

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В проектирования баз данных сущность – это нечто, что заслуживает своей собственной таблицы в модели вашей базы данных. Когда вы проектируете базу данных, вы должны определить эти сущности в системе, для которой вы создаете базу данных. Это вопрос диалога с клиентом или с собой с целью выяснения того, с какими данными будет работать ваша система.
Второй шаг в проектировании баз данных – это выбор того, какие связи существуют между сущностями в вашей системе. Решение о том, какие связи будут иметь ваши сущности – важная часть проектирования баз данных и эти связи отображаются в диаграмме сущность-связь.
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
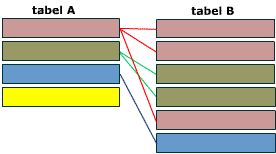
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
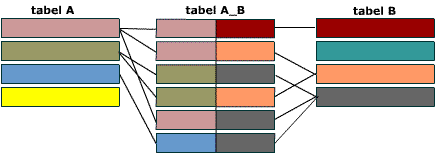
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: А и В имеют связь один-ко-многим с соединительной таблицей.
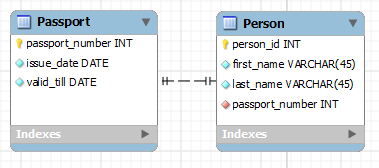
В связи один-к-одному каждый блок сущности A может быть ассоциирован или с 0 или с 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью. Но могут использоваться две таблицы.
Проект реляционной базы данных – это коллекция таблиц, которые связываются первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами.
Если есть многие данные, которые могу быть присвоены многим людям, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т. е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
В таких случаях использование связи многие-ко-многим с использованием трех таблиц и с хранением общей информации централизованно очень удобно. Ведь если общие данные меняются, то для того, чтобы информация в базе данных соответствовала действительности достаточно подправить ее только в одном месте, т. к. хранится она только в одном месте (таблице), в остальных таблицах имеются лишь ссылки на нее.
Нормализация. Указания для правильного проектирования реляционных баз данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации баз данных. Пятый уровень представляет высший уровень нормализации. Нормальные формы – это рекомендации по проектированию баз данных. Вы не обязаны придерживаться всех пяти нормальных форм при проектировании баз данных. Тем не менее, рекомендуется нормализовать базу данных в некоторой степени потому, что это даст ряд существенных преимуществ по эффективности и удобству работы с базой данных. Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы.
Первая нормальная форма гласит, что таблица базы данных – это представление сущности вашей системы, которую вы создаете. Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т. д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента. Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей. Как вы знаете, первичный ключ может состоять из нескольких полей. Когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
Атомарность. Правило: поля не имеют дубликатов и каждое поле содержит только одно значение. Примером плохой практики при проектировании является хранение множественных значений в ячейке.

Верным решением будет выделение автомобилей в отдельную таблицу и использование внешнего ключа, который ссылается на эту таблицу.
Правило: порядок записей таблицы не должен иметь значения.
Вы может хотите использовать порядок записей в таблице клиентов для определения того, какой из клиентов зарегистрировался первым. Для этих целей вам лучше создать поля даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться или добавляться. Вот почему вам никогда не следует полагаться на порядок записей в таблице. Вторая нормальная форма.
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть уже нормализована согласно первой нормальной форме. Вторая нормальная форма связана с избыточностью данных.
Избыточность данных. Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Звучит немного заумно. А означает это то, что вы должны хранить в таблице только данные, которые напрямую связаны с ней и не имеют отношения к другой сущности. Следование второй нормальной форме – это вопрос нахождения данных, которые дублируются в записях таблицы и которые принадлежат другой сущности.
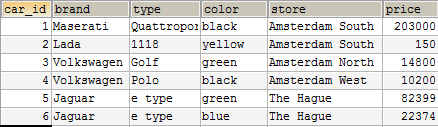
Если посмотрите на эту таблицу, то вы увидите примеры дублирования данных среди записей. Поле brand могло бы быть выделено в отдельную таблицу. Также, как и поле type (модель), которое также могло бы быть выделено в отдельную таблицу, которая бы имела связь многие-к-одному с таблицей brand потому, что у бренда могут быть разные модели.
Колонка store содержит наименование магазина, в котором в настоящее время находится машина. Store – это очевидный пример избыточности данных и хороший кандидат для отдельной сущности, которая должна быть связана с таблицей автомобилей связью по внешнему ключу. Ниже пример того, как бы вы моги смоделировать базу данных для автомобилей, избегая избыточности данных.
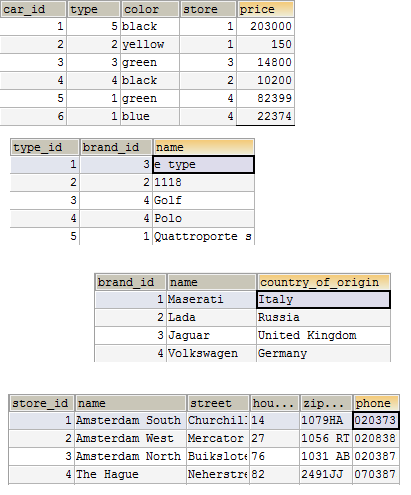
В примере выше таблица car имеет внешний ключи – ссылку на таблицы type и store. Столбец brand исчез потому, что на бренд есть неявная ссылка через таблицу type. Когда есть ссылка на type, есть ссылка и на brand, т. к. type принадлежит brand. И даже сейчас вы не должны быть удовлетворены результатом потому, что вы также могли бы выделить поле color в отдельную таблицу. Если вы планируете хранить огромное количество единиц автомобилей в системе и вы хотите иметь возможность производить поиск по цвету (color), то было бы мудрым решением выделить цвета в отдельную таблицу так, чтобы они не дублировались.
Третья нормальная форма связана с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существует тогда, когда значения не ключевых полей зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов (мои клиенты – игроки немецкой и французской футбольной команды) ниже содержит транзитивные зависимости.
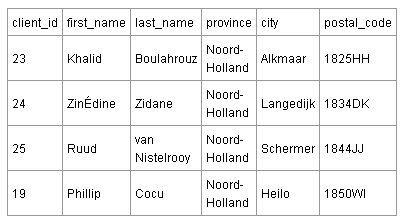
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города (city) и провинции (province). В Нидерландах оба значение: город и провинция – определяются почтовым кодом, индексом. Таким образом, нет необходимости хранить город и провинцию в клиентской таблице. Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такая транзитивной зависимости следует избегать, если вы хотите, чтобы ваша модель базы данных была в третьей нормальной форме.
В данном случае устранение транзитивной зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранение их в отдельной таблице, содержащей почтовый код (первичный ключ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием. Вот почему такие таблицы зачастую продаются.
Другим примером для применения третьей нормальной формы может служить (слишком) простой пример таблицы заказов интернет-магазина ниже.
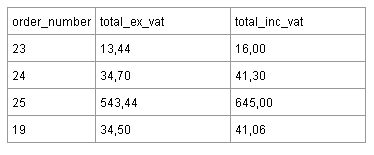
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других (не ключевых) полей таблицы.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда разрабатываете базу данных вы всегда должны сравнивать преимущества от более высокой нормальной формы в сравнении с объемом работ, которые требуются для применения третьей нормальной формы и поддержания данных в таком состоянии. В случае с клиентской таблицей лично не стоит нормализовать таблицу до третьей нормальной формы. В последнем примере с НДС желательно использовать третью нормальную форму. Хранение данных, воспроизводимых из существующих, обычно плохая идея.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
