

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ВВЕДЕНИЕ
Актуальность темы дипломной работы определяется тем, что традиционные методы идентификации и аутентификации, основанные на использовании переносных идентификаторов, а также паролей и кодов доступа, имеют ряд существенных недостатков, связанных с тем, что для установления подлинности пользователя применяются атрибутивные и основанные на знаниях опознавательные характеристики, которые можно подделать или украсть. В связи с этим растет интерес к использованию биометрических методов идентификации. Биометрические характеристики являются неотъемлемой частью человека и поэтому их невозможно подделать, забыть или потерять.
Среди них есть как хорошо всем известные, отпечатки пальцев, так и менее распространенные, например, аутентификация по ритму работы на клавиатуре - по клавиатурному почерку. Данный способ позволяет выявить нарушителя не только на этапе аутентификации, но и на протяжении всего времени работы за клавиатурой, т. е. если после авторизации сядет другой пользователь, то почерк измениться и система заблокируется.
Идентификация людей по клавиатурному почерку реализуется на программном уровне, поэтому является наименее затратной среди биометрических. Так же отсутствие дополнительных устройств делает данный способ скрытым.
Степень разработанности проблемы. Исследования данной проблемы представленные в работах таких учёных, как R. Gaines, J. Leggett, W. Lisowski, Alen Peacock, Adrian Perrig, S. Press, N. Shapiro, Dawn Song, D. Umphress, Peter Venable, G. Williams, , Расторгуев С. H. и др. и направленные на статистический анализ данных характеризуются достоверностью аутентификации не выше 90%, ввиду изменчивости почерка в разных психофизиологических состояниях. До сих пор многие вопросы аутентификации пользователей на основе клавиатурного почерка не изучены. Поэтому актуальна дальнейшее развитие методов, алгоритмов и их программно-аппаратных реализаций, повышающих эффективность систем идентификации и аутентификации.
Цель дипломной работы: повышение эффективности механизма распознавания пользователя по клавиатурному почерку в системах аутентификации
Для этого необходимо решить следующие задачи:
- проанализировать существующие методы анализа данных и выбрать несколько наиболее подходящих, исходя из сложности реализации и точности получаемого результата; собрать и подготовить тестовые данные для проведения исследований; проанализировать собранные данные выбранными методами; сравнить результаты и выбрать лучший метод идентификации пользователя.
Объектом исследования является повышение достоверности аутентификации по клавиатурному почерку.
Предмет исследования - методы интеллектуального анализа данных.
Методологической и теоретической основой дипломной работы являются современные научные публикации по изучаемой проблематике. В качестве статистического источника были использованы собранные в ходе работы над дипломом данные.
Решение задач, поставленных в работе, основывается на применении методов анализа данных, так называемые методы Data Mining, теории вероятностей и математической статистики, а также на основе экспериментальных исследований, компьютерное моделирование выполняется с использованием Microsoft Excel 2007 и языка программирования VB.
Практическая ценность работы. Разрабатываемые методы и средства позволят повысить достоверность аутентификации пользователей по их клавиатурному почерку, предотвращая несанкционированный доступ.
ОБЗОР МЕТОДОВ АНАЛИЗА ДАННЫХПод анализом данных понимаются действия направленные на получение новых, неочевидных знаний об объекте.
Анализ данных состоит из нескольких этапов (см. рисунок 1.1) [14]:
- понимание и формулировка задачи анализа; подготовка данных для автоматизированного анализа (препроцессинг); применение методов Data Mining и построение моделей; проверка построенных моделей; интерпретация моделей человеком.
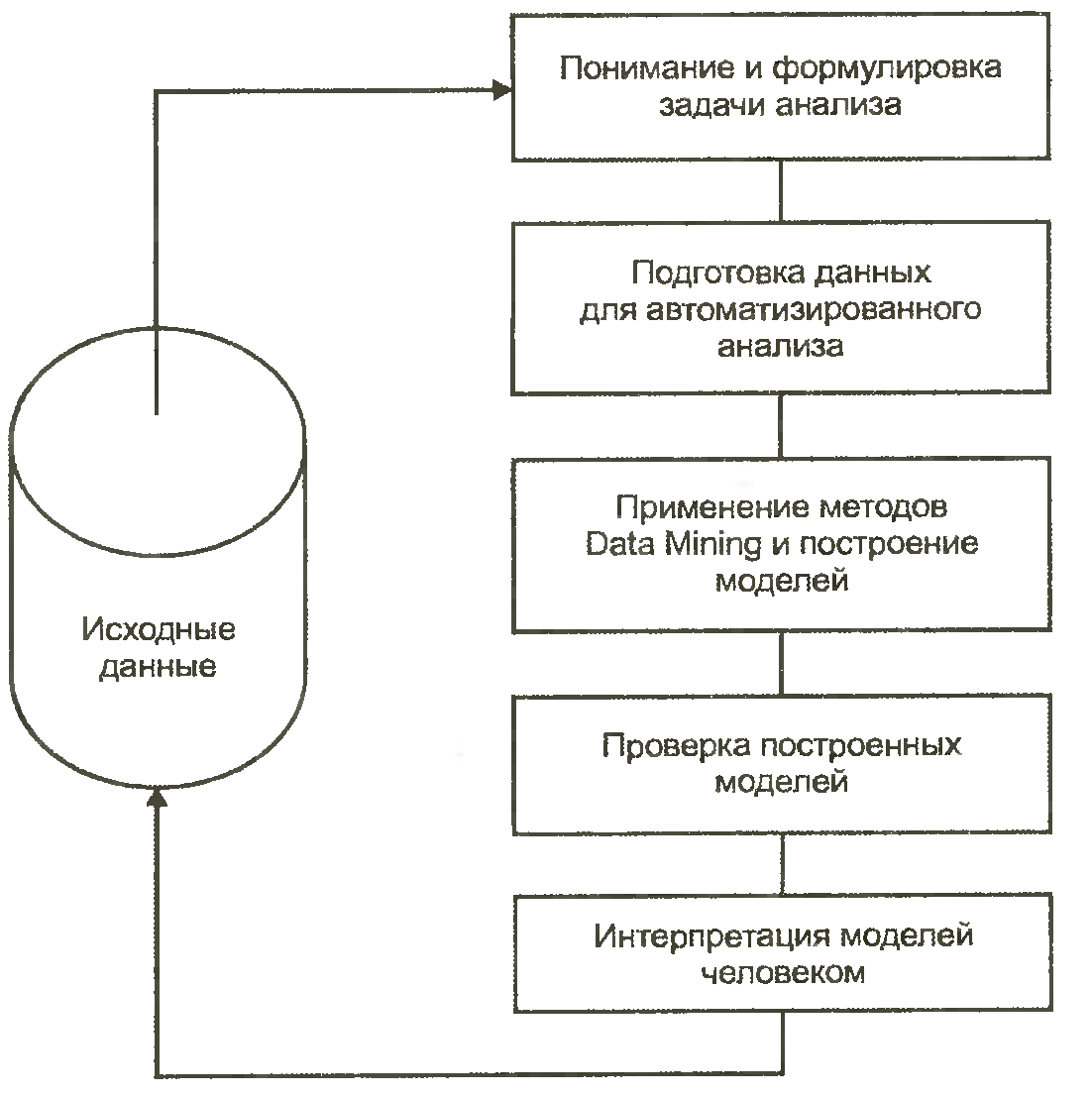
Рисунок 1.1. Этапы интеллектуального анализа данных
В 1989 году Григорием Пятецким-Шапиро был введен термин Data Mining, который он определил как «процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности» [11].
Data Mining (рус. добыча данных, интеллектуальный анализ данных, глубинный анализ данных) - собирательное название, используемое для обозначения совокупности методов. Знания должны быть новые, ранее неизвестные. Затраченные усилия на открытие знаний, которые уже известны пользователю и, следовательно, не представляют для него ценность, не окупаются.
Знания должны быть нетривиальны. Результаты анализа должны отражать неочевидные, неожиданные закономерности в данных, составляющие, так называемые скрытые знания. Результаты, которые могли бы быть получены более простыми способами (например, визуальным просмотром), не оправдывают привлечение мощных методов Data Mining.
Знания должны быть практически полезны. Найденные знания должны быть применимы, в том числе и на новых данных, с достаточно высокой степенью достоверности. Полезность заключается в том, чтобы эти знания могли принести определенную выгоду при их применении.
Знания должны быть доступны для понимания человеку. Найденные закономерности должны быть логически объяснимы, в противном случае существует вероятность, что они являются случайными. Кроме того, обнаруженные знания должны быть представлены в понятном для человека виде [13].
Data Mining - это сочетание широкого математического инструментария (от классического статистического анализа до новых кибернетических методов) и последних достижений в сфере информационных технологий. В технологии Data Mining гармонично объединились строго формализованные методы и методы неформального анализа, т. е. количественный и качественный анализ данных [4].
В Data Mining для представления полученных знаний служат модели. Виды моделей зависят от методов их создания. Наиболее распространенными являются: правила, деревья решений, кластеры и математические функции.
К методам и алгоритмам Data Mining относятся следующие: искусственные нейронные сети, деревья решений, символьные правила, методы ближайшего соседа и k-ближайшего соседа, метод опорных векторов, байесовские сети, линейная регрессия, корреляционно-регрессионный анализ; иерархические методы кластерного анализа, неиерархические методы кластерного анализа, в том числе алгоритмы k-средних и k-медианы; методы поиска ассоциативных правил, в том числе алгоритм Apriori, метод ограниченного перебора, эволюционное программирование и генетические алгоритмы, разнообразные методы визуализации данных и множество других методов [11].
Большинство аналитических методов, используемые в технологии Data Mining это известные математические алгоритмы и методы. Новым в их применении является возможность их использования при решении тех или иных конкретных проблем, обусловленная появившимися возможностями технических и программных средств.
Метод (method) представляет собой норму или правило, определенный путь, способ, прием решений задачи теоретического, практического, познавательного, управленческого характера.
Понятие алгоритма появилось задолго до создания электронных вычислительных машин. Сейчас алгоритмы являются основой для решения многих прикладных и теоретических задач в различных сферах человеческой деятельности, в большинстве - это задачи, решение которых предусмотрено с использованием компьютера.
Алгоритм (algorithm) - точное предписание относительно последовательности действий (шагов), преобразующих исходные данные в искомый результат [4].
Классификация методов Data Mining
Все методы Data Mining подразделяются на две большие группы по принципу работы с исходными обучающими данными. В этой классификации верхний уровень определяется на основании того, сохраняются ли данные после Data Mining либо они дистиллируются для последующего использования.
1. Непосредственное использование данных, или сохранение данных.
В этом случае исходные данные хранятся в явном детализированном виде и непосредственно используются на стадиях прогностического моделирования и/или анализа исключений. Проблема этой группы методов - при их использовании могут возникнуть сложности анализа сверхбольших баз данных.
Методы этой группы: кластерный анализ, метод ближайшего соседа, метод k-ближайшего соседа, рассуждение по аналогии.
2. Выявление и использование формализованных закономерностей, или дистилляция шаблонов.
При технологии дистилляции шаблонов один образец (шаблон) информации извлекается из исходных данных и преобразуется в некие формальные конструкции, вид которых зависит от используемого метода Data Mining. Этот процесс выполняется на стадии свободного поиска, у первой же группы методов данная стадия в принципе отсутствует. На стадиях прогностического моделирования и анализа исключений используются результаты стадии свободного поиска, они значительно компактнее самих баз данных.
Методы этой группы: логические методы; методы визуализации; методы кросс-табуляции; методы, основанные на уравнениях.
Логические методы, или методы логической индукции, включают: нечеткие запросы и анализы; символьные правила; деревья решений; генетические алгоритмы.
Методы этой группы являются, пожалуй, наиболее интерпретируемыми - они оформляют найденные закономерности, в большинстве случаев, в достаточно прозрачном виде с точки зрения пользователя. Полученные правила могут включать непрерывные и дискретные переменные. Следует заметить, что деревья решений могут быть легко преобразованы в наборы символьных правил путем генерации одного правила по пути от корня дерева до его терминальной вершины. Деревья решений и правила фактически являются разными способами решения одной задачи и отличаются лишь по своим возможностям. Кроме того, реализация правил осуществляется более медленными алгоритмами, чем индукция деревьев решений.
Методы кросс-табуляции: агенты, баесовские (доверительные) сети, кросс-табличная визуализация. Последний метод не совсем отвечает одному из свойств Data Mining - самостоятельному поиску закономерностей аналитической системой. Однако, предоставление информации в виде кросс-таблиц обеспечивает реализацию основной задачи Data Mining - поиск шаблонов, поэтому этот метод можно также считать одним из методов Data Mining.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
