

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В качестве тестовой группы были выбраны люди в возрасте от 20 до 25 лет, каждый из которых ежедневно работает на компьютере и имеет стабильный, сформировавшийся почерк.
За время эксперимента каждый пользователь совершил по восемь подходов в привычной для него обстановке, на своей клавиатуре, что позволило снизить влияние внешних факторов на почерк и собрать более точные данные. Каждый из подходов состоял из пятидесяти попыток, т. о. в течение каждого подхода пользователь находился в разных психофизических состояниях: медлительность и неуверенность в первых попытках, стабильность в средние, усталость и сбивчивость ближе к концу подхода. Зачастую пользователи совершали более пятидесяти попыток, т. к. все ошибочные попытки не фиксировались. Т. о. при анализе данных можно будет выделить именно стабильные характеристики почерка, сохраняющиеся в любом состоянии.
В результате было собрано достаточное количество данных (16000 записей), а изложенное выше позволяет считать их репрезентативными.
Описание программыПрограмма для сбора статистических данных, пригодных для анализа, была написана на языке Delphi, в среде Borland Delphi 7.0. Она представляет собой окно с полями для ввода: имени пользователя (или индивидуального номера), номера подхода (session) и пароля «rock-music», одинакового для всех, а так же, для удобства пользователя, отображается номер попытки (try) (см. рисунок 2.1).
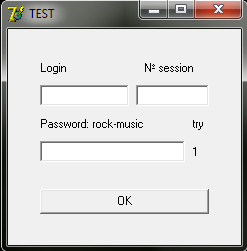
Рисунок 2.1. Интерфейс программы.
Пользователь вводит пароль, а программа фиксирует время нажатия (td) и отпускания (tu) клавиш, по средствам функции Time, фиксирующей текущее системное время, внутри стандартных процедур Delphi по работе с клавишами - KeyDown и KeyUp, а так же какая именно клавиша была нажата (переменная Key), для отслеживания и удаления неудачных попыток. В случае неверного ввода хотя бы одной буквы попытка не засчитывается, а на форме высвечивается надпись «Error!». Затем программа рассчитывает время удержания клавиш (Hold), время между нажатиями соседних клавиш (DownDown) и время между опусканием одной клавиши и нажатием следующей (UpDown) (2.1). Т. о. получается 31 столбец, содержащий информацию трех типов о времени ввода.
H = |td1 - tu1|;
DD = |td2 – td1|; (2.1)
UD = |td2 - tu1|;
По совершению пятидесятой попытки или по нажатию кнопки «ОК» данные записываются в файл формата. csv, т. о. для каждого подхода каждого пользователя формируется отдельный файл (рисунок 2.2).
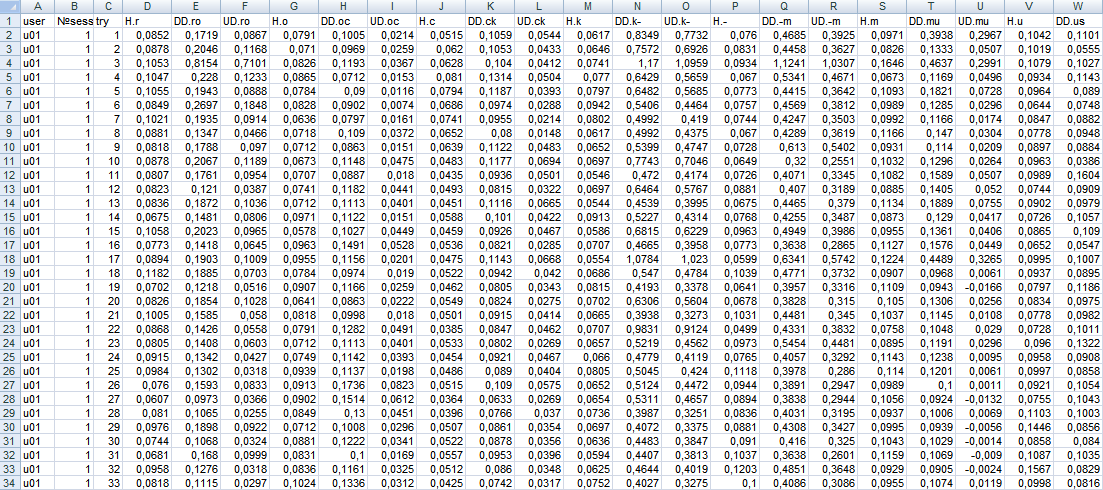 Рисунок 2.2. Пример файла.
Рисунок 2.2. Пример файла.
Полученные данные были собраны в один файл. Имена пользователей приведены к общему виду uXX. Все значения имеют числовой формат, следовательно, не требуется производить их кодирование или преобразование, а т. к. данные формировались программой автоматически, то исключены опечатки, пропущенные или ошибочные значения.
Для дальнейшего исследования данные были разделены на две части: обучающую и тестирующую выборки, т. к. данных достаточно много, то деление было произведено как 2/3 и 1/3 [4]. К обучающей выборке было отнесено по тридцать пять первых записей из каждого подхода, оставшиеся пятнадцать ко второй. Т. о. размер обучающей выборки составил 11200 записей (по 280 на каждого пользователя), размер тестовой выборки, соответственно, 4800 записей.
Выводы по главе 2В главе 2 рассмотрены способы аутентификации пользователя различными методами, основанными: на знании какой либо информации – пароля, на использовании уникального предмета (жетона, электронной карточки), на измерении биометрических параметров человека.
Рассмотрены характеристики клавиатурного почерка и выбраны некоторые из них для проведения исследования: время удержания клавиш, интервалы между нажатиями клавиш, интервалы между отпусканием и нажатием следующих клавиш, скорость набора.
Так же приведено обоснование выбора других параметров исследования.
Описана программа, созданная для сбора данных и процесс подготовки данных для дальнейшего анализа.
РЕЗУЛЬТАТЫ АНАЛИЗА ДАННЫХ И ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ Анализ с помощью алгоритма k-ближайших соседей (k-nearest neighbor algorithm, KNN).
На первом этапе выбрано несколько вариантов числа k, для подбора лучшего экспериментальным путем: 50, 100, 150. Далее, случайным образом, выбиралась одна из записей тестовой выборки, и, в соответствии с алгоритмом приведенном в пункте 1.3.4, для нее находилось Евклидово расстояние по формуле 1.1 до всех записей обучающей выборки. Т. к. все атрибуты по смыслу делятся на три группы, Евклидово расстояние рассчитывается как отдельно для каждой группы, так и для всех атрибутов вместе. Затем выбирались k записей, для которых Евклидово расстояние до новой записи было минимальным, и проводилось взвешенное голосование по формуле 1.2, т. е. для каждого класса подсчитывается сумма обратных квадратов расстояний между записями этого класса и новой записью. Класс, для которого сумма получается наибольшей, присуждался новой записи. Вычисления проводятся в MS Excel с помощью макросов.
Выявлено, что наиболее верно пользователь определялся по атрибутам, связанным с удержанием клавиш около, - 92% случаев. А вот существенной разницы между выбором k = 50 / 100 / 150 выявлено не было (рисунок 3.1). Т. о. выбор был сделан в пользу k = 50, т. к. увеличение k не ведет к улучшению результата, при этом требует большие затраты времени и ресурсов.
На рисунке 3.1 представлен график результатов взвешенного голосования по атрибутам удержания клавиш. Как видно из графика, при обоих k максимальный результат у пользователя u09, что означает, что новая запись сделана именно им.
На рисунке 3.2, представлен график результатов взвешенного голосования на основе атрибутов, содержащих время между нажатием на соседние клавиши, где ближайшим соседом к новой записи, которая, как и в предыдущем примере, сделана пользователем u09, оказался пользователь u21.
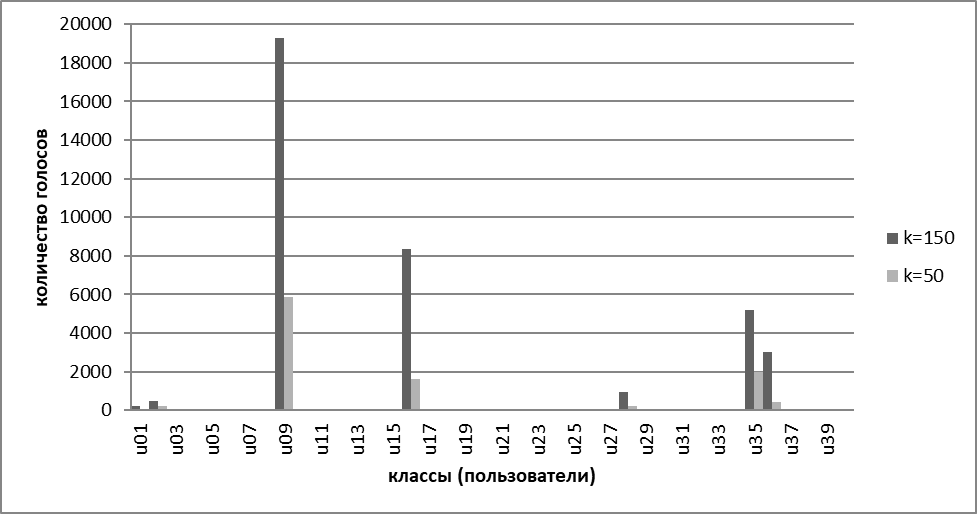
Рисунок 3.1. График результатов взвешенного голосования по атрибутам удержания клавиш.
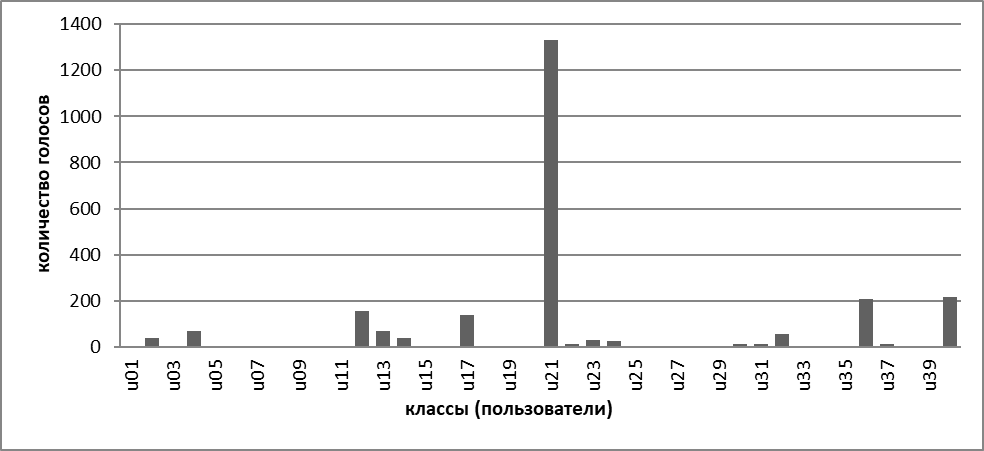
Рисунок 3.2. График результатов взвешенного голосования по атрибутам, связанным со временем между нажатием на соседние клавиши.
Анализ методом 1-Правило на основе интерваловДля каждого класса (пользователя) и для каждого атрибута был определен интервал возможных значений и сформированы правила: «Если каждый атрибут записи принадлежит соответствующему интервалу, то данная запись сделана этим пользователю».
По результатам применения правил были получены следующие результаты: в среднем в 13,5% случаев пользователи были неверно приняты за «своего» (рис 3.3), и в 9% «свои» были приняты за «чужих».
При проведении предварительной обработки данных, а именно удалении значений имеющие значительное отклонение от среднего, результат работы алгоритма улучшился в среднем до 11%, в то время как количество верно определенных записей, относящихся к данному классу, не изменилось.
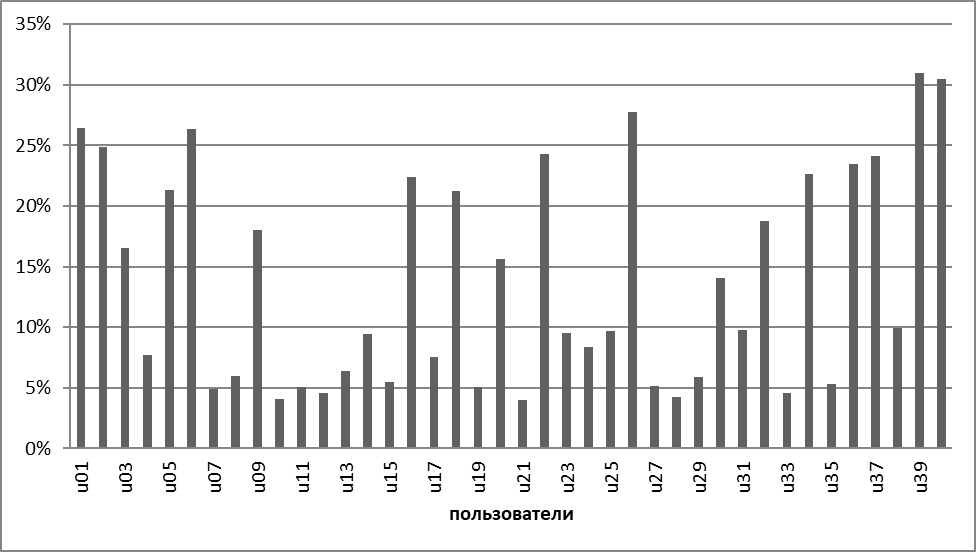
Рисунок 3.3. График результата работы правил: неверное определение пользователя как «своего»
Анализ методом 1-Правило на основе средних значенийДля каждого класса (пользователя) и для каждого атрибута было определено среднее значение и сформированы правила:
«Если Евклидово расстояние (1.1) от атрибутов новой записи до средних значений этих же атрибутов данного класса меньше расстояний до средних значений атрибутов других классов, то данная запись принадлежит этому классу».
«Если расстояние по Хеммингу (3.1) от атрибутов новой записи до средних значений этих же атрибутов данного класса меньше расстояний до средних значений атрибутов других классов, то данная запись принадлежит этому классу».
![]()
![]() , (3.1)
, (3.1)
где m – количество атрибутов, yi - значение атрибута известной записи, xi - значение атрибута новой записи.
Здесь, как и в пункте 3.1, исследование проводилось не для каждого атрибута, а для трех групп, на которые все атрибуты делятся по смыслу, а так же для всех атрибутов сразу.
По результатам применения правил были получены следующие результаты: наилучшие результаты были получены для группы атрибутов, связанной с удержание клавиш (рис. 3.4 и 3.5, темно-серый). Для не «очищенной» от аномальных значений выборки, а следовательно имеющей не совсем достоверные средние значения, точность верного определения класса составила при расчете Евклидового расстояния 73%, для расстояния по Хеммингу 75%. При использовании предварительно обработанных данных результаты применения правил почти одинаковые, около 76%.
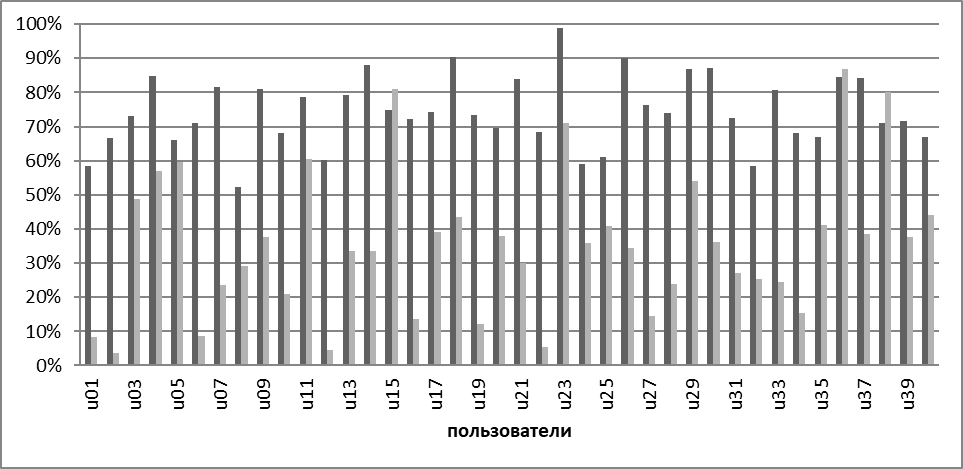
Рисунок 3.4. График результатов работы правил: Евклидово расстояние.
На рисунке 3.4 темно-серым, показаны результаты расчета расстояний по атрибутам удержания клавиш, серым - по атрибутам, связанным со временем между нажатием на соседние клавиши.
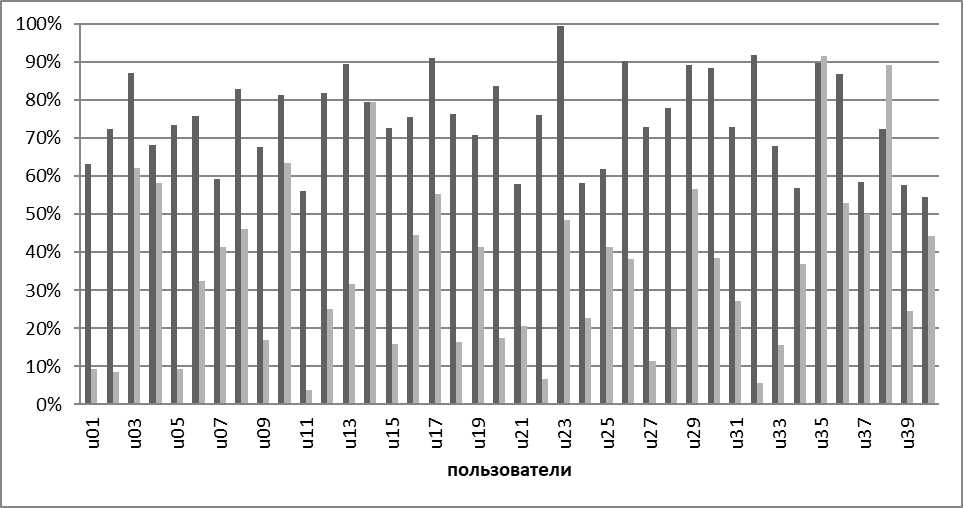
Рисунок 3.5. График результатов работы правил: Расстояние по Хеммингу.
На рисунке 3.5 темно-серым, показаны результаты расчета расстояний по атрибутам удержания клавиш, серым - по атрибутам, связанным со временем между нажатием на соседние клавиши.
Сравнение построенных модели и интерпретация результатовХуже всего определил пользователя по клавиатурному почерку алгоритм, основанный на средних значениях обучающей выборки. Лучший результат был получен при учете только атрибутов связанных с удержанием клавиш и предварительной очисткой обучающей выборки от записей, имеющих значительное отклонение – в среднем около 76% процентов случаев. В случае отсутствия такой очистки и применяя в качестве меры близости новой записи и среднего расстояние по Хеммингу, результат получился около 75%, что на 2% выше, чем при использовании Евклидового расстояния. Т. к. при расчете расстояния по Хеммингу, в отличие от Евклидового, разности не возводятся в квадрат и расстояние до среднего меньше. В целом данный результат подтверждает слабость методов на основе среднего значения.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
