


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 007:519.816
перспективные СИСТЕМЫ УПРАВЛЕНИЯ на ОСНОВЕ подкреплённого обучения с использованием гибких алгоритмов *
, 1
Описывается метод построения системы группового регулирования выдачи мощности на базе подкрепленного обучения и гибких алгоритмов. Рассматриваются способы комбинации данных методик и возможность их совместного использования в перспективной системе автоматизированного управления гидроэлектростанциями.
Введение
Самым перспективным источником энергии на сегодняшний день являются водные ресурсы ввиду своей восполнимости, безопасности, эффективности преобразования механической энергии в электрическую. В настоящее время в нашей стране сложилась ситуация, когда созданные в середине прошлого столетия гидроэлектростанции начинают исчерпывать заложенный в них ресурс, а новых, современных ГЭС в последние 18 лет построено не было, поэтому ликвидировать недостаток электроэнергии, вызванный остановом отслуживших свой век станций не представляется возможным. Ввиду возможного энергетического кризиса министерством энергетики России предпринимаются активные меры по возрождению гидроэнергетики и вкладываются значительные средства в разработку гидростанций нового образца. Это касается и усовершенствования технологий преобразования энергии, и, особенно, улучшения систем автоматизированного управления, основы которых были заложены ещё в 60-70-е годы и не менялись десятки лет.
В рамках данной задачи в Московском Энергетическом Институте был разработан и запущен на реальных гидростанциях генератор нового типа, переворачивающий классические представления о работе ГЭС и дающий несравненно более широкие возможности по автоматизированному и даже автоматическому (без участия человека) управлению работой электрической станции. Создание интеллектуальной системы управления позволит значительно повысить качество вырабатываемой станцией энергии, увеличить срок её эксплуатации и сократить издержки на неё. Главным требованием к такой системе является её адаптация к изменяющимся условиям работы. Данная статья посвящена исследованиям в данном направлении.
1. Задача группового регулирования выдачи мощности
Эффективность работы станции можно математически описать набором кривых, называемых универсальными характеристиками. Они представляют собой зависимости друг от друга основных рабочих параметров работы турбины (напор и расход воды, коэффициент полезного действия, скорость вращения колеса и т. д.). На примере характеристики «напор-расход-кпд» (рис.1) можно наглядно продемонстрировать преимущества разработанного генератора.
|
Рис. 1. Универсальная характеристика турбины |
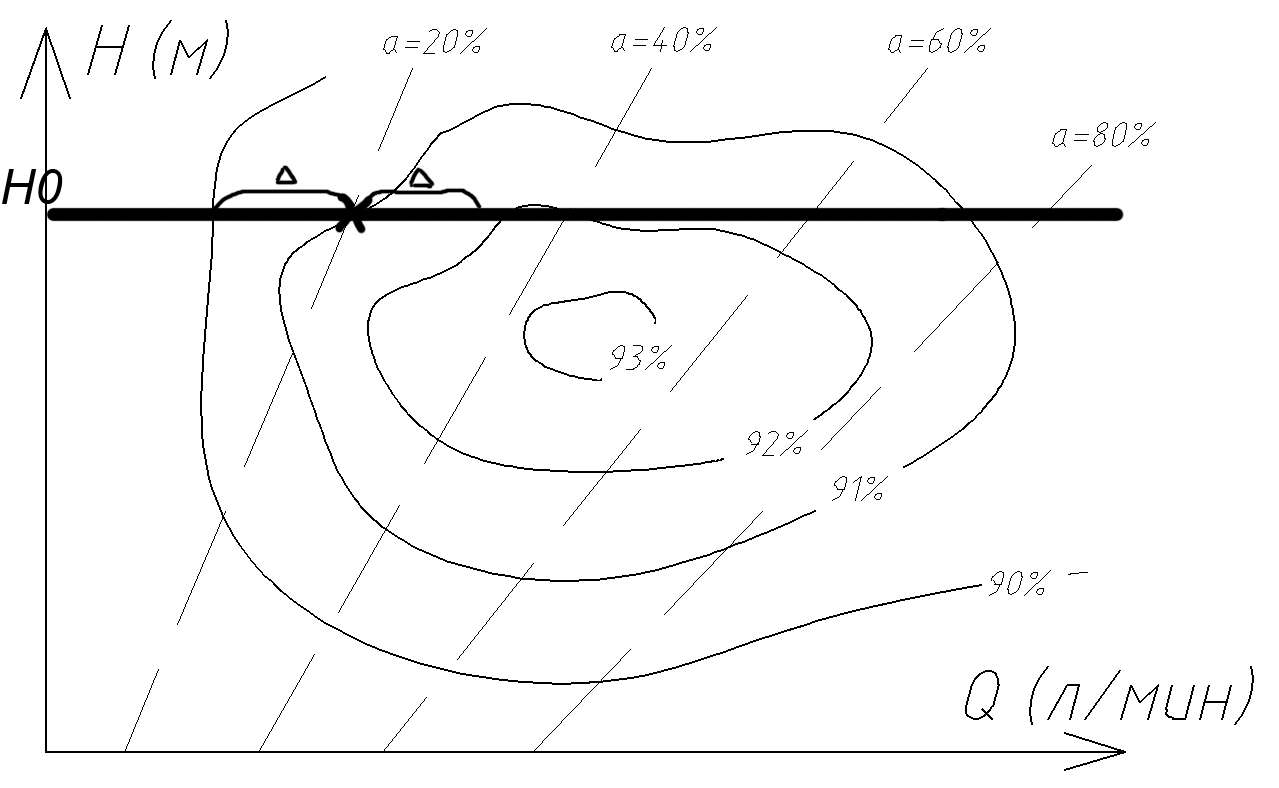
На данной характеристике можно увидеть, какой КПД достигается на турбине при некотором напоре H и расходе Q. В единицу времени можно считать напор воды H постоянным и равным H0, тогда через агрегат за минуту протекает Q литров воды, определяемое углом открытия a направляющего аппарата. Величина этого угла для классического синхронного генератора однозначно определяется размером нагрузки со стороны потребителя ввиду требования о постоянстве угловой скорости вращения V0. Таким образом, в любой заданный момент времени генератор выдаёт потребителю энергию далеко не в оптимальном режиме (в точке пересечения X (a=20%; кпд=90.8%). Разработанный индукторный генератор лишён ограничения постоянства скорости и может выдавать одну и ту же мощность в диапазоне скоростей вращения (0.5V0; 1.2V0). При скорости, отличной от V0, расход воды через турбину изменяется, что даёт возможность подобрать такую скорость вращения, которая сможет, во-первых, максимизировать кпд турбины (в Д-окрестности точки X он достигает 92%), а, во-вторых, обойти зоны повышенных вибраций. Это достигается в том числе использованием специального шкафа преобразователей, управляемого электроникой, что позволяет системе управления получить полный контроль над процессами, протекающими на станции, и возможность контролировать их.
Данная возможность особенно сильно проявляется в задаче группового регулирования выдачей мощности. Проблема заключается в том, как распределить энергию, вырабатываемую несколькими агрегатами одной станции таким образом, чтобы оптимизировать работы этих агрегатов по тем или иным критериям, минимизировав при этом риски, износ систем, вероятность возникновения аварийных ситуаций. Например, одна из построенных ГЭС состоит из четырёх одинаковых агрегатов мощностью 600 кВт каждый. Небольшой город (до 50 тыс. населения) потребляет в среднем 1500 кВт энергии, но в часы пик эта цифра возрастает до 2300 кВт (рис.2)
|
|
Рис. 2. Потребление электроэнергии в течение суток | Рис.3. Среднесуточное потребление электроэнергии в течение года |
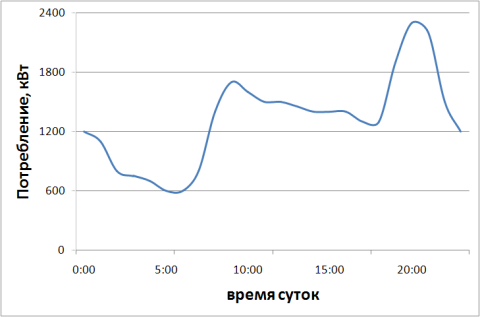
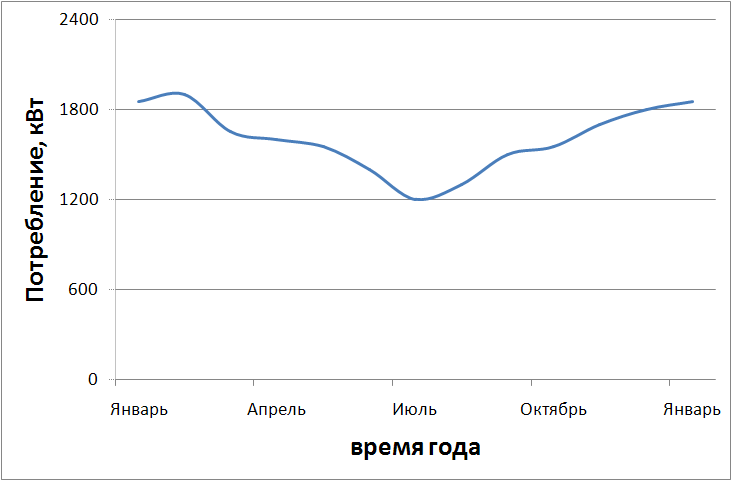
Очевидно, что ежеминутно необходимо принимать решение, сколько энергии должен вырабатывать каждый генератор, чтобы суммарный КПД станции был максимальным, какой необходимо включать в работу при необходимости и какой выключать за ненадобностью. Задача существенно осложняется также сезонными изменениями потребления энергии (рис.3) и износом оборудования. На современных станциях нагрузка между синхронными генераторами распределяется равномерно, что приводит к их работе с суммарным КПД намного меньшим оптимального, который можно достичь за счёт рационального распределения мощности между индукторными генераторами.
Может показаться, что с данной задачей можно справиться методами математичекой оптимизации, предварительно рассчитав в соответствии с математической моделью возможные комбинации выдачи мощности каждым агрегатом и соответствующие этим состояниям КПД, однако реалии таковы, что каждый агрегат уникален и, во-первых, может существенно отличаться от своей математической модели, а, во-вторых, его характеристики неизбежно и непредсказуемо меняются с течением времени, приводя к тому, что детерминированный алгоритм перестаёт удовлетворять потребностям.
По этим причинам решение поставленной задачи должно основываться на эвристических методах, базирующихся на учете специфики проблемной области, знаниях и опыте специалистов, решающих подобные задачи. Предлагается использовать подход, примененный для разработки систем поддержки принятия решений (СППР) реального времени семиотического типа [Еремеев, 2004].
СППР семиотического типа формально может быть задана набором
SS = <M, R(M), F(M), F(SS)>,
где:
- M={M1,…,Mn} – множество формальных или логико-лингвистических моделей, реализующих определенные интеллектуальные функции; R(M) – множество правил выбора необходимой модели или совокупности моделей в текущей ситуации, т. е. правил, реализующих отображение R(M): S→M, где S –множество возможных ситуаций (состояний), которое может быть и открытым, или S'→M, где S' –некоторое множество обобщенных ситуаций (состояний), например, нормальных (штатных), аномальных или аварийных (критических), при попадании в которые происходит смена модели; F(M)={F(M1),…,F(Mn)} – множество правил модификации и адаптации моделей Mi, i=1,…,n. Каждое правило F(Mi) реализует отображение F(Mi): S''×Mi→M'i, где S''⊆S, M'i – некоторая модификация (адаптация) модели Mi; F(SS) – правило модификации собственно системы SS – ее базовых множеств M, R(M), F(M) и, возможно, самой F(SS), т. е. F(SS) реализует целый ряд отображений (или комплексное отображение) F(SS): S'''×M→M', S'''×R(M)→R'(M), S'''×F(M)→F'(M), S'''×F(SS)→F'(SS), где S'''⊆S, S'''∩S'=∅, S'''∩S''=∅, т. е. правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для принятия решений в сложившейся проблемной ситуации. Причем для модификации F(SS) могут быть использованы как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации.
Поиск (вывод) решения в рамках индивидуальной модели Mi поддерживается правилами монотонного или, при необходимости, немонотонного и нечеткого вывода. Переход с одной модели на другую или модификация модели ведет, как правило, к нарушению монотонности. Этот переход осуществляется посредством реакции на соответствующее событие (проблемную ситуацию) или посредством выполнения определенных правил, например, правил нечеткого вывода типа A'●(A→B), где A' и A - нечеткие множества, описывающие состояния проблемной области или объекта (между элементами из A и A' должно быть определено нечеткое отношение сходства), B - нечеткое множество допустимых моделей или модификаций в рамках используемой модели, ● - заданная определенным образом операция композиции нечетких множеств.
Основа конструирования любой СППР – выбор подходящего формального аппарата для описания процесса принятия решений и построение на его базе адекватной (корректной) проблемной области модели принятия (поиска) решений [Вагин и др., 2001].
2. Подкреплённое обучение
В качестве адекватного аппарата для данной задачи может выступить подкреплённое обучение (Reinforcement Learning) – мощный формализм для представления последовательных задач принятия решений для агентов, действующих в условиях неопределённости [Whitehead et al., 1995; Еремеев и др., 1999]. Подкреплённое обучение – это парадигма машинного обучения, хорошо подходящая для обучения роботов и агентов управления в СППР реального времени. Базовая модель подкрепленного обучения предполагает, что мир может быть описан набором состояний S, агент может выполнять фиксированный набор действий A и после выполнения действия в заданном состоянии среда предоставляет агенту выплату согласно отображению ![]() . Эта выплата отражает, насколько хорошо (в весьма локальном смысле) выполнять это действие в данном состоянии. Для динамических проблемных областей (типа рассматриваемой) условие полноты и достоверности поступающей информации не выполняется. Это может обуславливаться различными факторами, например: выходом из строя датчиков, неполным учётом внешних воздействий, неполнотой и противоречивостью базы знаний, ошибками оперативно-диспетчерского персонала (далее ЛПР – лицо, принимающее решение). В этих условиях необходимо использовать немарковскую модель принятия решений, обладающую памятью и позволяющую учитывать предысторию изменения ситуации [Подогов и др., 2006].
. Эта выплата отражает, насколько хорошо (в весьма локальном смысле) выполнять это действие в данном состоянии. Для динамических проблемных областей (типа рассматриваемой) условие полноты и достоверности поступающей информации не выполняется. Это может обуславливаться различными факторами, например: выходом из строя датчиков, неполным учётом внешних воздействий, неполнотой и противоречивостью базы знаний, ошибками оперативно-диспетчерского персонала (далее ЛПР – лицо, принимающее решение). В этих условиях необходимо использовать немарковскую модель принятия решений, обладающую памятью и позволяющую учитывать предысторию изменения ситуации [Подогов и др., 2006].
В рассматриваемой задаче при взаимодействии со средой такой агент будет постепенно "изучать" ситуацию, пользуясь некоторой внутренней стратегией, которая со временем может изменяться и адаптироваться, чтобы в конечном итоге для любого момента времени максимизировать так называемый возврат среды, т. е. дисконтированную сумму платежей, получаемых агентом с текущего момента:
![]() ,
,
где г – временной множитель скидки (константа между 0 и 1), ri –выплата на i-м шаге. Множитель скидки отображает, сколько уделять внимания выплатам, которые могут встретиться в будущем. Поскольку процесс принятия решений может быть вероятностным, задача агента – найти стратегию, максимизирующую ожидаемый возврат.
Итак, ключевым элементом подкреплённого обучения является функция вознаграждений R, дающая действительное число (ожидаемую немедленную выплату) по начальному состоянию и выполненному агенту действию. Выбор такой функции не тривиален, та как она зависит от огромного множества факторов, не всегда поддающихся учёту, что делает невозможным использование строгого математического аппарата. Единственным приемлемым решением является использование методов искусственного интеллекта (ИИ). Необходимо принять качественное решение в условиях неполной информации и реального времени. Особенностью подходящего алгоритма является то, что в обычных условиях работы станции, когда ситуация в сети меняется очень медленно, он обладает достаточно большим временем на принятие решения, и можно потратить дополнительные вычислительные ресурсы для того, чтобы увеличить точность функции вознаграждения. И, наоборот, в случае возникновения ситуации, близкой к аварийной или аварийной, когда некоторые параметры выходят за пределы допустимого или стремительный рост нагрузки со стороны потребителя может привести к отключению всей станции, необходимо принимать решения с максимально возможной скоростью, возможно, жертвуя качеством получаемого решения.
3. Гибкие алгоритмы поиска решения
Такой класс алгоритмов существует и известен как «гибкие» алгоритмы (anytime-algorithms) [Boddy et al., 1989]. Качество результатов, найденных гибким алгоритмом, улучшается с увеличением времени работы алгоритма [Zilberstein, 1993]. Используя их, реально построить СППР реального ремени, способную находить компромисс между качеством результатов и временем вычислений. Гибкий алгоритм осуществляет поиск решения итеративно, улучшая качество решения с течением времени и предоставляя пользователю возможность при необходимости прервать процесс поиска результата. Такие алгоритмы можно выполнять двумя способами: либо с заранее предусмотренным лимитом времени выполнения (contract time), либо с возможностью останова в любой момент времени (interruptible method). Алгоритмы обоих типов всегда можно продолжить после того, как они были остановлены (либо по истечении лимита времени, либо из-за прерывания), и продолжить поиск более хорошего решения.
Центральную роль в anytime-системах играет мониторинг. Он позволяет изменять время, выделяемое на работу anytime-компонентов в процессе реального времени. Находимое алгоритмом решение в условиях экстренной ситуации представляет ценность только в случае быстрого его получения и бесполезно, будучи полученным через больший, чем требуемый, интервал времени [Hansen et al., 2004].
Учитывая сказанное, предлагается следующая структура разрабатываемой СППР, являющейся основой автоматизированной системы управления (рис.4).
|
Рис. 4. Архитектура «гибкой» СППР |
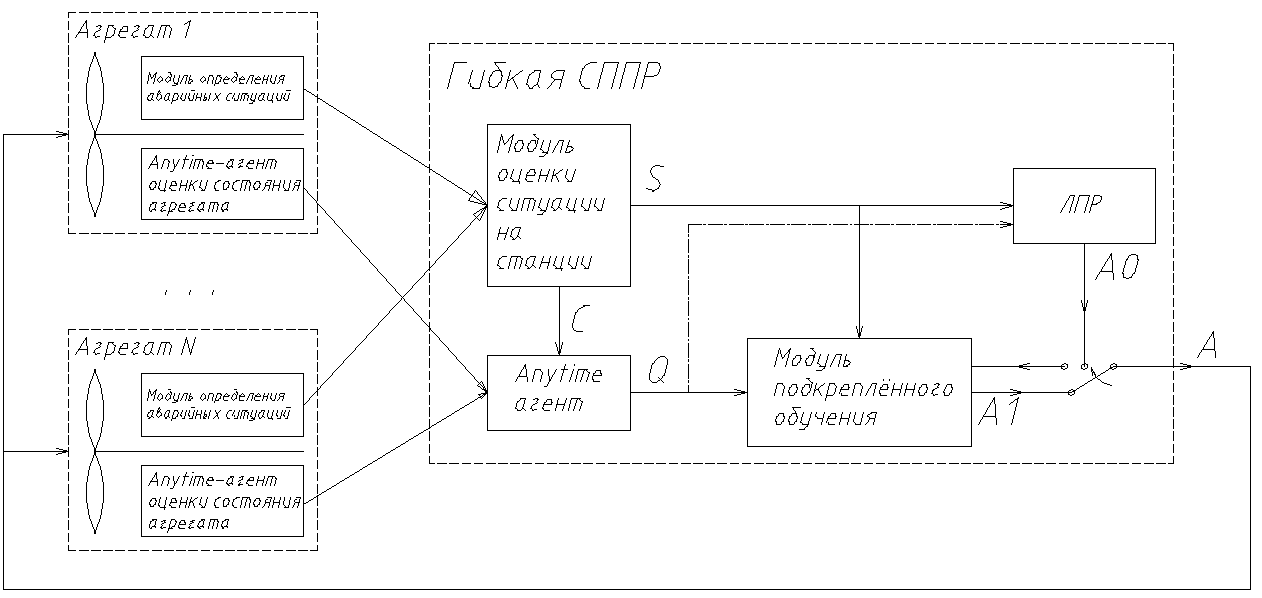
Вводится агент оценки общей ситуации на объекте (станции). Он оценивает стабильность состояния нагрузки, работают ли агрегаты в нормальном режиме, получая данную информацию от внутренних вагентов. Существует главный anytime-агент, который производит оценку текущего состояния станции, основываясь на общей информации и на информации, получаемой от агентов на каждом агрегате. Этим достигается распределённость СППР и её большая эффективность. Если состояние стабильно, anytime-агенту на поиск решения отводится большее время. В случае возникновения чрезвычайных ситуаций или резких изменений, модуль оценки ситуаций сокращает время, отводимое anytime-агенту, стараясь получать более грубые оценки с большей частотой. Полученные оценки передаются в модуль подкреплённого обучения, который на основе накопленных знаний принимает решение о дальнейших действиях, основываясь на текущем состоянии S и оценке Q. Первоначально данный модуль может работать в режиме обучения оператором, анализируя его действия A0 и результаты, ими вызываемые, а может работать и в режиме самообучения A1, находя оптимальный режим управления станцией методом проб и ошибок.
Использование координирующего модуля позволяет построить более эффективную СППР, способную перераспределять приоритеты в реальном времени и получать более качественные результаты. В данный момент ведутся работы по созданию этого модуля-координатора, связывающего все остальные в единую систему. Разрабатывается интерфейс взаимодействия компонентов этой системы, алгоритм определения оптимального времени для работы anytime-агента и согласуются наборы возможных состояний и действий, на основе которых можно построить адекватную модель для проверки созданной СППР в лабораторных условиях на имитационной модели. Проводятся исследования в направлении усовершенствования модуля подкреплённого обучения [Подогов и др.,2006].
Заключение
В работе рассматривается задача создания СППР реального времени для автоматизации процесса управления, позволяющей существенно повысить коэффициент полезного действия современных гидроэлектростанций. Разработана структура такой системы с использованием гибких алгоритмов и подкреплённого обучения. Использование самообучающихся систем даёт несомненный плюс для дальнейшего развития гидроэнергетики. Подобную систему управления можно внедрять на небольших станциях, для которых не существует предварительной статистической информации, и обучающийся агент со временем самостоятельно подберёт все необходимые параметры своей работы, обеспечивая эффективное принятие решений по управлению объектом.
Список литературы
[Еремеев, 2004] Об интеграции моделей в интеллектуальных системах поддержки принятия решений // Тр. Девятой национальной конф. по искусственному интеллекту с международным участием (КИИ-2004). В 3-х томах. Том 2. - М.: Физматлит, 2004.
[Вагин и др., 2001] , Еремеев базовые принципы построения интеллектуальных систем поддержки принятия решений реального времени // Изв. РАН. Теория и системы управления. 2001, № 6.
[Whitehead et al., 1995] Whitehead S. D., Lin Long-Ji. Reinforcement Learning of Non-Markov Decision Processes // Artificial Intelligence. 1995. Vol. 73.
[Еремеев и др., 1999] , , Шутова принятия решений в условиях неопределенности на основе немарковской модели // Изв. РАН. Теория и системы управления. 1999, № 5.
[Подогов и др., 2006] , Еремеев подкрепленного обучения для систем поддержки принятия решений реального времени // Тр. Междунар. научно-техн. конф. «Информационные средства и технологии». 17-19 октября 2006 г., в 3-х т. т., Т.3. – М.: Янус-К, 2006.
[Boddy, et al., 1989] Boddy, M., Dean, T. L Solving time-dependent planning problems. // In Proceedings of the Eleventh International Joint Conference on Artificial Intelligence, pp. 979-984, Detroit, Michigan, 1989
[Zilberstein, 1993] Zilberstein S. Operational Rationality through Compilation of Anytime Algorithms. // Ph. D. dissertation, Computer Science Division, University of California at Berkley, 1993.
[Hansen et al., 2004] Hansen. E., Zilberstein S. Monitoring the Progress of Anytime Problem-solving. // In Proceedings of the 22st International Conference on Machine Learning, 2004.
* Работа выполнена при финансовой поддержке РФФИ (проект № 08-01-00437)
* Работа выполнена при финансовой поддержке РФФИ (проект № 08-01-00437)
1 111250, Москва, , МЭИ (ТУ), *****@***ru
