


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Парадоксы ранних стадий эволюции жизни и биологическая сложность
,
Уральский федеральный университет, Екатеринбург, Россия
Обсуждены два наиболее фундаментальных вопроса, касающихся возникновения жизни: каким образом биологически важные молекулы (РНК, Белки, ДНК) находят свои уникальные пространственные конфигурации и каков механизм эволюции достаточно длинной информационной последовательности. Показано, что обе эти проблемы не решены и представляют собой парадоксы. Обсуждены эксперименты, которые могли бы прояснить механизмы взаимодействия между биологически важными молекулами в простейших клетках.
Ключевые слова: пространственные конфигурации репликаторов, кодирование, ранние стадии эволюции, конформационные степени свободы
Введение
Проблема происхождения жизни в значительной степени остается нерешенной. Несмотря на то, что в экспериментах (таких как классический эксперимент Миллера-Юри) получены аминокислоты искусственным путем, а космические наблюдения показывают наличие необходимых для жизни компонентов в разных районах вселенной, однако механизм образования простейшей живой системы из таких компонентов остается неясным. Нерешенными являются множество вопросов, начиная от возникновения хиральных биологических молекул и до происхождения первых клеток. Общность этих вопросов для происхождения жизни весьма различна. Одни из них касаются возникновения жизни на конкретных планетах, в то время как другие являются наиболее общими и не связанными с химическими деталями ее происхождения.
Большая часть нерешенных вопросов связаны с тем, что наши знания о ранних стадиях эволюции недостаточны. Однако существуют вопросы, связанные с парадоксами, т. е. не просто с недостаточностью наших знаний, но с противоречивостью этих знаний. Без решения этих вопросов (парадоксов) сложно говорить о нашем понимании жизни вообще и ее происхождения в частности. По моему мнению, к таким вопросам относятся следующие:
- каким образом достаточно сложные макромолекулы (репликаторы) работают эффективно, имея в виду то, что общее число возможных пространственных конфигураций таких молекул экспоненциально велико?
- каким образом осуществляется выбор из всех возможных состояний для достаточно длинной кодирующей последовательности, если общее число возможных состояний такой последовательности экспоненциально велико?
Проблема упаковки и стабильности репликаторов
Наша уверенность в том, что мы понимаем биохимию, основана, главным образом, на том, что для относительно простых реакций можно осуществить их расчет из первых принципов квантовой механики и сравнить полученные результаты с экспериментом. Однако при усложнении молекул ситуация принципиально меняется. Дело в том, что для достаточно сложных молекул, таких, как белки, общее число состояний молекулы, а так же общее число возможных реакций такой молекулы со всеми другими молекулами становится экспоненциально большим. Как в таком случае сделать выбор в пользу нескольких (одного) вариантов, которые представляют собой молекулярные машины, способные совершать какую-то определенную работу? Почему в таком случае макромолекулы в клетке (или в первичном океане) не запутываются друг с другом, образуя «мусор»?
Если на ранних стадиях эволюции биологически важные молекулы не имели большого количества степеней свободы (например, самые сложные из обнаруженных в космосе молекул содержат немногим более 10 атомов), однако по мере роста длины молекул число конформационных степеней свободы быстро растет. В процессе возникновения достаточно длинных молекул число таких конформаций (а так же возможных реакций с другими молекулами) увеличивается настолько, что достичь определенной конформации путем простого перебора вариантов становится невозможным.
Взаимодействие между биологически важными молекулами определяется потенциалами взаимодействия между составляющими эти молекулы атомами. Большинство известных на сегодняшний день потенциалов являются короткодействующими, т. е. эти потенциалы велики только для ближайших атомов. Покажем, что короткодействующие потенциалы не позволяют эффективно реализовать большую часть биохимических реакций (включая упаковку макромолекул).
Проблема упаковки белков (парадокс Левинталя) рассматривалась неоднократно (). Принято считать, что для ее решение необходимо существование funnel-like ландшафта свободной энергии.
Оценим, сначала, при какой длине цепочки проблема перебора вариантов не возникает. Общее число состояний белковой цепи можно оценить как (см., например, Berezovskii, 2003)
![]() .
.
Здесь предположено, что каждый домен белка имеет 3 различные конформации. Если взять наибольшую возможную популяцию таких макромолекул за 1050, то получим:
![]() ,
,
откуда получим, что ![]() . Если учесть, кроме того, что каждый домен в белке содержит несколько аминокислот, то получим в качестве грубой оценки:
. Если учесть, кроме того, что каждый домен в белке содержит несколько аминокислот, то получим в качестве грубой оценки:
![]() .
.
Более длинные информационные цепочки не могли бы найти свою нативную конформацию путем перебора за все время существования биосферы. Если же ![]() , то такие молекулы в принципе могли бы найти свою нативную конформацию простым перебором вариантов. Результат, однако зависит от того, какие ограничения наложены на время упаковки. Например, для внутриклеточных процессов это время должно быть мало (~1с).
, то такие молекулы в принципе могли бы найти свою нативную конформацию простым перебором вариантов. Результат, однако зависит от того, какие ограничения наложены на время упаковки. Например, для внутриклеточных процессов это время должно быть мало (~1с).
Покажем теперь, что короткодействующие потенциалы не позволяют реализовать такой funnel-like ландшафт, но вместо этого энергетический ландшафт должен быть изрезанным.
Во-первых, при упаковке макромолекул всегда будут возникать состояния, эквивалентные по энергии, это значит, что они будут реализовываться с равной вероятностью. Например, для одно - или двухкомпонентной молекулы наличие таких состояний (развилок при упаковке) очевидно (рис. 1) (см. так же Melkikh, 2013).
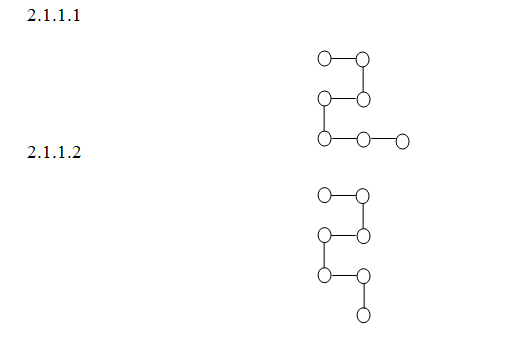
Рис.1.
Это означает, что энергетический ландшафт будет изрезанным за счет таких одинаковых конфигураций, а вероятность прийти в процессе упаковке в единственное состояние будет мала. Рассмотрим непериодическую цепочку с n компонентами, каждый из которых имеет 3 возможных конформации (см., например, ). Для этого случая можно записать вероятность ошибочной упаковки на одном шаге, связанную с наличием развилки, в виде:
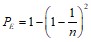 .
.
Для достаточно больших n вероятность имеет вид:
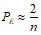 .
.
Тогда вероятность безошибочной упаковки для цепочки длины N может быть оценена по формуле:
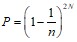 .
.
Например, для n = 20 и N = 100 получим ![]() . Зависимость P(N) при n = 20 представлена на рис.2
. Зависимость P(N) при n = 20 представлена на рис.2
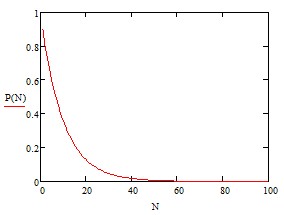
Рис.2
Как видно из рис. 2 вероятность безошибочной упаковки оказывается мала даже для небольших N. Заметим при этом, что величина n не может быть слишком велика, поскольку при ограниченном общем интервале энергий взаимодействия между мономерами Д общее число различных по энергии состояний не может быть больше, чем Д/kT. Величина Д так же не может быть велика (поскольку речь идет о силах, формирующих например, червертичные структуры белков) и составляет менее 1 эВ (40 kT при комнатной температуре).
Таким образом, из-за наличия энергетически вырожденных (но пространственно различных) состояний funnel-like ландшафт не образуется, а вероятность прихода молекулы в свою нативную конформацию оказывается мала. По отношению к репликации это означает, что сам этот процесс будет неустойчивым. В результате либо будут создаваться неточные копии, либо такие последовательности вообще не смогут создавать копий.
Существует и другая причина, препятствующая существованию репликаторов и простейших клеток. При относительно высокой концентрации молекул в везикулах (протоклетках) неизбежно их взаимодействие друг с другом с образованием молекулярных комплексов.
Образование комплексов может быть как полезно, так и вредно для протоклетки. В первом случае такие комплексы могут служить для передачи энергии (информации) внутри протоклетки по принципу ключ-замок. Во втором случае ошибочно возникший комплекс наоборот будет препятствовать нормальному функционированию протоклетки.
Рассмотрим взаимодействие двух достаточно длинных упакованных молекул. Их взаимодействие ничем принципиально не отличается от упаковки, поскольку при этом между мономерами действуют те же самые силы. Хотя отталкивание между отдельными мономерами и не исключено, силы притяжения между мономерами должны преобладать (в противном случае упаковка белков была бы невозможна). Тогда при взаимодействии двух молекул возникающий комплекс будет находиться в одном из своих метастабильных состояний. Поскольку средняя энергия взаимодействия между мономерами существенно больше kT (в противном случае было бы невозможно стабильное существование упакованных белков), то такое метастабильное состояние должно существовать достаточно долго по сравнению с характерными временами внутриклеточных процессов.
С другой стороны, образовавшийся комплекс можно рассматривать как сворачивающуюся единую молекулу. Как было показано выше, в такой сложной системе энергетический ландшафт является изрезанным. Все это будет приводить к тому, что в протоклетке с большой вероятностью будут образовываться молекулярные комплексы, не способные совершать полезную работу.
Конечно, мы знаем, что современные клетки устойчиво работают, несмотря на наличие в них большого количества белков, РНК и ДНК, которые могли бы взаимодействовать друг с другом. Однако механизм такой устойчивости остается неясным.
Для того, чтобы в такой системе funnel-like ландшафт все-таки был реализован, необходимо предъявить к потенциалу взаимодействия между молекулами (атомами) вполне определенные дополнительные требования:
- во-первых, такой потенциал должен включать взаимодействие с достаточно далекими соседями. Только в этом случае (хотя бы в принципе) появляется возможность существенно уменьшить количество развилок (а значит, и вероятность ошибки),
- во-вторых, такой потенциал должен проявляться только для определенных конфигураций атомов, поскольку потенциалы взаимодействия в конденсированных средах произвольной природы достаточно хорошо изучены, и каких-либо дополнительных сил не найдено. Т. е. это должен быть коллективный потенциал.
Однако никакой из известных на сегодня потенциалов не удовлетворяет этим требованиям. Действительно, например, кулоновский потенциал хотя и является относительно дальнодействующим, но не является избирательным. Потенциалы типа Леннарда-Джонса или Морзе являются короткодействующими, т. е. на расстояниях, равных примерно двум размерам атомов их величина уже достаточно мала (сравнима с kT). Если же рассматривать химические (в том числе водородные) связи, то они всегда являются короткодействующими.
Сказанное подтверждается, например, тем, что проблема protein-protein interaction до сих пор не решена, т. е. не проведены расчеты из первых принципов для сколь-нибудь длинных белков (Gruebelle, 2010 - упаковка). Понимание взаимодействия достаточно длинных белков в настоящее время в значительной степени только качественное (см., например, Lua et al, 2014, Cukurogly et al, 2014).
Таким образом, существование множества пространственных структур биологически важных молекул, а так же множества вариантов химических реакций между ними является одним из наиболее важных препятствий для возникновения простейшей живой системы. Должен существовать какой-то особый механизм, существенно ограничивающий выбор возможных вариантов в такой системе. Без этого механизма нельзя говорить о сколь-нибудь значительной эффективности молекулярных машин в протоклетках. Это означает, что такая протоклетка будет состоять из различного рода молекулярных комплексов с различными пространственными конфигурациями, причем такие комплексы не будут способны совершать полезную работу. По мере же усложнения клетки в процессе эволюции эта проблема только усугубляется, поскольку число и длина биологически важных молекул возрастают.
Возникновение кода и проблема перебора вариантов
На ранних стадиях эволюции жизни существовали биомолекулы, которые вступали в различные реакции, в том числе и воспроизводили сами себя. На этом этапе проблема перебора вариантов не была актуальной, поскольку получающиеся в результате реакций молекулы могли и не совершать какой-то вполне определенной работы. Однако в дальнейшем часть молекул стала кодировать другие молекулы. Это принципиально важный этап, который и порождает проблему перебора вариантов.
Как известно, для достаточно длинной информационной последовательности возникают комбинаторные проблемы в переборе всех возможных ее вариантов. В настоящее время широко распространено мнение о том, что комбинаторные проблемы, касающиеся большого количества возможных вариантов нуклеотидных цепочек, решены. Покажем, однако, что решение проблемы перебора вариантов требует дополнительных предположений.
Рассмотрим цепочку нуклеотидов длиной N. Для нее существует всего
![]()
вариантов. Насколько велико это число? Например, для N = 1000 получим:
![]() .
.
Это число вариантов настолько велико, что не может быть перебрано за время жизни вселенной всеми организмами (репликаторами), когда-либо жившими на ней. Однако N = 1000 соответствует примерно всего лишь одному гену. Отсюда следует вывод о том, что для информационных последовательностей длиной, примерно равной 103 и более перебор вариантов происходил каким-то другим способом. Основной вопрос заключается в том, что это за способ и при каких условиях он будет работать.
Часто по умолчанию считается, что число молекул в первичном океане было столь велико, что с их помощью можно осуществить любой перебор. Однако это заблуждение, поскольку при экспоненциальной зависимости легко получить требуемое число вариантов, при которых масса репликаторов превышала бы массу Земли и т. д.
Считается (см., например,…), что дальше эволюция шла путем молекулярной экзаптации, т. е. путем использования и перетасовки уже имеющихся информационных последовательностей, блоков и т. д. Однако такой механизм не будет работать сам по себе, он подразумевает наличие априорной информации в системе. Действительно, если в системе нет априорной информации о том, что именно будет кодировать некоторый набор символов, то нет никакого способа узнать об этом, кроме как синтезируя по этому набору молекулярную машину и проверив, выживет ли такой организм или нет. Это и есть простой перебор вариантов. Если же априорная информация имеется, то она должна не просто подразумеваться, но иметь некоторый материальный носитель, т. е. быть записанной в некоторых (пока не известных) внутриклеточных структурах.
Еще один аргумент связан с общими алгоритмами, предложенными для решения различных классов переборных задач. Если бы, для изложенной выше ситуации (т. е. без априорной информации) существовал алгоритм, позволяющий решать задачу за полиномиальное (степенное, относительно небольшое) число шагов, то тогда точно так же были бы решены и все остальные NP-сложные задачи. Однако сведение NP-алгоритмов (неполиномиальных) к P-алгоритмам (полиномиальным) представляет собой на сегодня нерешенную задачу.
Представим себе произвольное изменение кодирующей последовательности. Какова вероятность того, что эта новая последовательность будет кодировать эффективную молекулярную машину? Для расчета такой вероятности принципиальное значение имеет то, имеется ли априорная информация об этой машине или нет. Рассмотрим информационную последовательность
0100010101010100001111,
которая кодирует некоторую молекулярную машину
abcddbcaadcbdcabcdcbadcbadcadb.
Задача получения другой «хорошей» (способной работать эффективно) машины при отсутствии априорной информации о ней полностью соответствует задаче о взломе пароля. Действительно, и в том и в другом случае происходит перебор вариантов некоторого кода, и как только правильный вариант найден, совершается некоторое полезное действие. В одном случае это совершение полезной работы синтезированной машиной, в другом – доступ к какой-либо полезной информации. Подчеркнем, что информация о том, насколько близко перебирающая варианты система находится от цели, ей не доступна – перебор вариантов заканчивается только при достижении некоторой (заранее неизвестной) последовательности.
Однако, как известно (), задача взлома пароля является NP-сложной, т. е. для ее решения требуется экспоненциально большое число шагов:
![]() .
.
Если априорная информация о целевой информационной последовательности (хотя бы частичная) имеется (и где-то хранится), то можно в соответствии с этой информацией использовать уже найденные ранее варианты кодов (например, для других задач), лишь незначительно изменяя их. В пределе полной информации процесс кодирования новых молекулярных машин становится полностью детерминистским, поскольку заранее известно, что создавать. В задаче о взломе пароля априорная информация так же играет принципиальную роль.
Конечно, не все аминокислоты в белках равноценны. Ряд из них образуют активные центры, которые наиболее важны для их работы. Такая неравноценность, конечно, может быть свойственна и произвольным системам, использующим информацию. Например, какие-то из элементов кода могут не нести полезной информации, но играют роль только в исправлении ошибок. Однако, такое свойство не является принципиальным для задачи о переборе вариантов, поскольку тогда это лишь вопрос действительной длины последовательности. Например, если нейтральность составляет 20%, то это ничего принципиально не меняет из-за экспоненциальной зависимости числа вариантов от длины последовательности.
Возникает принципиальный вопрос: можно ли ускорить процесс поиска при отсутствии априорной информации с помощью какого-либо процесса (молекулярной экзаптации, горизонтального переноса генов, возникшего позднее альтернативного сплайсинга и т. д.)? Ответ на этот вопрос отрицательный: либо изменения в информационной последовательности происходят случайно, либо должна существовать система, каким-то образом отбирающая нуклеотиды и совершающая с ними определенные операции. Во втором случае наличие в этой системе априорной информации служит необходимым условием ее работы.
Например, при горизонтальном переносе генов, который мог иметь место у простейших бактерий, при получении какого-либо участка генома извне бактерия либо должна априорно «знать», куда такой участок можно встроить и в каких условиях он может быть полезен, либо (если такого знания нет), становится не важно, что является источником такого участка, соседний вид или какой-либо случайный процесс.
Таким образом, парадокс перебора вариантов состоит в следующем: конечно, механизмы молекулярной экзаптации, блочного кодирования, горизонтального переноса генов и т. д. работают (и могли существовать, по-видимому, на ранних стадиях эволюции), однако для их функционирования априорная информация (т. е. существующая до синтеза молекулярных машин) является совершенно необходимой. Современная теория эволюции не предполагает наличия такой информации. Если предположить, что такая информация существует, то возникает вопрос о том, где она хранится, поскольку любая информация должна иметь физический носитель. С другой стороны, информация об изменении генов не может храниться в самих генах. Вопрос о механизмах хранения и обработки такой информации остается открытым.
Обсуждение, возможные направления решения парадоксов
Подчеркнем, что без решения предложенных парадоксов известные нам формы жизни вообще не могли бы возникнуть и функционировать. Действительно, в этом случае реакции между биологически-важными молекулами приводили бы с подавляющей вероятностью к формированию «паразитических» структур, эффективность которых была бы исчезающе мала. С другой стороны, репликация такой системы не приводила бы к возникновению новых видов репликаторов, т. е. их эволюция была бы невозможна.
Оба рассмотренных парадокса дают примерную оценку сложности примерно в 103 нуклеотидов, начиная с которой возникают проблемы функционирования сложных систем. Такое количество нуклеотидов соответствует примерно одному гену. Такое совпадение представляется не случайным. Скорее всего, как молекулярные машины, так и кодирующие системы не могут быть слишком просты (т. е. не могут содержать лишь несколько молекул) для выполнения своих функций. Заметим, что число нуклеотидов порядка 103 во много раз меньше, чем у самых простейших из современных клеток.
Сформулированные парадоксы являются препятствием для возникновения жизни в любой ее форме (в том числе и альтернативных форм жизни, основанных на других химических элементах, таких как кремний, мышьяк и т. д.). Скорее всего, речь идет о наиболее общих ограничениях, касающихся всех известных элементов таблицы Менделеева.
Поскольку для неживых молекулярных систем предложенные парадоксы не характерны, то само существование таких парадоксов может быть положено в основу определения жизни. Можно дать следующее определение жизни:
Жизнь это неравновесная самовоспроизводящаяся система настолько большой сложности, что в ней не может быть реализован простой перебор вариантов.
Отметим так же, что оба сформулированных парадокса могут иметь единое решение. Действительно, поскольку любая информация может существовать только при наличии некоторого физического носителя, то и в том и в другом случае возникает вопрос о том, какие силы действуют между биологически важными молекулами. Это вопрос обсуждался так же ранее (Melkikh, 2013, 2014) и был сделан вывод о том, что квантовая механика должна играть важную роль в этих процессах.
Какие эксперименты могли бы пролить свет на механизмы репликации и работы молекулярных машин в простейших клетках? Такие эксперименты должны включать в себя гораздо более детальное измерение внутриклеточных молекулярных процессов, чем это обычно делается. С одной стороны, эксперименты должны включать детальное (на уровне отдельных нуклеотидов или даже атомов) измерение состояния эволюционирующей системы. С другой стороны, необходима столь же детальная регистрация реакций между биологически важными молекулами (в частности – процесса их упаковки). Ряд подобных экспериментов предложен ранее (Melkikh, 2013, 2014a, b).
Литература
Melkikh, A. V., 2008. DNA computing, computation complexity and problem of biological evolution rate. Acta Biotheoretica. 56, 285-295.
Melkikh, A. V., 2011. First principles of probability theory and some paradoxes in modern biology (comment on "21st century: what is life from the perspective of physics?" by GR Ivanitskii). Phys. Usp. 54 (4), 429-430.
Melkikh, A. V., 2013. Biological complexity, quantum coherent states and the problem of efficient transmission of information inside a cell. BioSystems. 111. 190-198.
Melkikh, A. V., Sutormina, M. I., 2013. Developing synthetic transport systems, Springer, Dordrecht.
Melkikh, A. V., 2014a. Quantum information and the problem of mechanisms of biological evolution. BioSystems. 115. 33-45.
Melkikh, A. V., 2014b. Congenital programs of the behavior and nontrivial quantum effects in the neurons work. BioSystems. 119. 10-19.
Neveu, M., Kim, H.-J., Benner, S. A. 2013. The “Strong” RNA World hypothesis. Fifty years old. Astrobiology. 13. 391.
Luisi P. L.
Lua et al, 2014.
Cukurogly et al, 2014.
Finkelstein, A. V., Ptitsyn, O. B., 2002. Protein Physics, Academic Press, Oxford.
M. Gruebelle. Weighing up protein folding. Nature. 2010. (нет расчетов для реального балка)
