

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ApplicationFinisher своим методом needToFinishApplication отвечает, нужно ли завершить приложение. Возможные варианты: вся работа выполнена, истек таймаут.
ResultUnloader осуществляет выгрузку результата в нужную форму.
Для возможности специализировать объекты на этапе работы приложения используется две абстрактные фабрики:
ObjectCreator - создание базовых объектов (потомки ApplicationManager, DataManager ParsingThread, DownloadingThread, RoutineThread).
HelperCreator - абстрактная фабрика по созданию вспомогательных объектов.
1.4. Конфигурация RCCrawler для решения поставленной задачи
В качестве ApplicationManager используется TextFileAM. Алгоритм его работы:
Создать и настроить реализации DataManager, DownloadingThread, заданное количество ParsingThread, RoutineThread, несколько реализаций ApplicationFinisher согласно файлу settings. ini. Прочитать файл hosts. txt в качестве источника сайтов для сканирования. Для каждого сайта получить правила из robots. txt и поместить стартовую страницу в DataManager. Запустить потоки, определенные в пункте 1. Проверять в цикле с помощью реализаций ApplicationFinisher необходимость завершить приложение. В случае положительного ответа от одного из ApplicationFinisher'ов произвести выгрузку результата с помощью реализаций ResultUnloader, указанных в settings. ini. Завершить приложение.DownloadingThread в используемой конфигурации представлен классом DT0, который асинхронно загружает страницы используя QNetworkAccessManager и сигнально-слотовую систему Qt. Упрощенный цикл работы:
1. Обработать события. То есть принять сигналы и вызвать связанные слоты.
2. Запросить у DataManager коллекцию PageData для скачивания по каждому сайту.
3. По каждому сайту поставить данные на загрузку, если свободные соединения.
4. При определенных условиях отправить данные по которым произведена загрузка на обновление в DataManager.
ParsingThread представлен классом PT0. Упрощенный цикл работы:
Получить коллекцию PageData для разбора у DataManager. Для каждой PageData: Поставить поле parsed в true. Разобрать content на ссылки. По каждой ссылке: Проверить является ли она внутренней. Если нет, то повысить outDegree. Если да, то нормализовать ссылку и добавить в выходную коллекцию PDAndPACreateData (вспомогательная структура для обработки внутри DataManager и создания соответствующих данных). Отправить выходную коллекции PDAndPACreateData на вставку в DataManager. Отправить входную коллекцию PageData в DataManager на обновление.RoutineThread представлен классом RT0. Его единственной функцией является логирование.
Доступны три реализации ApplicationFinisher: WorkIsDoneAF, TimeoutAF и StopFileAF. Первый возвращает true в методе needToFinishApplication если у DataManager нет PageData для скачивания и обработки, второй по истечению таймаута. Так как прием пользовательского ввода во время работы невозможен по причине активного вывода информации по скачанным страницам и ошибкам, в качестве средства внешнего завершения приложения был разработан StopFileAF, который проверяет появление файла с заданным именем в каталоге приложения и сигнализирует о необходимости остановки в случае наличия.
GephiSiteGraphRU является используемой реализацией ResultUnloader. Выгружает данные в формате для построения графа в Gephi.
В качестве DataManager используется BMICDM (Boost Multi-Index Container Data Manager). Для хранения структур PageData и PageArc используется Boost Multi-index Container Library2. Multi-index сontainer представляет из себя нечто вроде таблицы базы данных в памяти, доступ в которой осуществляется по индексам по полю или набору полей, и эти индексы задаются на этапе компиляции. Таким образом, доступ и поиск данных в такой коллекции обладает высокой производительностью. Также, индекс может быть уникальным и вставка с нарушением уникальности не будет происходить. Все эти качества multi-index container позволяют потокам находиться в ожидании разблокировки ресурса меньшее время.
Глава 2. Исследования модулярности веб-графов сайтов
2.1. Основные определения
Веб-сайт (сайт) – совокупность html-страниц и веб-документов, связанных внутренними гиперссылками и обладающих единством содержания, идентифицируемая в Вебе по уникальному доменному имени.
Ориентированный граф — это упорядоченная пара G = (V, E), где V — непустое множество вершин, и E — множество (упорядоченных) пар различных вершин, называемых дугами (ориентированными рёбрами).
Дуга — это упорядоченная пара вершин (vi, vj), где вершину vi называют началом, а vj — концом дуги.
Матрица смежности - матрица A = [Aij] размерности nxn, где n - количество вершин графа, элементы которой определяются следующим образом:
Aij = 1, если (vi, vj) Є E,
Aij = 0 в противном случае
Инцидентность — понятие, используемое дуги и вершины: если v1, v2 — вершины, а e=(v1, v2) — соединяющее их ребро, тогда вершина v1 и ребро e инцидентны, вершина v2 и ребро e тоже инцидентны. Две вершины (или два ребра) инцидентными быть не могут. Для обозначения ближайших вершин (рёбер) используется понятие смежности.
Петля - дуга инцидентная одной и той же вершине.
Степень вершины - количество дуг, инцидентных вершине. Притом, петля учитывается дважды.
Модулярность - это метрика, разработанная с целью измерения силы разбиения графа на сообщества. Пусть произведено разбиение графа на сообщества или по-другому классы. Пусть ci - метка класса для vi.
Мера модулярности Q описывается следующей формулой:
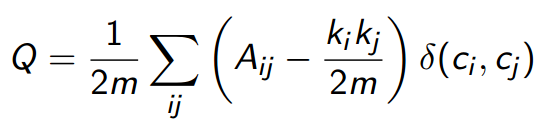
где m - количество дуг,
Aij - элемент матрицы смежности,
ki, kj - степени соответствующих вершин,
д(ci, cj) - символ Кронекера, вычисляемый по формуле:
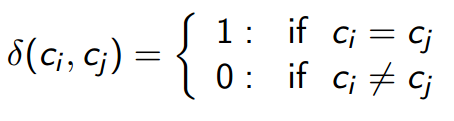
где ci, cj - метки класса соответствующих вершин.
Рассмотрим ![]()
![]() . Если мы выберем i и j такие, что вершины будут принадлежать одному классу, то, очевидно, получим ожидаемое число ребер для данного класса.
. Если мы выберем i и j такие, что вершины будут принадлежать одному классу, то, очевидно, получим ожидаемое число ребер для данного класса.
Таким образом, для выделенного сообщества мера модулярности отражает разницу между реальным количеством ребер внутри сообщества и ожидаемым.
Веб-граф сайта – ориентированный граф, в качестве вершин которого принимаются документы, а дуг – гипертекстовые ссылки между ними.
В нашем случае в качестве вершин принимаются в основном html-страницы.
В качестве оценки структурной характеристики сайта в работе принимается модулярность его веб-графа. Поскольку реальные веб-сайты могут иметь очень большую размерность, соответствующие им веб-графы также могут содержать большое количество вершин и дуг. Понятно, что количество классов в веб-графе может быть достаточно велико и классы могут иметь большие размерности.
Пусть множество вершин веб-графа сайта V разбито на s классов W1, W2, …,Wk, таких, что W1UW2U…UWk=V и Wi∩Wj для любых i, j (i≠j). Причем классы упорядочены по убыванию мощности, то есть |W1|≥|W2|≥…≥|Wk|.
Вектором модулярности для заданного разбиения V на классы
W1, W2, …,Wk будем называть вектор M=(|W1|, |W2|,…,|Wk|).
2.2. Построение вектора модулярности веб-графа сайта
Для заданного сайта с доменным именем краулер RCCrawler в качестве выходных данных генерирует два файла: первый содержит узлы веб-графа с url и другой информацией, второй содержит дуги.
Эти два файла могут быть использованы в качестве исходных данных в программном комплексе Gephi для построения и исследования веб-графа сайта. Gephi решает задачу разбиения на сообщества (модули) и вычисления значения модулярности графа. Поэтому применение краулера RCCrawler и пакета Gephi позволяет построить вектор модулярности для заданного сайта.
Таким образом, если нам задано множество, состоящее из n сайтов s1, s2, …, sn, то с использованием RCCrawler и пакета Gephi мы можем получить множество векторов модулярности M1=(|W11|, |W21|,…,|Wk11|), M2=(|W12|, |W22|,…,|Wk22|), …, Mn=(|W1n|, |W2n|,…,|Wknn|) для их дальнейшего анализа.
2.3. Кластерный анализ на множестве векторов модулярности
Теперь, считая заданным множество векторов модулярности
M1, M2, …, Mn, методами кластерного анализа решается задача разбиения множества сайтов на однородные в некотором понимании группы.
Цитируя [10], «...задача кластерного анализа заключается в том, чтобы на основании данных (об объектах), ... разбить множество объектов на m (m – целое) кластеров (подмножеств) ... так, чтобы каждый объект принадлежал одному и только одному подмножеству разбиения. А объекты, принадлежащие одному и тому же кластеру, были сходными, в то время как объекты, принадлежащие разным кластерам, были разнородными. Решением задачи кластерного анализа являются разбиения, удовлетворяющие некоторому критерию оптимальности».
Для решения задачи кластерного анализа на множестве сайтов в работе используется пробная версия пакета STATISTICA3, предоставляющая возможности, достаточные для нашего исследования.
В нашем случае был применен метод кластерного анализа Joining (tree clustering) (Объединение (двевовидная кластеризация)) с настройками пакета STATISTICA:
- для определения близости между объектами выбрано Euclidean distances (Евклидово расстояние), то есть геометрическое расстояние в многомерном пространстве;
- для определения расстояния между кластерами выбрано Single Linkage (Метод одиночной связи “принцип ближайшего соседа”), расстояние между ближайшими представителями классов.
Поскольку в нашем случае вектора модулярности могут иметь различную размерность, используется следующий метод: в качестве единой размерности выбирается максимальное значение K=max{k1, k2, …, kn}. Далее, все вектора, имеющие размерность меньше K, дополняются справа нулевыми элементами до требуемой единой размерности.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
