

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
классификация данных способом минимального расстояния и его усиление в алгоритме AdaBoost
,
Российский университет дружбы народов, *****@***com
Институт системного анализа РАН, *****@***ru
Рассматривается задача классификации данных. Используется алгоритм с последовательным обучением AdaBoost. В качестве слабых классификаторов применяются алгоритмы вычисления минимального расстояния с использованием метрики Евклида-Махаланобиса. Приведены значения ошибок классификации и эмпирические оценки количества итераций в алгоритме AdaBoost.
Ключевые слова: классификация, распознавание образов, комитетные конструкции, голосование, обучение, AdaBoost.
Введение
В рамках данной работы решается задача классификации данных различной природы с применением процедуры построения комитетов и последующего их голосования в рамках алгоритма AdaBoost. Целью работы является применение алгоритма вычисления минимального расстояния как слабого классификатора в алгоритме AdaBoost и оценка полученных результатов.
Постановка задачи
Под задачей классификации понимают задачу разделения всех объектов исходного множества на заранее заданные классы. Пусть заданы множество примеров ![]()
![]() и множество номеров классов
и множество номеров классов ![]()
![]() . Имеем пару элементов
. Имеем пару элементов 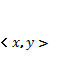
 . Будем считать, что
. Будем считать, что ![]()
![]() -
- ![]()
![]() -мерный вектор признаков. Пусть
-мерный вектор признаков. Пусть ![]()
![]() - обучающая выборка. Задача заключается в построении классификатора
- обучающая выборка. Задача заключается в построении классификатора ![]()
![]() , который для каждого элемента из пространства
, который для каждого элемента из пространства ![]()
![]() на выходе дает номер класса, к которому элемент
на выходе дает номер класса, к которому элемент ![]()
![]() относится.
относится.
Метрика Евклида-Махаланобиса
Известны алгоритмы классификации данных, в основе которых лежит применение различных метрик для вычисления расстояния от эталонных классов до заданного объекта. Объект считается принадлежащим классу, расстояние до которого минимальное.
Рассмотрим обобщенную метрику Евклида – Махаланобиса ![]()
![]() [2]. Здесь
[2]. Здесь ![]()
![]() - вектор, соответствующий классифицируемому элементу,
- вектор, соответствующий классифицируемому элементу, ![]()
![]() - эталонный класс точек,
- эталонный класс точек, ![]()
![]() - центр класса,
- центр класса, ![]()
![]() ,
, ![]()
![]() - ковариационная матрица класса
- ковариационная матрица класса ![]()
![]() ,
, ![]()
![]() - единичная матрица. Данная метрика позволяет определить расстояние от центра эталонного класса до рассматриваемого элемента.
- единичная матрица. Данная метрика позволяет определить расстояние от центра эталонного класса до рассматриваемого элемента.
Использование данной метрики позволяет учесть распределение точек в заданном классе. Она применима при малых значениях дисперсий, входящих в ковариационную матрицу. Наличие единичной матрицы обеспечивает обратимость матрицы ![]()
![]() .
.
Алгоритм AdaBoost
В данном разделе будет рассмотрен алгоритм классификации данных, основанный на применении комитетных конструкций. В процессе классификации формируется не один классификатор, а комитет из нескольких классификаторов. Решение о принадлежности элемента одному из классов принимается на основе результатов голосования элементов комитета. Идея алгоритмов семейства Boost заключается в усилении большого количества слабых классификаторов за счет объединения их в один сильный классификатор. Под слабым понимается классификатор, который правильно классифицирует объект с вероятностью немного больше ![]()
![]() . Все классификаторы обучаются на одной и той же выборке. Каждому примеру присваивается определенный вес. Обучение происходит последовательно. На следующем шаге увеличивается вес тех примеров, на которых предыдущий классификатор допустил ошибку. Каждому классификатору также присваивается вес, и чем выше его точность, тем больше вес. Ниже приведен алгоритм AdaBoost:
. Все классификаторы обучаются на одной и той же выборке. Каждому примеру присваивается определенный вес. Обучение происходит последовательно. На следующем шаге увеличивается вес тех примеров, на которых предыдущий классификатор допустил ошибку. Каждому классификатору также присваивается вес, и чем выше его точность, тем больше вес. Ниже приведен алгоритм AdaBoost:
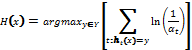
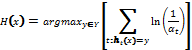 .[1]
.[1] Параметр ![]()
![]() выбирается разработчиком. Недостатком AdaBoost является его последовательное выполнение, что в значительной
выбирается разработчиком. Недостатком AdaBoost является его последовательное выполнение, что в значительной
степени замедляет вычисления.
Важным свойством алгоритма AdaBoost является возможность найти в тестовой выборке ошибки эксперта или примеры, которые находятся на границе классов. К таковым будут относится примеры с большим весом.
Результаты классификации
В рамках данной работы алгоритм AdaBoost был протестирован на различных наборах данных. В качестве слабых классификаторов применялся алгоритм минимального расстояния с использованием метрики Евклида-Махаланобиса. Все данные были разделены на обучающую и тестовую выборки. Часть этих данных используется для формирования эталонных классов. На следующем шаге в секцию в их число войдут те элементы, у которых вес будет наибольшим, то есть те, которые были неправильно классифицированы на предыдущем шаге. На основе их классификации мы определяем ошибку классификатора.
В рамках данной работы использовались данные из UCI repository[4]. Ниже, в табл. 1, приведены характеристики этих данных. Все признаки имеют числовые значения.
Таблица 1. Описание данных
Название данных | Кол-во признаков | Кол-во эталонных классов | Кол-во элементов в тестовой выборке | Кол-во элементов в обучающей выборке |
heart-disease | 8 | 5 | 294 | 39 |
german | 20 | 2 | 1000 | 38 |
breast cancer | 30 | 2 | 569 | 63 |
lung cancer | 54 | 3 | 32 | 13 |
Для всех наборов данных ошибка классификации в алгоритме AdaBoost уменьшается по сравнению с слабым классификатором. Кроме того, после определенного количества итераций ошибка стабилизируется. Исходя из этого можно сделать вывод, что параметр ![]()
![]() в приведенных экспериментах ограничивается значением 6. В табл. 2 приведены значения ошибок классификации, их процентное уменьшение и необходимое количество итераций
в приведенных экспериментах ограничивается значением 6. В табл. 2 приведены значения ошибок классификации, их процентное уменьшение и необходимое количество итераций ![]()
![]() .
.
Из всех наборов тестовых данных меньше всего точность классификации увеличилась для данных german – 2%. Это объясняется малой мощностью обучающей выборки по сравнению с тестовой. Наибольший рост – 31% наблюдается для данных lung cancer, где обучающая выборка составляет практически половину тестовой.
Таблица 2. Результаты экспериментов
Название | Ошибка Е-М | Ошибка AdaBoost | Уменьшение ошибки | Количество итераций |
heart-disease | 34% | 29% | 15% | 6 |
german | 31% | 30% | 2% | 4 |
breast cancer | 22% | 17% | 20% | 4 |
lung cancer | 40% | 31% | 23% | 3 |
Выводы
В рамках настоящей работы был реализован алгоритм классификации данных AdaBoost. Получены следующие результаты:
Наблюдается уменьшение ошибки классификации по сравнению с базовым алгоритмом на всех наборах тестовых данных. Процент уменьшения ошибки классификации зависит от характеристик исходных данных и от доли примеров обучающей выборки среди общего количества примеров. Количество итераций ограничено числом 6, что сокращает время работы алгоритма.Работа выполнена при поддержке проекта РФФИ №13-07-00025 А “Исследование методов анализа интегрированной текстовой, графической и речевой информации в системах интеллектуального управления динамическими объектами” и проекта 2.10
Литература
E. Bauer, R. Kohavi An empirical comparison of voting classification algorithms: bagging, boosting and variants // Machine Learning – 1999. p. 150-142. , Хачумов расстояние Евклида-Махаланобиса и его свойства // Информационные технологии и вычислительные системы.- № 4 2006 - с.40-44. , Гениальные комитеты умных машин // Научная сессия МИФИ-2007. 9. - Всероссийская научная конференция «Нейроинформатика-2007»: Лекции по нейноинформатике. - Часть 2. – 2007 - 148с. UCI Machine Learning Repository // URL: http://archive. ics. uci. edu/ml/index. html.Data classification using method of minimum distance and its improvement in AdaBoost
Smirnova A. I., Khachumov V. M.
Peoples’ Friendship University of Russia, , *****@***com
Institute of System Analysis of RAS, *****@***ru
We consider the problem of data classification. We use the algorithm of successive learning AdaBoost. The algorithm of minimum distance using the metrics Euclidean-Mahalanobis is used as weak classifier. The algorithm have been tested on different datasets. We produce the estimate of classification error and empirical estimate of number of iteration in AdaBoost.
Кеу words: classification, pattern recognition, committee, voting, learning, AdaBoost.
