


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
8. Игорь Жарков, Павел Скрелин, Михаил Гусев, «Голос Времени», Москва, Компьютер пресс, 2005, август, №8, стр. 86-92
Современное состояние исследований и разработок в области реализации проекта. Новизна предлагаемого подхода по сравнению с известными.
Вопрос в том, насколько широко рассматривать область реализации проекта… Если ее сузить до моделей речевого потока различных групп населения, то можно утверждать следующее: «В процессе подготовки заявки на получение патента РФ на полезную модель - статистическую модель речи был проведен всесторонний патентный поиск по патентным и литературным источникам. Патентный поиск выявил отсутствие однозначного прототипа у статистической модели». Таким образом, с высокой долей вероятности, можно утверждать, что разработка статистической модели русской речи является пионерским проектом.
В качестве ближайшего направления, по которому ведутся работы и есть доступная информация, можно рассматривать речевые базы данных. Речевые базы данных создаются во многих странах мира, наполнение и назначение этих баз очень разнообразно. Интерес к речевым базам обусловлен и тем, что для решения практически любой задачи из области речевых технологий (синтез, распознавание, идентификация или верификация) требуется запись соответствующей речевой базы.
В 1992 году в США был создан консорциум LDC4 (Linguistic Data Consortium), объединивший в себе более 100 компаний, университетов и разработчиков. LDC предлагает более 100 речевых баз, которыми пользуется более 600 компаний.
Одним из наиболее популярных продуктов, предлагаемых LDC является корпус спонтанной речи TIMIT, включающий в себя записи 10 фонетически представительных фраз, начитанные 630 дикторами, носителями 8 основных диалектов американского английского. Все записи отсегментированы и затранскрибированы. Предусмотрена возможность доступа к звуковым данным по их описанию.
В 1995 г. под эгидой Комиссии Европейского Сообщества была создана Европейская ассоциация лингвистических ресурсов ELRA5 (European Language Resources Association), ставящая свой целью взаимодействие ученых западноевропейских стран в области создания и распространения источников, необходимых для изучения языков и конструирования систем обработки данных на естественных языках. ELRA распространяет через Internet лингвистические ресурсы, создаваемые в рамках различных проектов и ассоциаций, например ELSNET6 (European Network in Language and Speech) и Copernicus RELATOR7.
Компания Cognitive Technologies8 занимается речевыми технологиями с 1993 года. В 1997 году была записана речевая база ISABASE, содержащая более 5000 предложений, произнесенных 50 дикторами. База состояла из двух частей - фонетически сбалансированной и фонетически репрезентативной. Фрагменты речи сопровождались разметкой на лексические и фонетические единицы (слова и фонемы).
В 2001 году по заказу Intel Corp.9 Cognitive Technologies записала речевой корпус большого объема RuSpeech. Отрывки для речевого корпуса зачитывали 220 дикторов, каждый в среднем произнес около 250 предложений. В итоге в RuSpeech вошло более 50 тыс. предложений (общий объем речевой базы 15 Гб), прослушивание которых занимает примерно 50 часов. В работе над RuSpeech принимали участие ведущие специалисты в области фонетики во главе с профессором филологического факультета МГУ Ольгой Кривновой.
На кафедре фонетики СПбГУ была разработана акустическая звуковая база данных звуковой архив, предназначенная для организации архивных звукозаписей в компьютерной форме. Звуковой архив обеспечивает доступ пользователя не только к звуковому материалу и его атрибуции, но и текстовой расшифровке, транскрипциям и т. п.. Звуковой архив был использован для организации архива из коллекции Фонограммархива Пушкинского дома, в котором собраны образцы фольклора немцев, проживавших в России в 20-х – 30-х годах прошлого века.10
Далее можно рассматривать все направления, относящиеся к речевым технологиям, т. к. статистическая модель призвана служить проведению исследований и разработок по каждому из них, однако это будет очень длинный разговор. Мы остановимся лишь на синтезе речи (не на синтезе речи вообще, а лишь на обработке речевого сигнала), т. к. многие алгоритмы этого направления являются неотъемлемой частью статистической модели.
На сегодняшний день известны два основных принципа построения систем синтеза речи – это синтез «по правилам» и компилятивный синтез. Синтез «по правилам» основан на формировании физических характеристик звуков речи на основе их математических описаний и обладает низкой естественностью.
Для статистической модели, содержащей большой объем звуковых данных, более естественным является компилятивный синтез, предполагающий вырезание сегментов из естественной речевой последовательностей, их последующую обработку и склейку. Цифровая обработка речевого сигнала позволяет решить задачи изменения частоты основного тона и длительности фрагмента сигнала.
Изменение длительности фрагментов речевого сигнала решается достаточно простыми способами, и зависит от типа звука. Изменение длительности паузы или смычки у глухих взрывных достигается добавлением участка с нулевой амплитудой для увеличения длительности или удаления части смычки или паузы, для сокращения. Изменение длительности щелевых согласных осуществляется удалением / копированием фрагментов шума нужной длительности. Длительности звонких согласных и гласных осуществляется путем размножения / выбрасывания периодов определенных основного тона.
Наиболее сложной задачей является изменение частоты основного тона. В настоящее время для ее решения применяются различные методы. На первый взгляд самыми естественными способами изменения ЧОТ представляются LPC-преобразование и преобразование Фурье. Однако, оба они вносят существенные искажения в сигнал, приводящие к потере естественности и искажению перцептивных характеристик, и требуют разработки специальных средств качественного восстановления модифицированного сигнала.
Наиболее простым способом изменения ЧОТ является добавление отсчетов с нулевой амплитудой для понижения и, соответственно, выбрасывание отсчетов для понижения ЧОТ в конце периода11. Недостатком данного метода является низкие пределы изменения ЧОТ и высокие искажения звука.
Наиболее распространенным алгоритмом изменения ЧОТ является TD-PSOLA12 (Time-Domain Pitch Synchronous-Overlap-and-Add), использующий оконную обработку сигнала и требующий точного выделения периодов основного тона. PSOLA обеспечивает высокое качество модифицированного сигнала, но существенно искажает тембр голоса, что снижает естественность синтезированной речи.
Известны и модифицированные версии алгоритма PSOLA13, использующие разделение сигнала на шумовой и голосовой компоненты, для лучшего сохранения индивидуальных характеристик голоса и приближения модифицированного сигнала к естественному.
Сущность предлагаемой разработки
Общие положения
Язык состоит из звуков. Каждый человек генерирует уникальный набор звуков. Однако, можно выделить типовых дикторов (ТД), производящих усредненные типы звуков. ТД группируются по возрасту, полу, регионам, социальному положению, образованию, роду деятельности и т. д.
Для ТД нужно определить частотности звуков, и вероятности их следования друг за другом, интонационные контуры, словари, физические характеристики отдельных звуков. На основе этих данных можно моделировать естественный речевой поток.
В систему также нужно включить статистическую информацию о составе населения, и с ее помощью генерировать речевые потоки с характеристиками, соответствующими населению, проживающему в к/л регионе или стране в целом.
Грубо говоря, статистическая модель должна объединить в себе статистические данные о составе населения, речевые базы ТД, средства обработки речевого сигнала (алгоритмы синтеза), средства для определения параметров звуков речи, алгоритмы генерации распределений звуков и дикторов. В ниже раскрывается то, как мы это себе представляем и пытаемся реализовать.
Общая структура статистической модели
Общую структуру модели можно представить в виде следующего рисунка:
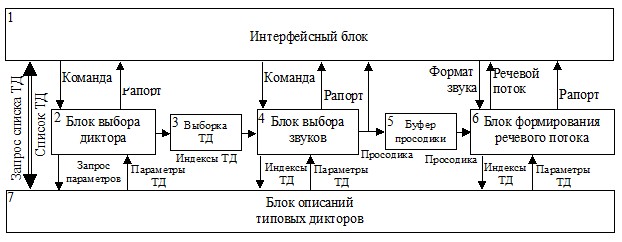
Рис.1. Укрупненная структура статистической модели.
Интерфейсный блок (блок №1) обеспечивает взаимодействие с внешним миром (или Пользователем). Блок №1 также осуществляет синхронизацию работы остальных блоков статистической модели.
Блок выбора диктора (блок №2) осуществляет генерацию выборки ТД (или последовательности индексов ТД). В зависимости от команды может быть сгенерирована либо представительная выборка ТД, либо выборка, состоящая из одного ТД. Представительная выборка является представительной в том смысле, что распределение параметров речи в выборке, будет соответствовать распределению параметров речи населения, описываемого моделью.
Сформированная последовательность идентификаторов ТД сохраняется для дальнейшего использования в блоке выборки ТД (блок №3).
Блок выбора звуков (блок №4) формирует просодику (описания звуков). В зависимости от команды просодика формируется либо для представительной выборки звуков, либо для заданной последовательности звуков, либо для одного заданного звука.
Просодика сохраняется в буфере просодики (блок №5) до дальнейшего использования.
Блок формирования речевого потока (блок №6) преобразует описания звуков в отсчеты звукового сигнала.
Блок описаний ТД (блок №7) хранит описания ТД и возвращает по запросу: необходимые части описаний, информацию об их количестве, список дикторов.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
