


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Статистическая модель речи не является вещью в себе, она предназначена для работы в составе различных систем, в которых требуется моделировать речевой поток, являющихся Пользователями модели.
Итак, Пользователь может выполнять запросы следующих типов:
запрашивать список типовых дикторов (ТД), представленных в модели; синтезировать отдельные звуки голосом любого ТД; синтезировать цепочки звуков голосом любого ТД; генерировать звуковой поток, характеризующий одного ТД; генерировать звуковой поток, характеризующий население, описываемое моделью; отменять генерацию звукового потока.Не будем рассматривать порядок взаимодействия блоков, образующих статистическую модель, которая представляется прозрачной. Рассмотрим подробнее структуру блоков.
Блоки №№ 3 и 5 представляют собой обыкновенные очереди FIFO для хранения промежуточных данных и не имеют сложной структуры, требующей дополнительного описания.
Блок №7 представляет собой базу данных, содержащую описания ТД, и средства для доступа к ней.
Блок №2 – блок выбора дикторов
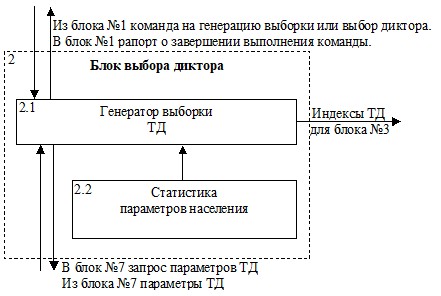
Рис.2. Блок выбора дикторов.
При генерации представительной выборки блок выбора диктора получает статистические данные об описываемом моделью населении (модуль №2.2): регион, возрастно-половой состав, уровень образования, говор/диалект, и род деятельности. Часть описаний ТД (блок №7), используемая модулем, состоит из диапазонов значений статистических параметров, позволяющих определить процент населения, соответствующий каждому ТД, и включать ТД выборку в количестве, пропорциональном составу населения.
Определив сколько каких типовых дикторов нужно включить в выборку, блок выбора диктора выдает в случайном порядке их индексы в блок №3 на хранение.
После того, как все необходимые индексы сохранены, блок рапортует интерфейсному блоку о завершении выполнения команды.
При выборе одного конкретного диктора блок выбора диктора просто передает его индекс на хранение в блок №3 и рапортует о завершении работы.
Блок №4 – блок выбора звуков
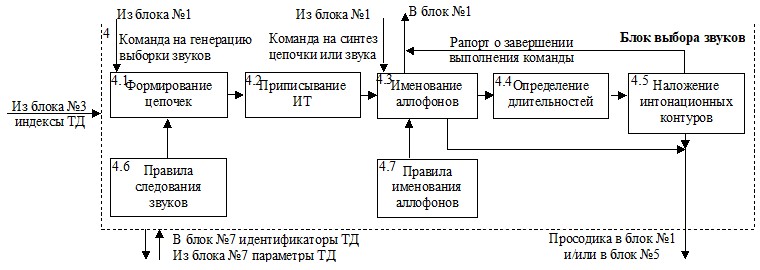
Рис.3. Блок выбора звуков.
Блок выбора звуков работает в одном из двух режимов: режиме генерации распределения и режиме синтезатора, когда звук/звуки и параметры выдаются интерфейсным блоком. Рассмотрим режимы подробнее.
В режиме генерации распределения для каждого ТД (индексы которых берутся из блока №3) формируются выборки звуков с параметрами (работает модуль 4.1), как и в речи ТД. Для этого из блока описаний ТД (блок №7) по индексу берется информация о частотности звуков, и, с учетом правил следования (модуль №4.6), подготавливаются цепочки звуков от паузы до паузы. Длины цепочек также определяются параметрами ТД.
Если по какой-то причине в параметрах ТД отсутствует информация о частотности звуков или длинах цепочек, то используются статистические данные, полученные на большом объеме текстов. Средняя статистика является частью блока описаний ТД.
Каждой цепочке приписывается интонационный контур (модуль №4.2). Параметры интонационных контуров и информация об их используемости в речи берутся из описаний ТД. Если параметры интонационных контуров или распределения длительностей звуков, или энергии отсутствуют в описании данного ТД, берутся среднестатистические значения, являющиеся частью блока описаний ТД.
С учетом контекстов (звуков слева и справа) и правил именования аллофонов (модуль 4.7) названия звуков преобразуются в имена аллофонов в модуле 4.3.
Для всех звуков цепочки на основе информации о параметрах ТД приписываются длительности и энергии (модуль 4.4). После чего производится наложение интонационного контура. В результате применения интонационных контуров к цепочкам звуков (модуль 4.5), для каждого звука определяется основной тон.
В результате на выходе модуля 4.5 известны все необходимые просодические параметры: длительность, основной тон, энергия и идентификатор ТД. Сформированная просодика сохраняется в блоке №5.
Распределение просодических параметров звуков в цепочках, совпадает с распределением в реальной речи.
В режиме синтезатора на вход блока выбора звуков поступают либо отдельные звуки, либо цепочки звуков от паузы до паузы. В случае выбора отдельного звука, все просодические параметры (длительность, ЧОТ, энергия) указываются блоком №1. Блок №4 лишь именует аллофон, используя контекст «пауза»-«звук»-«пауза», передает описание на хранение в блок №5.
В случае генерации последовательности звуков блок №4 сформирует просодику в соответствии с параметрами интонационного контура, определит названия аллофонов и передаст их на вход Блока №5. После чего рапортует об исполнении команды.
Процедура определения длительностей звуков, будет отличаться от процедуры, используемой в режиме генерации выборки. Если при генерации выборки, длительности звуков определяются статистическим распределением, то в режиме синтезатора используются строгие правила и центральные значения распределений. Правила определения длительностей определяются конкретной реализацией.
Блок №6 – блок формирования речевого потока
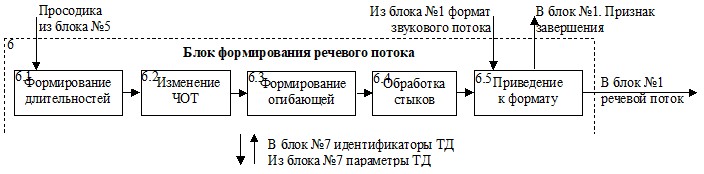
Рис. 4. Блок формирования речевого потока.
Блок формирования речевого потока, получив просодику (из блока №5) и формат звукового потока (из блока №1), извлекает из описания ТД (из блока №7) образцы звуков с разметкой. Каждый звук приводится к длительности, определенной параметрами просодики в модуле №6.1. Для звуков разных типов разработаны разные алгоритмы (стратегии) изменения длительности, учитывающие особенности структуры и восприятия звуков, обеспечивающие минимальные искажения качества14 звуков.
После того, как длительности аллофонов сформированы, они приводятся к заданным частотам основного тона в модуле 6.2, причем ЧОТ не остается постоянной на всем аллофоне, а изменяется в соответствии с движением, заданным в просодических параметрах. Чтобы минимизировать искажения звуков, модификация ЧОТ звуков разных типов проводиться с использованием различных алгоритмов, построенных на базе PSOLA.
Далее, с учетом параметров энергии, заданных в просодике, формируется амплитудная огибающая звуков цепочки (модуль 6.3), и производится морф стыков звуков, для минимизации шумов на стыках (модуль 6.4).
Звуковой сигнал приводится к формату, указанному блоком №1 и передается ему для последующего использования. Преобразование формата звукового сигнала производится в модуле №6.5
Преимущества предлагаемого решения
Если сравнивать с речевыми базами, то преимуществами будут:
- больший объем исходного речевого корпуса; использование большего количества классификационных признаков при сегментации и описании речевого корпуса; включение в базу дополнительной статистической информации по каждому ТД; наличие описаний интонационных контуров для каждого ТД; возможность одновременной работы со структурными элементами разного размера и формата.
Если сравнивать с системами синтеза, использующими различные алгоритмы обработки звуков и звуковые базы данных, то можно выделить следующие преимущества:
- специально разработанные алгоритмы изменения длительности звуков разных типов, минимизирующие искажение перцептивных свойств звуков; специально разработанные (или модифицированные) алгоритмы изменения ЧОТ звуков разных типов, минимизирующие искажение их перцептивных свойств; возможность выбирать из базы звуки, (или, даже, цепочки звуков), требующие наименьшей модификации; разнообразие контекстных реализаций звуков позволит синтезировать речевой поток, обладающий высокой естественностью; достижение высокой естественности за счет применения интонационных контуров, специально подобранных для каждого ТД.
Преимуществом также можно считать возможность относительно быстрой разработки упрощенной модели, обладающей всеми алгоритмами, и перестающей быть «упрощенной» по мере наполнения данными.
Можно назвать еще одно преимущество статистической модели – она не зависит от языка. Язык, с которым будет работать модель, определяется лишь теми данными, которыми наполнена модель, а все алгоритмы и интерфейсы сохранятся. В будущем можно будет подумать о создании не «статистической модели русского языка», а «статистической языковой модели», охватывающей все живые языки мира. Однако, это скорее из области фантастики.
Области применения
Область применения статистической модели крайне широка. Статистическая модель может быть востребована во всех областях науки и техники, связанных с передачей, обработкой, сжатием и хранением, синтезом и распознаванием речевых сигналов. Остановимся на некоторых возможных применениях статистической модели.
Синтез речи
Статистическая модель может быть использована при построении системы высококачественного синтеза русской речи по тексту. Под высоким качеством подразумевается высокая естественность и разборчивость синтезируемой речи.
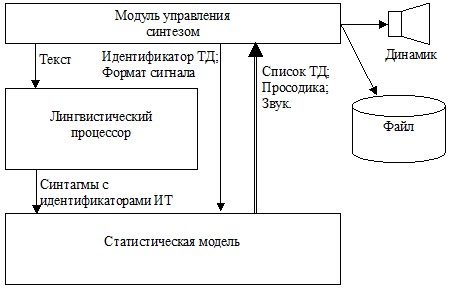
Рис.5. Статистическая модель в системе синтеза речи
Работа системы синтеза осуществляется по следующей схеме (рис. 5): Модуль управления запрашивает у Статистической модели список ТД. Затем выбирает одного ТД из списка, и задает формат звукового сигнала. Затем модуль управления передает синтезируемый текст лингвистическому процессору (ЛП). ЛП разделяет текст на синтагмы, приписывает им ИТ, проставляет ударения и транскрибирует их, после чего передает синтагмы и их ИТ статистической модели.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
