

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
К ним относятся следующие характеристики
) Длина кода n - число разрядов (символов), составляющих кодовую комбинацию.
) Основание кода m - количество отличающихся друг от друга импульсных признаков, используемых в кодовых словах. Для двоичных кодов m = 2.
) Мощность кода Np - число кодовых комбинаций (рабочих кодовых слов), используемых для передачи сообщений.
) Полное число кодовых комбинаций N - число всех возможных комбинаций, равное mn (для m = 2 > N = 2n).
) Число информационных разрядов k - количество символов (разрядов) кодового слова, предназначенных для передачи собственного сообщения. Np = 2k
) Число проверочных символов r - количество символов (разрядов) кодового слова, необходимых для коррекции ошибок. Это число характеризует абсолютную избыточность кода.
) Избыточность кода R - относительная избыточность.
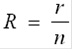
В общем случае можно ее привести к виду:
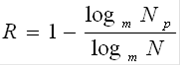
) Скорость передачи кодовых комбинаций - отношение числа информации символов n к длине кода:
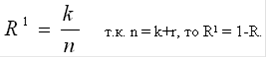
) Вес кодовой комбинации w - количество единиц в кодовой комбинации. Весовая характеристика кода W(w) - число кодовых слов весом w.
) Вероятность не обнаруживаемых ошибок РН. О. - это вероятность такого события, при котором принятая кодовая комбинация отличается от переданной, а свойства данного кода не позволяют определить факта наличия ошибки.
) Оптимальность кода - свойства такого кода, который обеспечивает наименьшую вероятность не обнаружения ошибки среди всех кодов той же длины n и избыточности r.
) Коэффициент ложных переходов:
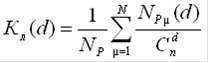
где ![]() - число рабочих кодовых комбинаций, отстоящих от і-ой кодовой комбинации на расстоянии d.
- число рабочих кодовых комбинаций, отстоящих от і-ой кодовой комбинации на расстоянии d.
![]() - число сочетаний из d для данной длины n кода.
- число сочетаний из d для данной длины n кода.
Данный коэффициент показывает, какая доля ошибок кратности d не обнаруживается. Для систематических кодов все кодовые слова имеют одинаковое распределение кодовых расстояний от других слов, поэтому:
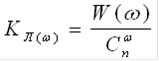
Условие Фано (англ. Fano condition, в честь Роберта Фано) — в теории кодирования необходимое условие построения самотерминирующегося кода (в другой терминологии, префиксного кода). Обычная формулировка этого условия выглядит так:
Никакое кодовое слово не может быть началом другого кодового слова.
Более «математическая» формулировка:
Если в код входит слово a, то для любой непустой строки b слова ab в коде не существует.
Примером кода, удовлетворяющего условию Фано, являются телефонные номера в традиционной телефонии. Если в сети существует номер 101, то номер 1012345 не может быть выдан: при наборе трёх цифр АТС прекращает понимать дальнейший набор и соединяет с адресатом по номеру 101. Однако для набора с сотового телефона это правило уже не действует, потому что требуется явное завершение последовательности знаков соответствующей кнопкой (обычно — с изображением зелёной трубки), при этом 101, 1010 и 1012345 могут одновременно пониматься как разные адресаты.
14. Измерение информации. Собственная информация.
Собственная информация — статистическая функция дискретной случайной величины.
Собственная информация сама является случайной величиной, которую следует отличать от её среднего значения —информационной энтропии.
Для случайной величины ![]() , имеющей конечное число значений:
, имеющей конечное число значений:
![]()
![]()
собственная информация определяется как
![]()
Единицы измерения информации зависят от основания логарифма. В случае логарифма с основанием 2 единицей измерения является бит, если используется натуральный логарифм — то нат, если десятичный — то хартли.
Основание логарифма | Единица измерения | Количество информации |
2 | бит |
|
e | нат |
|
10 | хартли |
|
Собственную информацию можно понимать как «меру неожиданности» события — чем меньше вероятность события, тем больше информации оно содержит.
Свойства собственной информации[править | править вики-текст]
1) Неотрицательность: ![]() .
. ![]() при
при ![]() , т. е. предопределенный факт никакой информации не несет.
, т. е. предопределенный факт никакой информации не несет.
2) Монотонность: ![]() , если
, если ![]() .
.
3) Аддитивность: для независимых ![]() справедливо
справедливо
15. Модель информации по хартли. Формула Хартли.
Формула Хартли определяет количество информации, содержащееся в сообщении длины n.
Имеется алфавит А, из букв которого составляется сообщение:
![]()
Количество возможных вариантов разных сообщений:
![]()
где N — возможное количество различных сообщений, шт; m — количество букв в алфавите, шт; n — количество букв в сообщении, шт.
Пример: Алфавит состоит из двух букв «B» и «X», длина сообщения 3 буквы — таким образом, m=2, n=3. При выбранных нами алфавите и длине сообщения можно составить ![]() разных сообщений «BBB», «BBX», «BXB», «BXX», «XBB», «XBX», «XXB», «XXX» — других вариантов нет.
разных сообщений «BBB», «BBX», «BXB», «BXX», «XBB», «XBX», «XXB», «XXX» — других вариантов нет.
Формула Хартли определяется:
![]()
где I — количество информации, бит.
При равновероятности символов ![]() формула Хартли переходит в собственную информацию.
формула Хартли переходит в собственную информацию.
Формула Хартли была предложена Ральфом Хартли в 1928 году как один из научных подходов к оценке сообщений.
16. Энтропия и информация.
Информацио?нная энтропи?я — мера неопределённости или непредсказуемости информации, неопределённость появления какого-либо символа первичного алфавита. При отсутствии информационных потерь численно равна количеству информации на символ передаваемого сообщения.
Например, в последовательности букв, составляющих какое-либо предложение на русском языке, разные буквы появляются с разной частотой, поэтому неопределённость появления для некоторых букв меньше, чем для других. Если же учесть, что некоторые сочетания букв (в этом случае говорят об энтропии ![]() -го порядка, см. ниже) встречаются очень редко, то неопределённость уменьшается еще сильнее.
-го порядка, см. ниже) встречаются очень редко, то неопределённость уменьшается еще сильнее.
Энтропия — это количество информации, приходящейся на одно элементарное сообщение источника, вырабатывающего статистически независимые сообщения.
Определение с помощью собственной информации[править | править вики-текст]
Также можно определить энтропию случайной величины, введя предварительно понятия распределения случайной величины ![]() , имеющей конечное число значений:[2]
, имеющей конечное число значений:[2]
![]()
![]()
и собственной информации:
![]()
Тогда энтропия определяется как:
![]()
От основания логарифма зависит единица измерения количества информации и энтропии: бит, нат, трит или хартли.
Свойства
Энтропия является количеством, определённым в контексте вероятностной модели для источника данных. Например, кидание монеты имеет энтропию:
![]() бит на одно кидание (при условии его независимости), а количество возможных состояний равно:
бит на одно кидание (при условии его независимости), а количество возможных состояний равно:![]() возможных состояния (значения) ("орёл" и "решка").
возможных состояния (значения) ("орёл" и "решка").
У источника, который генерирует строку, состоящую только из букв «А», энтропия равна нулю: ![]() , а количество возможных состояний равно:
, а количество возможных состояний равно:![]() возможное состояние(значение) («А») и от основания логарифма не зависит.
возможное состояние(значение) («А») и от основания логарифма не зависит.
Это тоже информация, которую тоже надо учитывать. Примером запоминающих устройств в которых используются разряды с энтропией равной нулю, но с количеством информации равным 1возможному состоянию, т. е. не равным нулю, являются разряды данных записанных в ПЗУ, в которых каждый разряд имеет только одно возможное состояние.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
