большое влияние на искажения речи системой фильтрации зашумленных речевых сигналов, и напрямую влияет на разборчивость речи.
На сегодняшний день разработано множество алгоритмов оценки шума. Алгоритмы оценки шума можно разделить на два класса: алгоритмы использующие решения детектора речевого сигнала [9] и алгоритмы, не использующие детектор речевого сигнала [3]. Алгоритмы, относящиеся к первому классу очень чувствительны к ошибкам детектора речевого сигнала. Алгоритмы, относящиеся ко второму классу имеют наибольшую вычислительную эффективность при посредственной точности оценки шума.
Важным требованием к алгоритму оценки является способность к функционированию в условиях нестационарного шума.
Предложенный в работе [2] алгоритм оценки шума improved minima controlled recursive averaging noise estimation (IMCRA) основан на поиске минимального значения сигнала на некотором интервале. К недостаткам предложенного алгоритма следует отнести высокую чувствительность к кратковременным скачкам мощности шума, приводящую к значительному увеличению ошибки оценки и, как следствие, подавлению фонем с малой энергией.
Предложенный в работе алгоритм в меньшей степени подавляет фонемы с малой энергией, что позволило увеличить разборчивость отфильтрованного речевого сигнала. Кроме того, алгоритм требует меньших вычислительных ресурсов по сравнению с алгоритмом IMCRA.
2. Субполосный алгоритм оценки шума
Входной сигнал адаптивной системы фильтрации зашумленного речевого сигнала в частотной области можно представить в виде (1) 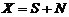 (1). Где
(1). Где ![]() - L-мерный вектор коэфициентов кратковременного дискретного преобразования Фурье (ДПФ) входного сигнала системы адаптивной фильтрации зашумленного речевого сигнала,
- L-мерный вектор коэфициентов кратковременного дискретного преобразования Фурье (ДПФ) входного сигнала системы адаптивной фильтрации зашумленного речевого сигнала, ![]() - L-мерный вектор коэфициентов кратковременного ДПФ речевого сигнала,
- L-мерный вектор коэфициентов кратковременного ДПФ речевого сигнала, ![]() - L-мерный вектор коэфициентов кратковременного ДПФ шума. Далее будут использованны следующие обозначения:
- L-мерный вектор коэфициентов кратковременного ДПФ шума. Далее будут использованны следующие обозначения: ![]() - номер коэфициента кратковременного ДПФ.
- номер коэфициента кратковременного ДПФ. ![]() - номер временного фрейма на котором расчитывается кратковременное ДПФ.
- номер временного фрейма на котором расчитывается кратковременное ДПФ.
В основе метода детектирования речевого сигнала лежит предположение о том, что сигнал в каждой полосе кратковременного преобразования Фурье имеет нормальное распределение. Для построения детектора речевого сигнала введем две гипотезы: ![]() - речевой сигнал отсутствует,
- речевой сигнал отсутствует,
![]() - речевой сигнал присутствует
- речевой сигнал присутствует
Условные плотности вероятностей для каждой полосы будут иметь вид (2). 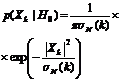
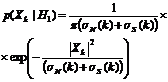 (2). Где
(2). Где ![]() ,
, ![]() - соответственно дисперсия шума и речевого сигнала в каждой полосе кратковременного дискретного преобразования Фурье.
- соответственно дисперсия шума и речевого сигнала в каждой полосе кратковременного дискретного преобразования Фурье.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
