


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Apache Storm
Apache Storm [19] и Storm/Trident были в тренде пару лет назад и были рекомендованы в качестве основы для систем потоковой обработки данных. В настоящее время их можно отнести к программным продуктам, которые нельзя использовать в высоконагруженных системах. К основным недостаткам можно отнести низкую производительность Trident, сложность настройки кластера [18][32].
Apache Spark Streaming
Apache Spark [20] является популярным фреймворком для решения задач машинного обучения. Модуль Apache Spark Streaming решает задачи потоковой обработки. Проблема Apache Spark заключается в его архитектуре, так как изначально продукт ориентирован на пакетную обработку больших данных [18][32].
Apache Flink
Apache Flink [21] способен выполнять как потоковые, так и пакетные задачи, однако для того, чтобы избежать прямой конкуренции с Apache Spark, разработчиками сделан основной акцент именно на обработку потоковых данных. Из основных достоинств работы Apache Flink можно выделить непрерывность выполнения задач без разбивки на фазы загрузки данных и их обработку [18].
Apache Kafka Streams
Kafka Streams [22] входит в состав проекта Apache Kafka. Kafka Streams это библиотека, дающая возможности выполнения операций с окнами, агрегацию данных и создавать собственные операторы для работы с данными. К недостаткам Kafka Streams можно отнести то, что продукт не является устойчивым, возможны изменения API, семантика некоторых операций отличается от других фреймворков. Также нет поддержки распараллеливания данных, масштабирования и автоматического контроля состояния [18].
Apache Samza
Apache Samza – это фреймворк для распределенной обработки потоковых данных. Используется Apache Kafka для обмена сообщениями и Apache Hadoop YARN для обеспечения отказоустойчивости, изоляции процессов, безопасности и управления ресурсами [23]. Samza позиционируется как продукт той же категории, что и Apache Storm [18].
Apache Apex
Apex – это высокопроизводительная платформа обработки данных на основе Hadoop YARN, обеспечивающая работу с потоком данных в реальном времени, а также пакетную обработку больших данных [24].
Apache Gearpump
Apache Gearpump – это фреймворк для потоковой передачи данных в режиме реального времени. В отличие от других потоковых движков, механизм Gearpump основан на событиях/сообщениях. На текущий момент находится в стадии инкубации [25].
Apache NiFi
Apache NiFi - простая платформа обработки событий предоставляющая логистику данных в режиме реального времени. Apache NiFi автоматизирует перемещение данных между разрозненными источниками данных и системами, обеспечивая быстрый, легкий и безопасный процесс получения и обработки данных [26][27].
1.3. Выводы и выбор фреймворка
Существующее многообразие различных решений для потоковой обработки данных усложняет выбор инструмента для реализации наших задач. Однако, учитывая тот факт, что с Apache NiFi можно интегрировать различные фреймворки потоковой обработки данных [28][29][30] для решения обширного круга задач, и удобство визуального управление схем процесса обработки данных - определили наш выбор.
2. ВВЕДЕНИЕ В APACHE NIFI
2.1. Описание Apache NiFi и его возможностей
NiFi был разработан для автоматизации управления потоками данных между системами. Хотя термин «поток данных» используется в различных контекстах, в Apache NiFi его использует для обозначения автоматизированного и управляемого потока информации между системами [26].
Особенности:
- Устойчив к падениям, гарантированная доставка. Быстрый отклик и высокая пропускная способность. Динамическая приоритизация. Поток может быть изменен во время выполнения. Прогнозирование данных. Отслеживание потока данных от начала и до конца. Расширяемый. Возможность создания собственных процессоров. Обеспечивает быструю разработку и эффективное тестирование. Безопасный - SSL, SSH, HTTPS, зашифрованный контент и т. д. Многопользовательская авторизация и внутренняя авторизация/ управление политиками.
2.2. Основные концепции NiFi
Основные концепции NiFi тесно связаны с основными идеями программирования потоковых данных (FBP) [26]. Некоторые из основных концепций NiFi и их сопоставление с потоко-ориентированным программированием представлены в таблице 2.
Таблица 2. Сравнение концепций NiFi и FBP
Термин NiFi | Термин FBP | Описание |
FlowFile | Information Packet | FlowFile представляет каждый объект, перемещающийся по системе, и для каждого из них NiFi отслеживает список атрибутов в виде пары ключ/значение и связанного с ним содержимого с нулевым или большим количеством байтов. |
FlowFile процессоры | Black Box | В Apache NiFi процессоры выполняют работу. В терминах eip процессор выполняет некоторую комбинацию маршрутизации данных, трансформации или посредничества между системами. Процессоры имеют доступ к атрибутам данного FlowFile и его потока контента. Процессоры могут работать с нулевым или большим количеством FlowFiles в заданном блоке работы, и либо выполнять эту работу, либо откатывать. |
Connection | Bounded Buffer | Соединения (Connection) обеспечивают фактическую связь между процессорами. Они действуют как очереди и позволяют различным процессам взаимодействовать на разных условиях. Эти очереди могут быть распределены по приоритетам динамически и могут иметь верхние границы нагрузки. |
Flow Controller | Scheduler | Контроллер потока (Flow Controller) содержит информацию о том, как процессы соединяются и управляют потоками и их распределениями, которые используют данные процессы. Контроллер потока действует как брокер, облегчающий обмен FlowFiles между процессорами. |
Process Group | subnet | Группа процессов представляет собой определенный набор процессов и их соединений, которые могут принимать данные через входные порты и отправлять данные через выходные порты. Таким образом, группы процессов позволяют создавать совершенно новые компоненты состоящие из других компонентов. |
2.3. Преимущества NiFi
Модель дизайна Apache NiFi дает много полезных преимуществ, которые помогают NiFi быть очень эффективной платформой для построения мощных и масштабируемых потоков данных. Некоторые из этих преимуществ включают [26]:
- Визуальное создание и управление направленными графиками процессоров. Является асинхронным, что обеспечивает высокую пропускную способность и естественную буферизацию, даже когда скорость потока и обработки расходятся. Дает возможность создания связанных и слабо-связанных компонентов, которые затем могут быть повторно использованы в других контекстах. Удобная обработка ошибок, которая облегчает работу и поиска проблемных мест. Источники, по которым поступают данные и выходят из системы, а также то, как они протекают и обрабатываются, визуально видимы и легко отслеживаются.
2.4. Архитектура NiFi
NiFi выполняется в JVM в операционной системе хостовой машины. Наглядная схема архитектуры отображена на рис.1. Основные компоненты NiFi перечислены в таблице 3.
Таблица 3. Основные компоненты Apache NiFi.
Веб сервер | Цель веб-сервера - дать возможность HTTP доступа к NiFi API. |
Контроллер потока | Контроллер потока - это один из основных компонентов системы. Он предоставляет потоки для расширений по запуску потоков и управляет расписанием, когда расширения получают ресурсы для выполнения задач. |
Расширения | Существуют различные типы расширений NiFi. Ключевым моментом здесь является то, что расширения работают и выполняются в JVM. |
Репозиторий FlowFile | Репозиторий FlowFile - это место, где NiFi отслеживает состояние того, что он знает о данном FlowFile, который в настоящее время активен в потоке. Реализация репозитория подключаема и может быть заменена. Подходом по умолчанию является логирование write-ahead, расположенный на определенном разделе диска. |
Контент - репозиторий | Контент-репозиторий содержит фактические байты содержимого потока данных. Реализация репозитория подключаема и может быть заменена. По умолчанию - это довольно простой механизм, который хранит блоки данных в файловой системе. Можно указать более одного места хранения в файловой системе, чтобы задействовать различные физические разделы чтобы ускорить запись и чтение. |
Репозиторий источников | Репозиторий источников - это место, где хранятся все события источников данных. Конструкция репозитория подключаема и может быть изменена, реализация по умолчанию это использование одного или нескольких физических дисков. Каждое событие источника данных индексируются и доступны для поиска. |
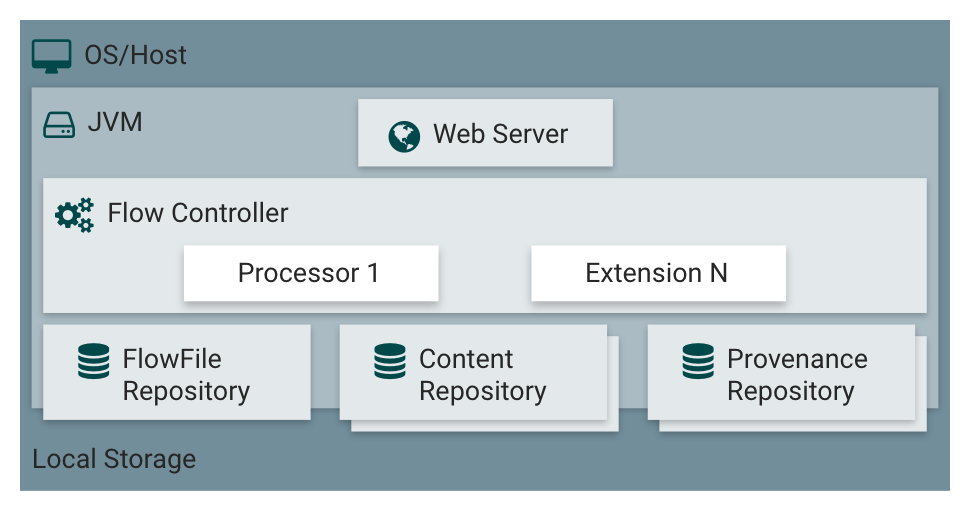
Рис. 1. Архитектура Apache NiFi
2.5. Кластер Apache NiFi
Для наших задач, важно запустить кластер Apache NiFi на различных устройствах, чтобы проверить возможность работы данной технологии на граничных устройствах сети в парадигме туманных вычислений.
Для запуска кластера Apache NiFi может использоваться встроенный или внешний Apache Zookeeper [31]. В данной работе решено было использовать встроенный Zookeeper, так как нам желательно уменьшить число зависимостей от внешних инструментов.
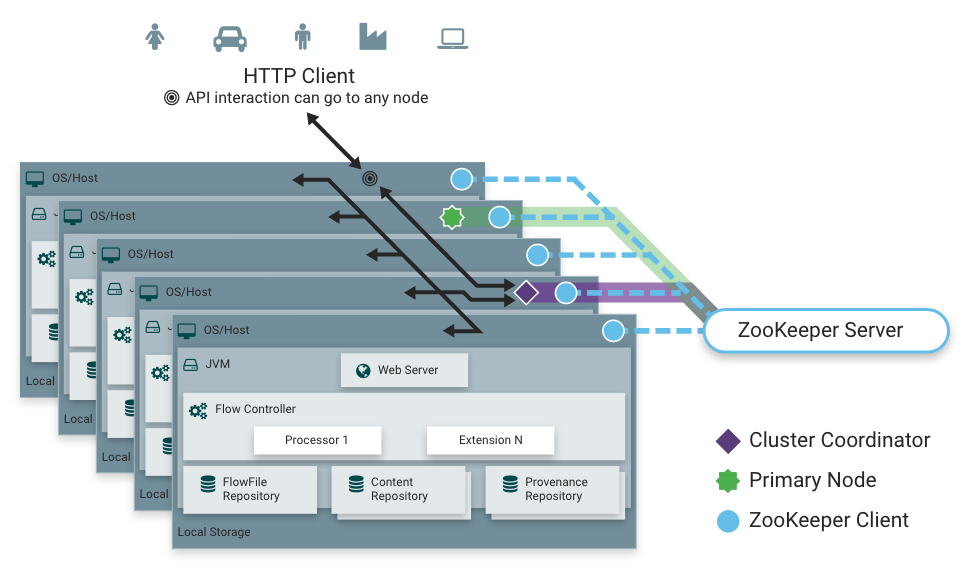 Рис. 2. Компоненты кластера Apache NiFi
Рис. 2. Компоненты кластера Apache NiFi
В NiFi используется парадигма Zero-Master кластеризации. Каждый узел в кластере выполняет одни и те же задачи с данными, но каждый из них работает с различным набором данных. Один из узлов автоматически выбирается (через Apache ZooKeeper) в качестве Координатора кластера (Cluster Coordinator). Наглядная схема отображена на рис. 2. Все узлы в кластере будут отправлять информацию о статусе (heartbeats) на этот узел, он же отвечает за отсоединение узлов, которые не сообщают о своем статусе в течение некоторого времени. Кроме того, когда новый узел решает присоединиться к кластеру, новый узел должен сначала подключиться к выбранному в данный момент Координатору кластеров, чтобы получить актуальный поток. Если координатор кластеров определяет, что узел разрешен для соединения, текущий поток предоставляется этому узлу, и этот узел может присоединиться к кластеру, предполагая, что копия потока узла соответствует копии, предоставленную Координатором Кластеров. Если версия узла конфигурации потока отличается от конфигурации координатора кластера, узел не будет присоединяться к кластеру [31].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
